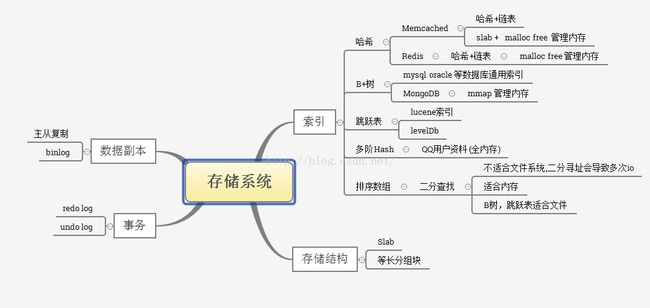
关于索引的思考
存储系统为了提高检索的效率,都会对需要检索的列进行索引,索引的数据结构有很多,如数据库常用的B+树(mysql oracle的常见索引),NoSql数据库中用到的Hash(memcache,redis),多阶Hash,跳跃表(lucence,levelDb)。排序数组。除Hash外,其他的索引结构所管理的key都是排序过的,特别是B+树,所有的叶子节点从左至右就是一个大大的排序数组,检索过程就是通过根节点不断找到范围包含key的叶节点,每次找到叶节点,比较时也是做二分查找,性能等价于在一个排序数组中做二分查找。问题来了,为嘛数据库不直接使用排序数组,非要弄个B+树,原来这都要归结到如何提高磁盘IO的效率,减少随机IO的次数.在机械磁盘中随机IO是个比较耗时的操作(我的《SSD的随机读能力》文章中有介绍),举个例子如果索引文件全部在磁盘文件中,索引文件有1G,里面是一个很长的排序组数(假设1亿条),如果做二分查找的话,那么查找次数就是Log2-100000000 ,大概是26次查找,因为这个文件很大,每次二分之后的文件地址在磁盘上的位置肯定大不同,那么每次都会伴随着一次随机IO,一个7200转的磁盘,随机io寻道时间大概5毫秒,一次查找就用去了130毫秒的寻道时间。这时候就体现了B+树的优势了,他的每一个子节点都是一块连续的key的集合,在磁盘种以顺序的方式存放。当从根节点查找时,找到下一层的子节点,每次都会把一个叶子节点的数据以顺序读的方式读到内存,只需一次随机IO和一次顺序IO,而随机后一个顺序IO读取一块数据是非常快的,然后再从这块连续的key中做二分查找,内存中这种操作时间相对于毫秒级的磁盘时间基本可以忽略,找到当前key所在范围的下一层子节点,直到找到这个key,而数据库在组织B+树的结构时,树的高度不会太高,一般四层。这样操作随机IO的次数就是4,其他的二分查找都是在内存里面。所以B树大大减少了随机IO的次数.从而提高了在磁盘文件上的检索速度.
所以如果索引文件全部在内存中的话,B树就毫无优势了,当插曲和删除时,他还得额外的去维护树的平衡。那么这个时候排序数组就是最好的方式了。
所以如果索引文件全部在内存中的话,B树就毫无优势了,当插曲和删除时,他还得额外的去维护树的平衡。那么这个时候排序数组就是最好的方式了。
下次再写个文章来分析下Hash索引的应用场景和特点。
下图是自己用Xmind梳理的存储体系和各种类型的索引.