协同过滤介绍和简单推荐系统的实现
本文介绍推荐系统、协同过滤思想,两种基本的相似度衡量,并用python实现。最后就MovieLens数据集上作出简单的推荐。
一、相关知识
(1)推荐系统
如今,推荐系统已经在多方面得到应用,例如淘宝、当当、亚马逊等网站的商品推荐。而个性化推荐系统则是通过发掘用户的兴趣爱好,作出针对性的推荐。个性化推荐的方法较多,最常用的是协同过滤方法,而本文主要讲的也是基于协同过滤的个性化推荐。
(2)协同过滤
协同过滤技术出现于20世纪70年代,到90年代形成较为成熟的理论框架。协同过滤的基本假设是如果用户x和y对n个项目的评价或行为是相似的,那么他们对其他项目所持有的观点也是相似的,即行为相似的用户兴趣也可能相似。
一个协同过滤算法的基本方法是对大批用户进行搜索,从中找出兴趣相似的用户群。算法会对这些人的所偏爱的内容进行考察,然后构造出推荐列表,推荐给该群体的用户。
(3)Python语言
Python语言一种是一种面向对象的解释型语言,具有跨平台、简单实用、扩展性强等特性,数据结构也非常灵活。Python俗称胶水语言,其语法简洁,类库很多,适合快速开发程序。在做爬虫抓取数据和社交网络分析时学的,此处用的版本是python3.2。
二、相似度测量方法
主要有两种:欧几里得距离和皮尔逊相关度(pearson)
(1)数据集
Prefer以字典形式存放用户看过的电影和评分。
Prefer = {"tommy":{'War':2.3,'The lord of wings':3.0,'Kongfu':5.0},
"lily":{'War':2.0,'The lord of wings':3.6,'Kongfu':4.1},
"jim":{'War':1.9,'The lord of wings':4.0,'Beautiful America':4.7,'the big bang':1.0},
'jack':{'War':2.8,'The lord of wings':3.5,'Kongfu':5.5}
}
(2)、寻找有相似兴趣的用户,方式是比较各用户的评价数据,计算用户间的相似度。主要方法有2种即欧几里得距离和皮尔逊相关度。
2-1欧几里得距离
使用欧几里得距离计算用户的相似度时,将用户评价的物品作为坐标轴,用户填充到坐标体系中。以二维为例,
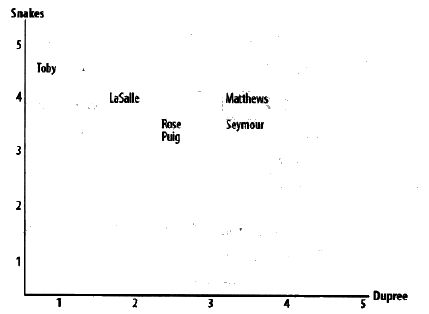
上图中,Snakes和Dupree为电影,Toby,Lasclle等人对应的点根据其评分情况被画在相应的位置。这样两者在偏好空间中的距离越近,他们的兴趣就越相似。而此模型可以推广至多维情况。
2-2 Pearson相关度评价
欧几里得距离评价法是一种比较简单的方法。但是由于存在一些用户总是倾向于评分过高或过低(相对平均值),这是兴趣相似的用户并不能通过此方法计算出来。Pearson相关系数是根据两组数据与某一直线的拟合程度来衡量的。

此坐标系以用户为坐标轴,用户所评分的电影显示在对应位置。本方法可修正结果,增强准确性。例如TOM, Lily对电影A,B,C的评分为(2, 4.1, 4), (3, 5, 5 ),则用pearson方法得到两者相似度仍然较高,而欧几里得距离法得到的相似度则偏低。实际上是用户Lily倾向于评分更高。
(3)、编程并测试
#---------------欧几里得空间距离方法---------------
设原先距离L,L越小,越相似。本处采用改进的测量方法:sim=1/L+1,sim越大,越相似
def sim_distance(prefer, person1, person2):
sim = {}
for item in prefer[person1]:
if item in prefer[person2]:
sim[item] = 1 #添加共同项到字典中
#无共同项,返回0
if len(sim)==0:
return 0
#计算所有共有项目的差值的平方和
sum_all = sum([pow(prefer[person1][item]-prefer[person2][item], 2)
for item in sim])
#返回改进的相似度函数
return 1/(1+sqrt(sum_all))
#测试
print("\n测试计算欧几里得距离的方法sim_distance()....")
print("sim_distance(dic,'lily','jim') = ",sim_distance(dic, 'lily', 'jim'))
print("sim_distance(dic,'tommy','jim') = ",sim_distance(dic, 'tommy', 'jim'))
print("sim_distance(dic,'tommy','lily') = ",sim_distance(dic, 'tommy', 'lily'))
print("sim_distance(dic,'tommy','jack') = ",sim_distance(dic, 'tommy', 'jack'))
"""
结果:
0.7080595631785951
0.4814560089181300
0.471143138585317
0.5358983848622454
"""
#-----------------------pearson相关度系数------------------------
def sim_pearson(prefer, person1, person2):
sim = {}
#查找双方都评价过的项
for item in prefer[person1]:
if item in prefer[person2]:
sim[item] = 1 #将相同项添加到字典sim中
#元素个数
n = len(sim)
if len(sim)==0:
return -1
# 所有偏好之和
sum1 = sum([prefer[person1][item] for item in sim]) #1.sum([1,4,5,,,]) 2.list的灵活生成方式!(Python灵活)
sum2 = sum([prefer[person2][item] for item in sim]) #!!!!写成person1,导致程序一直runtime error!!!!
#求平方和
sum1Sq = sum( [pow(prefer[person1][item] ,2) for item in sim] )
sum2Sq = sum( [pow(prefer[person2][item] ,2) for item in sim] )
#求乘积之和 ∑XiYi
sumMulti = sum([prefer[person1][item]*prefer[person2][item] for item in sim])
#Pearson系数计算 http://baike.baidu.com/view/3891263.htm,计算错误
#num1 = n*sumMulti - sum1*sum2 #分子
#num2 = sqrt(n*sum1Sq-pow(sum1,2))*sqrt(n*sum2Sq-pow(sum2,2))
num1 = sumMulti - (sum1*sum2/n)
num2 = sqrt( (sum1Sq-pow(sum1,2)/n)*(sum2Sq-pow(sum2,2)/n))
if num2==0:
return 0
return num1/num2
#测试
print("\n测试计算Pearson系数的方法sim_pearson()....")
print("sim_pearson(dic,'lily','jim') = ",sim_pearson(dic, 'lily', 'jim'))
print("sim_pearson(dic,'tommy','jim') = ",sim_pearson(dic, 'tommy', 'jim'))
print("sim_pearson(dic,'tommy','lily') = ",sim_pearson(dic, 'tommy', 'lily'))
print("sim_pearson(dic,'tommy','jack') = ",sim_pearson(dic, 'tommy', 'jack'))
"""
结果:
0.9999999999999991
0.9999999999999988
0.8446877845160871
0.9999999999999973 **[比较tommy和jack,皮尔逊系数和欧几里得距离差别很大,原因是jack一直评分偏高]**
"""
三、获取推荐列表
依然以上面的prefer数据集为基础,根据计算结果将兴趣相似的用户评分较高的电影推荐给用户。
(1)获取相似用户
#从用户评价字典中返回Top-K匹配者
#K,相似度函数 为可选参数
def topMatches(prefer, person, n=2, similarity=sim_pearson):
scores=[ (similarity(prefer,person,other),other) for other in prefer if other!=person ]
#对scores列表排序,从高到底
scores.sort()
scores.reverse()
return scores[0:n] #返回排序列表, 注意[0:n],仅返回前n项;
#测试
print("\n测试topMatches()方法......")
print(topMatches(dic, 'tommy'))
"""
结果:[(0.9999999999999988, 'jim'), (0.9999999999999973, 'jack')] (相似度,姓名)
"""
(2)、获取推荐
# 提供推荐,利用所有人评价的加权均值。 相似度高,影响因子越大。
def getRecommendations(prefer, person, similarity=sim_pearson):
totals = {}
simSums = {}
for other in prefer:
if other == person:
continue
else:
sim = similarity(prefer, person, other) #计算比较其他用户的相似度
#相似度>0
if sim<=0: continue
for item in prefer[other]:
if item not in prefer[person]:
#加权评价值:相似度*评价值
totals.setdefault(item,0) #每轮循环开始时初始化为0
totals[item] += prefer[other][item]*sim
#相似度之和
simSums.setdefault(item,0)
simSums[item] += sim
#建立归一化列表
ranks = [ (total/simSums[item],item) for item,total in totals.items() ]
#返回经排序后的列表
ranks.sort()
ranks.reverse()
return ranks
#测试
print("\n测试推荐方法getRecommendations(prefer, person, similarity=sim_pearson)......")
print(getRecommendations(dic, 'tommy'))
"""
结果: [(4.7, 'Beautiful America')]
"""
四、利用MovieLens公开数据集做推荐
(1)、文件一loadMovieLens.py,加载测试集数据
def loadMovieLens():
str1 = '/data/movielens/u.item'
#获取影片的id和标题(其他项类似)
movies = {}
for line in open(str1,'r'):
(id,title) = line.split('|')[0:2] #将返回列表的前2元素赋给元组
movies[id] = title
#print(movies[id]) [测试输出正常,但是遇到UnicodeEncodeError?]
# 加载数据
prefer = {}
for line in open('/data/movielens/u.data'):
(user, movieid, rating,ts) = line.split('\t') #数据集中每行有4项
prefer.setdefault(user, {}) #设置字典的默认格式,元素是user:{}字典
prefer[user][movies[movieid]] = float(rating)
# 返回字典:user以及评价过的电影
return prefer
(2)、文件二:recommendation.py 做推荐
和三中介绍的方法放置于同一文件recommendation.py下。
from loadMovieLens import loadMovieLens
print("\n-------------------MovieLens 测试数据集的推荐系统--------------------")
prefers = loadMovieLens()
print("\n1.*********基于用户的推荐**********\n")
print("用户87的评价列表为:",prefers['87'])
print("\n**********推荐影片*********\n")
tuijian = getRecommendations(prefers, '87')[0:20]
print(tuijian)
(3)利用MovieLens做测试是出现编码错误提示,后来发现时数据集中某行格式不规范,用软件打开u.item,修改下即可。
参考书籍:programing collective intelligence.
自己写的找不到了,这个还不错
http://blog.csdn.net/database_zbye/article/details/8664516