孤立词语音识别之Vector Quantization(矢量量化)
1、Vector Quantization介绍
Vector Quantization(VQ)是一种基于块编码规则的有损数据压缩方法。在诸多领域有广泛应用,比如语音和图像编码或压缩,语音识别等领域。VQ 的 主要优点在于可以减少计算量和存储,缺点就是为了减少计算量和存储所付出的的代价,损失精度。
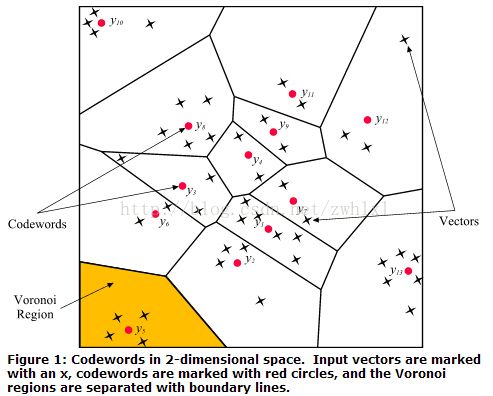
以二维向量为例,一个二维向量对应坐标上的一个点,所有二维向量的集合就构成了坐标平面。然后通过聚类算法将平面划分成N个区域,满足


如图所示,R代表整个特征空间,划分N个区域,每个区域称作Voronoi Region(包腔), 每个区域有个代表矢量,叫码字(Codewords)。所有码字(Codewords)的集合称作码本(Codebook)。N称为码本的长度或容量。
2、Vector Quantization 在孤立词语音识别的应用
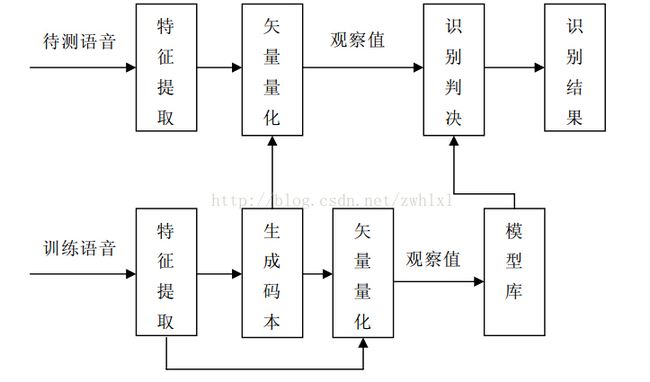
由于后续采用基于DHMM(离散隐马尔科夫)的孤立词识别,所以必须将语音特征参数MFCC向量序列转换成整数序列作为DHMM的观察序列。这个过程就是矢量量化。这样大大地减少了存储量和计算量。

3、Vector Quantization 最优码本的训练—LBG Algorithm
3.1 传统LBG Algorithm
Vector Quantization 最优码本的建立常用算法是K-means和LBG算法。LBG算法是由Linde、Buzo和Gray 三人在1980年提出。LBG算法核心思想通过训练矢量集和一定的迭代算法来逼近最优的再生码本。LBG算法过程描述如下:


标准的LBG算法C语言实现:
#include "stdio.h"
#include "math.h"
struct VQ_VECTOR
{
double* Data; //Input vector
int nDimension; //Dimension of input vector
int nCluster; //Class the vector belong to during clustering
//Value may changed every epoch
char* pFileName;
};
struct VQ_CENTER
{
double* Data; //Clustering center vector
int nDimension;//Dimension of center vector
int Num; //Number of vectors belong to the clustering
};
/******************************************************************************
/* Name: LBGCluster
/* Function: Clustering input vectors using LBG algorithm
/* Using Euclidean distance
/* Parameter: X -- Input vecters
/* N -- Number of input vectors
/* Y -- Clustering result
/* M -- Number of clustering center
/* Return: 0 -- Correct
/* 1 -- Error
/*
/******************************************************************************/
int LBGCluster(VQ_VECTOR *X, int N, VQ_CENTER *Y, int M)
{
if(N<M) return -1;
int L=1000, m=1, nCenter, i, j, k;//L,µü´úµÄ´ÎÊý
int nDimension = X[0].nDimension;
double D0, D;
struct VQ_CENTERINFO
{
double* Data;
int nDimension;
double* SumData;
int Num;
};
VQ_CENTERINFO *Center = (VQ_CENTERINFO*)malloc(M*sizeof(VQ_CENTERINFO));
if(Center == NULL) return -1;
double *Distance = (double*)malloc(N*sizeof(double));
if(Distance == NULL) return -1;
for( i=0; i<M; i++)
{
Center[i].nDimension = nDimension;
Center[i].Data = (double*)malloc(sizeof(double)*nDimension);
Center[i].SumData = (double*)malloc(sizeof(double)*nDimension);
if( Center[i].Data == NULL || Center[i].SumData == NULL )
{
AfxMessageBox( "Memory used up!" );
return -1;
}
for( j=0; j<nDimension; j++ )
{
Center[i].Data[j] = X[i*N/M].Data[j];
Center[i].SumData[j] = 0;
}
Center[i].Num = 0;
}
D0=1; D=1e+10;
while(m<L && fabs(D0-D)/D0>1e-5)
{
for(i=0; i<M; i++)
{
for( j=0; j<nDimension; j++ )
Center[i].SumData[j] = 0;
Center[i].Num = 0;
}
D0 = D; D = 0; m++;
for(i=0; i<N; i++)
{
Distance[i] = 1e+10;
for(int j=0; j<M; j++)
{
double Dist = 0;
for( k=0; k<nDimension; k++ )
Dist += (X[i].Data[k]-Center[j].Data[k])*(X[i].Data[k]-Center[j].Data[k]);
if( Dist < Distance[i])
{
nCenter = j;
Distance[i] = Dist;
}
}
X[i].nCluster = nCenter;
for( k=0; k<nDimension; k++ )
Center[nCenter].SumData[k] += X[i].Data[k];
Center[nCenter].Num++;
D += Distance[i];
}
for(i=0; i<M; i++)
{
if(Center[i].Num != 0)
for( k=0; k<nDimension; k++ )
Center[i].Data[k] = Center[i].SumData[k]/Center[i].Num;
else
{
int MaxNum=0;
for( k=1; k<M; k++)
MaxNum = Center[i].Num > Center[MaxNum].Num ? i: MaxNum;
int Num = Center[MaxNum].Num/2;
for( k=0; k<nDimension; k++ )
Center[MaxNum].SumData[k] = 0;
Center[MaxNum].Num = 0;
for(k=0; k<N; k++)
{
if(X[k].nCluster != MaxNum) continue;
if(Center[i].Num < Num)
{
X[k].nCluster = i;
for( m=0; m<nDimension; m++)
Center[i].SumData[m] += X[k].Data[m];
Center[i].Num++;
}
else
{
for( m=0; m<nDimension; m++ )
Center[MaxNum].SumData[m] += X[k].Data[m];
Center[MaxNum].Num++;
}
}
for( m=0; m<nDimension; m++ )
Center[i].Data[m] = Center[i].SumData[m] / Center[i].Num;
if(MaxNum < i)
for( m=0; m<nDimension; m++ )
Center[MaxNum].Data[m] = Center[MaxNum].SumData[m] / Center[MaxNum].Num;
}
}
}
for(i=0; i<M; i++)
{
for( m=0; m<nDimension; m++ )
Y[i].Data[m] = Center[i].Data[m];
Y[i].Num = Center[i].Num;
}
for( i=0; i<M; i++ )
{
free( Center[i].Data );
free( Center[i].SumData );
}
free(Center);
free(Distance);
return 0;
}
3.2 二元分裂 LBG Algorithm
二元分裂法具体算法如下:
1、给定训练集T。固定ɛ(失真阈值)为一个很小的正数。
2、让N=1(码矢数量),将这一个码矢设置为所有训练样本的平均值:

计算总失真度(这时候的总失真很明显是最大的):

3、分裂:对i=1,2,…,N,他们的码矢分别为:

让N=2N,就是每个码矢分裂(乘以扰乱系数1+ɛ和1-ɛ)为两个,这种每一次分裂后的码矢数量就是前一次的两倍。
4、迭代:让初始失真度为:![]() 。将迭代索引或者迭代计数器置零i=0.
。将迭代索引或者迭代计数器置零i=0.
1)对于训练集T中的每一个训练样本m=1,2,…,M。在所有码矢中寻找的![]() 最小值,也就是看这个训练样本和哪个码矢距离最近。我们用n*记录这个最小值的索引。然后用这个码矢来近似这个训练样本:
最小值,也就是看这个训练样本和哪个码矢距离最近。我们用n*记录这个最小值的索引。然后用这个码矢来近似这个训练样本:
![]() 。
。
2)对于n=1,2,…,N,通过以下方式更新所有码矢:

也就是将所有属于cn所在的编码区域Sn的训练样本取平均作为这个编码区域的新的码矢。
3)检测是否有空包腔。
4)迭代计数器加1:i=i+1.
5)计算在现阶段的C和P基础上的总失真度:

6)如果失真度相比上一次的失真度(相对失真改进量)还大于可以接受的失真阈值ɛ(如果是小于就表明再进行迭代运算失真得减小是有限的以停止迭代运算了),那么继续迭代,返回步骤1)。
![]()
7)否则最终失真度为![]() 。对n=1,2,…,N,最终码矢为:
。对n=1,2,…,N,最终码矢为:![]()
5、重复步骤3和4至到码矢的数目达到要求的个数。
二元分裂LBG算法C语言代码实现:
/*==========================================================================
Production of Vector Codebook based on LBG Method
C language program : LBG.cpp
Li Wei 06/01/2006
===========================================================================*/
/* read from wlee.hex write to test.hex */
#include<iostream>
#include<fstream>
#include<math.h>
#include <stdlib.h>
#include <stdio.h>
using namespace std;
const int LEN=100; //训练序列长度
const int TEST=15; //测试序列长度
const int DIMENSION=7; //矢量维数
const int CODESIZE=16; //码本个数
const char* filename = "train";
int LoadPatterns(char * fname,float **input)
{
FILE *InFilePtr;
int i, j, NumPatterns, SizeVector, NumClusters;
double x;
if ((InFilePtr = fopen(fname, "r")) == NULL)
printf("读文件错误\n");
fscanf(InFilePtr, "%d", &NumPatterns); // Read # of patterns
fscanf(InFilePtr, "%d", &SizeVector); // Read dimension of vector
fscanf(InFilePtr, "%d", &NumClusters); // Read # of clusters for K-Means
for (i = 0; i < NumPatterns; i++)
{ // For each vector
for (j = 0; j < SizeVector; j++)
{ // create a pattern
fscanf(InFilePtr, "%lg", &x); // consisting of all elements
input[i][j] = x; //何处定义?
//printf("%f ", input[i][j]);
} /* endfor */
//printf("\n");
} /* endfor */
return 0;
}
int main(int argc, char *argv[])
{
//FILE *ff;
//if (ff = fopen("1.txt", "r"))
FILE *fp,*fout;
float input[TEST+LEN][DIMENSION]; //读入的序列
float **in; //读入的序列
in = new float *[TEST + LEN];
for (int i = 0; i < (TEST + LEN); i++)
in[i] = new float[DIMENSION];
float train_x[LEN][DIMENSION]; //输入矢量 训练序列
float test[TEST][DIMENSION],test1[TEST][DIMENSION]; //测试序列
float outtest[TEST*DIMENSION];
float codebook[CODESIZE][DIMENSION]={0}; //输出的码字
float distance[CODESIZE]; //距离误差
int train_code[LEN]; //训练序列第i个矢量与生成码书中的哪个码字最近
int test_code[TEST]; //测试序列第i个矢量与生成码书中的哪个码字最近
int label; //标号,隶属哪个码本
int codebooksize[CODESIZE]; //表示每个胞腔的大小
float d1=1,d2=1; //计算误差用
float nd; //相对误差
float min=80000; //最小距离
int i,j,k; //做循环时用的标号
int time,suptime; //生成初始码书的次数
int power=1; //每次生成码本的个数
float temp; //临时替换变量
int n;
float e=0.01; //设定循环结束的相对误差
int max=0,max_label=0; //去除空胞腔时使用
/* fp=fopen("train_data.txt","rb"); //从f:\\wlee.hex中读入数据
if((fout=fopen("test.txt","wb"))==NULL) //量化后的测试数据存放到f:\\test.hex
{
cout<<"error!"<<endl;
exit(0);
}
if(fp==NULL)
cout<<"It is an error"<<endl;
fread(input,sizeof(float),(TEST+LEN)*DIMENSION,fp);
*/
if ((fout = fopen("test.hex", "wb")) == NULL) //量化后的测试数据存放到f:\\test.hex
{
cout << "error!" << endl;
exit(0);
}
LoadPatterns("train_data.txt", in);
for(i=0;i<LEN;i++) //读入训练数据
for(j=0;j<DIMENSION;j++)
train_x[i][j] = in[i][j];
//读入完毕
for(i=0;i<TEST;i++) //读入测试序列
for(j=0;j<DIMENSION;j++)
test[i][j]=in[i+LEN][j];
for(i=0;i<LEN;i++)
for(j=0;j<DIMENSION;j++)
codebook[0][j]=codebook[0][j]+train_x[i][j];
for(j=0;j<DIMENSION;j++)
codebook[0][j]=codebook[0][j]/LEN;
/*=========================生成初始码书===================================*/
time=CODESIZE;
suptime=0;
while(time!=1) //寻找需要循环的次数
{
time=time/2;
suptime++;
}
for(time=1;time<=suptime;time++)
{
for(i=0;i<power;i++) //temp是中间替换量
for(j=0;j<DIMENSION;j++) //码本分裂
{
temp=codebook[i][j];
codebook[i][j]=1.01*temp;
codebook[i+power][j]=0.99*temp;
}
power=power*2;
n=1;
nd=1;
d2=8000;
while(nd>e)
{
if(n!=1) //保证了第一次读入的数据不被处理掉
{
for(i=0;i<power;i++)
for(j=0;j<DIMENSION;j++)
codebook[i][j]=0;
for(i=0;i<power;i++)
codebooksize[i]=0;
/*============================生成质心================================*/
for(j=0;j<power;j++)
{
for(i=0;i<LEN;i++)
{
if(train_code[i]==j)
{
for(k=0;k<DIMENSION;k++)
codebook[j][k]=codebook[j][k]+train_x[i][k];
codebooksize[j]=codebooksize[j]+1;
}
}
if(codebooksize[j]!=0)
for(k=0;k<DIMENSION;k++)
codebook[j][k]=codebook[j][k]/codebooksize[j];
}
/*============================去除空胞腔================================*/
for(j=0;j<power;j++)
{
if(codebooksize[j]==0)
{
max=codebooksize[0];
for(i=0;i<power;i++)
{
if(codebooksize[i]>max)
{
max=codebooksize[i];
max_label=i;
}
}
for(k=0;k<DIMENSION;k++)
{
codebook[j][k]=0.98*codebook[max_label][k];
codebook[max_label][k]=1.02*codebook[max_label][k];
}
if(max%2==0)
{
codebooksize[j]=max/2;
codebooksize[max_label]=max/2;
}
else
{
codebooksize[j]=(max+1)/2;
codebooksize[max_label]=(max-1)/2;
}
}
}
}
/*=============================计算误差==================================*/
for(i=0;i<power;i++)
distance[i]=0;
for(i=0;i<LEN;i++)
train_code[i]=0;
for(i=0;i<LEN;i++)
{
for(j=0;j<power;j++)
for(k=0;k<DIMENSION;k++)
distance[j]=(train_x[i][k]-codebook[j][k])*(train_x[i][k]-codebook[j][k]);
train_code[i]=0;
for(j=0;j<power;j++)
{
if(distance[j]<min)
{
min=distance[j]; //表示j项于x[i]距离最近
train_code[i]=j;
}
}
min=80000;
}
d1=d2;
d2=0.0;
for(i=0;i<LEN;i++)
{
label=train_code[i];
for(k=0;k<DIMENSION;k++)
d2=d2+(train_x[i][k]-codebook[label][k])*(train_x[i][k]-codebook[label][k]);
}
d2=d2/LEN;
nd=(d1-d2)/d2;
nd=fabs(nd);
n=n+1;
}
}
for(i=0;i<CODESIZE;i++) //输出生成的码本
{
cout << "codebook[" << i << "]: ";
for(j=0;j<DIMENSION;j++)
cout<<codebook[i][j]<<" ";
cout<<endl;
}
cout<<endl;
/*========================将测试数据进行量化============================*/
for(i=0;i<TEST;i++) //保存原始测试序列
for(j=0;j<DIMENSION;j++)
test1[i][j]=test[i][j];
for(i=0;i<TEST;i++)
{
for(j=0;j<CODESIZE;j++)
{
distance[j]=0;
for(k=0;k<DIMENSION;k++)
distance[j]=(test[i][k]-codebook[j][k])*(test[i][k]-codebook[j][k]);
if(distance[j]<min)
{
min=distance[j];
label=j;
test_code[i]=j;
}
}
for(k=0;k<DIMENSION;k++)
test[i][k]=codebook[label][k];
min=80000;
}
distance[0]=0;
for(i=0;i<TEST;i++) //计算经量化后测试序列的总误差并输出
{
label=test_code[i];
for(k=0;k<DIMENSION;k++)
distance[0]+=(test1[i][k]-codebook[label][k])*(test1[i][k]-codebook[label][k]);
}
cout<<distance[0]<<endl;
k=0;
for(i=0;i<TEST;i++) //变成一维向量,便于输出到文件
for(j=0;j<DIMENSION;j++)
outtest[k++]=test[i][j];
fwrite(outtest,sizeof(float),TEST*DIMENSION,fout);//输出
//fclose(fp);
fclose(fout);
system("pause");
return(0);
}
/*=====================程序结束===============================*/
3.3 模拟退火 LBG Algorithm
模拟退火算法简介( 转载自http://www.cnblogs.com/heaad/archive/2010/12/20/1911614.html#!comments)
爬山算法 ( Hill Climbing )
介绍模拟退火前,先介绍爬山算法。爬山算法是一种简单的贪心搜索算法,该算法每次从当前解的临近解空间中选择一个最优解作为当前解,直到达到一个局部最优解。
爬山算法实现很简单,其主要缺点是会陷入局部最优解,而不一定能搜索到全局最优解。如图1所示:假设C点为当前解,爬山算法搜索到A点这个局部最优解就会停止搜索,因为在A点无论向那个方向小幅度移动都不能得到更优的解。

图1
模拟退火(SA,Simulated Annealing)思想
爬山法是完完全全的贪心法,每次都鼠目寸光的选择一个当前最优解,因此只能搜索到局部的最优值。模拟退火其实也是一种贪心算法,但是它的搜索过程引入了随机因素。模拟退火算法以一定的概率来接受一个比当前解要差的解,因此有可能会跳出这个局部的最优解,达到全局的最优解。以图1为例,模拟退火算法在搜索到局部最优解A后,会以一定的概率接受到E的移动。也许经过几次这样的不是局部最优的移动后会到达D点,于是就跳出了局部最大值A。
模拟退火算法描述:
若J( Y(i+1) )>= J( Y(i) ) (即移动后得到更优解),则总是接受该移动
若J( Y(i+1) )< J( Y(i) ) (即移动后的解比当前解要差),则以一定的概率接受移动,而且这个概率随着时间推移逐渐降低(逐渐降低才能趋向稳定)
这里的“一定的概率”的计算参考了金属冶炼的退火过程,这也是模拟退火算法名称的由来。
根据热力学的原理,在温度为T时,出现能量差为dE的降温的概率为P(dE),表示为:
P(dE) = exp( dE/(kT) )
其中k是一个常数,exp表示自然指数,且dE<0。这条公式说白了就是:温度越高,出现一次能量差为dE的降温的概率就越大;温度越低,则出现降温的概率就越小。又由于dE总是小于0(否则就不叫退火了),因此dE/kT < 0 ,所以P(dE)的函数取值范围是(0,1) 。
随着温度T的降低,P(dE)会逐渐降低。
我们将一次向较差解的移动看做一次温度跳变过程,我们以概率P(dE)来接受这样的移动。
关于爬山算法与模拟退火,有一个有趣的比喻:
爬山算法:兔子朝着比现在高的地方跳去。它找到了不远处的最高山峰。但是这座山不一定是珠穆朗玛峰。这就是爬山算法,它不能保证局部最优值就是全局最优值。
模拟退火:兔子喝醉了。它随机地跳了很长时间。这期间,它可能走向高处,也可能踏入平地。但是,它渐渐清醒了并朝最高方向跳去。这就是模拟退火。
模拟退火算法是一种随机算法,并不一定能找到全局的最优解,可以比较快的找到问题的近似最优解。 如果参数设置得当,模拟退火算法搜索效率比穷举法要高。
模拟退火算法流程
1、随机产生一个初始解x0,令x best = x 0 ,并计算目标函数值E(x0 );
2、设置初始温度T(0)=To ,迭代次数i= 1;
3、 Do whileT(i) >T min
1) forj= 1~k
2)对当前最优解x best按照某一邻域函数,产生一新的解x new。计算新的目标函数值E(xnew ),并计算目标函数值的增量ΔE=E(xnew) -E(x best )。
3)如果ΔE<0,则xbest=x new ;
4)如果ΔE>0,则p= exp(-ΔE/T(i));
1)如果c= random[0,1] <p,xbest=x new; 否则x best=xbest。
5) End for
4、i=i+ 1;
5、End Do
6、输出当前最优点,计算结束
模拟退火LBG Algorithm 建立码本的方法是在外层迭代上使用模拟退火算法来控制迭代次数,从而尽可能达到最优,内层使用LBG算法实现码本的建立。
4、特征参数量化
在语音识别系统中,一帧语音经过量化之后,与失真测度最小的码字Yi匹配,并且把该帧语音标记为Oi ,且
Oi = i 。T帧语音矢量量化后则组成了观察符号序列O= [O1, O2, O3,…, Ot],如图所示,待识别的语音矢量是在变成了一组观察值序列,送入系统中的HMM识别功能模块。
采用传统量化方式时,每个语音特征向量只对应一个码字标号,例如, 特征向量X对应标号i,i 指出码字Yi在码本中所处的位置。在计算失真测度时发现,向量X与码字Yj的相似性也非常高,Yi和Yj分别对应的失真测度之间差别极小,也就是说,向量X处于码字Yi和Yj所在胞腔的临界位置,此时,如果只用单个标号来对应向量 ,将丢失一部分特征信息,量化不够精确。
采用模糊量化的方式弥补这一缺陷。这种方法是在原来量化的基础 上进行双参数模糊量化。 设输入矢量为X ,某一码本为Y = [Y1, Y2, Y3,…,YM,],M为码本中码字数。用欧氏距离计算出X 与其最近邻的两个码字Yi和Yj,所得欧氏距离分别为Di与Dj ,其中Di < Dj,对应的观察值分别为i 和j,欧式距离越小,说明矢量和码字矢量越靠近,相似性就越大,所占的比例应该越高。设比例分别为Pi和Pj
Pi = Dj /(Di + Dj)
Pj = Di /(Di + Dj)
量化后矢量 X 可以用{(i, Pi),(j, Pj)} 表示。量化产生的观察值用于模型库的训练或者进入识别模块参与识别。无论应用于训练模型还是用于识别,观察值序列主要应用于隐马尔可夫模型概率分布函数B 中。该函数表示,在i状态,观察值为Oi时的概率为B[i][Oi]。经过模糊量化 后,则原来的概率函数表示为B[i][Oi] = B[i][Oi] *Pi + B[j][Oj] * Pj
参考资料
1、http://www.cnblogs.com/heaad/archive/2010/12/20/1911614.html#!comments
2、 http://blog.csdn.net/zouxy09/article/details/9153255