图像和视频压缩
本文内容来自于《视频编解码器设计-开发图像与视频压缩系统》第3.2节
#############################################################################
编码器:压缩信号的设备或程序(encoder)
解码器:解压缩的设备或程序(decoder)
一对编码器/解码器成为信号编解码器(CODEC)
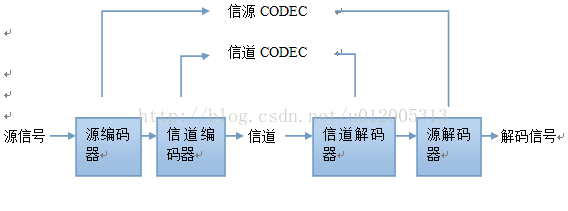
上图就是一个典型的例子
发送端:
信源编码:原始信号(未压缩信息)被编码(压缩)
信道编码:被编码的源信号在信道传输前进一步编码以增加纠错功能
接收端:
信道解码器检测或纠正传输中的错误,由信源解码器解压缩出源信号。
其中,解压缩的信号可能和源信号是一致的(无损压缩),或者在某种程度上失真和退化(有损压缩)
设计通用编解码器是依据信号中包含的统计冗余数据来实现压缩。一种携带信息的信号通常存在冗余,这意味着它在理论上可以用一种更紧凑的形式来表示。
用较短的编码表示经常出现的字符而用较长的编码表示不经常出现的字符,这使得文本文件得到压缩成为可能(应用,例:哈夫曼编码)。
压缩是通过减少统计冗余来实现的。这种类型的通用编解码器称为熵编解码器(entropy CODEC)
图片图像和视频流不一定都要用通用的编解码来压缩,它们的内容(像素值)具有较高的相关性,比如相邻的像素有近似的数值,但是熵编码器则是要求数据在一定程度上具有独立性(即不相关数据)的情况下进行压缩,其效果最好。
按我的理解,就是我们一般用的压缩工具类似好压、WinRAR等软件基于通用的熵编码,但是对于图像和视频的压缩上面这些压缩软件的算法并不有效,而基于JPEG、MEPG等算法的压缩软件X265、x264等有很好的效果
JPEG等算法在图像被压缩之前应用了一种信源模型。采用这个信源模型的目的是发掘出视频或图像数据的特性并把它表示成一种容易被熵编码器压缩的格式。下图描述了一个基本的图像或视频编编解码器的设计,它由信源模型和熵编/解码器组成:
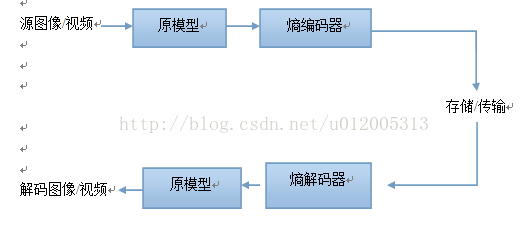
######################################################################################
信源模型
图像和视频信号有许多可以被信源模型利用的特性。在一副图像或一帧视频中相邻的样本点(像素)一般具有很高的相关性,因此具有很大的空间冗余度。
连续帧中的相邻区域往往具有很高的相关性(时域冗余,temporal redundancy)。
上述这些统计特性称为统计冗余(statistical redundancy)
信源模型还可能利用主观冗余(subjective redundancy),即利用人眼视觉系统对图像和视频的不同特点的敏感程度的不同,通过丢弃特定的主观冗余部分的信息来压缩图像:解码图像和原始图像不完全相同,但是从视觉角度看来信息的丢失并不明显。
图像和视频的信源模型的例子包括以下几种:
1.差分脉冲编码调制(DPCM)
差分脉冲编码调制是将每一个样本或像素可以用一个或多个前面传输的样本来预测。
最简单的预测是由前一个像素来形成,更精确的预测可以通过使用临近像素的加权平均来获得。
实现:用预测值减去实际的像素值X,并且把其差值(预测误差,the prediction error)传递给接收器。由于空间的相关性,预测误差一般会比较小。用短的二进制码表示常见的、小的预测误差,而用长的二进制吗表示不常见的、大的预测误差就可以实现压缩。
进一步的压缩可以通过量化预测误差和减少其精度来实现,因为不可能准确地在解码器上重新生成原始的码值,所以这是有损压缩。
差分脉冲编码调制可以用于空域(利用同一帧中相邻的像素)和(或者)时域(利用前一帧中相邻的像素进行预测),并且可以实现低复杂度下的适当压缩。
2.变换编码
原理:图像样本可以变换到另一个域(或者表达方式),并且用变换系数来表达。
在“空间域”(也就是图像的原始形式),样本具有很高的空间相关性。变换编码的目的就是为了减少这种相关性,理想情况下可以产生小部分的很重要的变换系数(它们对原始图像的质量很重要)和大部分不重要的变换系数(因为对图像的视觉质量没有很大的影响,可以被忽略)。
变换处理本身并不实现压缩,但通常在变换后接着进行一个有损的量化过程,在这个过程中不重要的系数被去除而留下小部分重要的系数。变换编码成为常用的图像和视频压缩系统的基础。

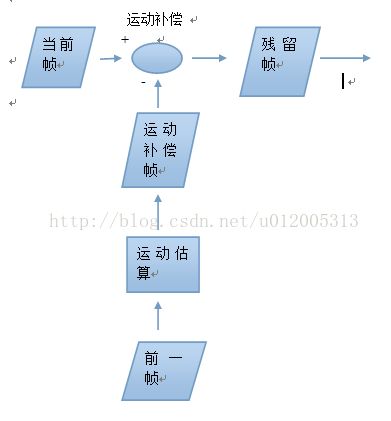
3.运动补偿预测
用类似脉冲编码调制的方法,编码器基于先前的帧的样本来形成当前帧的模型。通过变换(平移)和变形先前传输的参考帧,在视频序列中作“补偿”运动。当前帧减去得到的运动补偿预测帧(当前帧的模型)产生了一个残差“错误”帧。在运动补偿预测后进行进一步的编码,例:对残差帧进行变换编码。
4.基于模型的编码
基于模型编码的思想是通过创建一个视频场景的语义模型,例如可以通过分析和解释场景的内容来实现。
基于模型的编码具有比上面提到的其他信源压缩编码方法更大的潜力,但是实时分析和综合一个视频场景所需的计算复杂度是很高的