CUDA最佳实践
转自:http://blog.csdn.net/csgxy123/article/details/9569201
近期开始学习CUDA编程,需要阅读很多资料,为了便于整理复习,特将阅读笔记记录,以备后用。
这一系列文章是根据NVIDIA公司官方文档《CUDA C Best Practices》的内容来进行整理的,由于笔者刚开始进行CUDA的学习,而并行语言的学习不如串行语言如C、C++那样容易入门,因此理解错误之处在所难免,欢迎读到错误的各位批评指正。
1. 学习目的
CUDA是一个C语言的扩充,学习它的目的是利用CUDA将程序中的可并行部分交由GPU来完成,以达到CPU与GPU协同工作的效果,极大提升程序性能。
2. 优化过程
学习CUDA的一个非常有用的作用在于程序员可以对现有的C/C++程序进行改写,将其中适合在GPU上运行的并行部分代码挖掘出来,改写代码使得它们可以在GPU上运行,从而极大地提升程序的运算性能。将串行代码转化为并行代码的过程是迭代的,简单来说,每一次迭代可以划分为4个相对独立的过程:
1、分析(Assess)
2、并行化(Parallelize)
3、优化(Optimize)
4、部署(Deploy)
这四个过程合起来称作APOD,CUDA为每个过程提供了解决方案以改善程序性能。APOD是一个循环的过程:对程序进行初步分析并行优化后,可以继续运用上述手段,分析程序中的可并行化段,利用CUDA对该段代码进行改写,优化改写的程序,最后将改写后的代码部署到原有程序中。这一过程可以形象地用下图来进行表示:
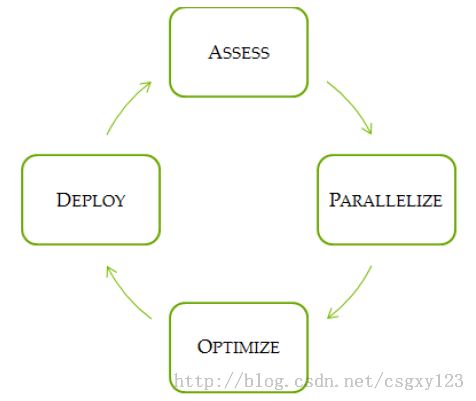
并行化过程是使用CUDA对原有C/C++程序进行初步改写,CUDA提供了众多的并行库供程序员调用,例如cuBLAS、cuFFT以及Thrust等,除此之外,还可以运用一些预处理指令来优化编译器的行为。
优化是对并行化后的程序重复进行APOD的过程,以使程序达到更好的性能。
在部署阶段,程序员需要比较改写后与改写前程序运算的结果,以验证改写的正确性。验证完毕后,将改写程序加入到原有项目当中。
分析过程主要是找出程序性能提升的极限,找出它们的方法是运用所谓的Amdahl定理和Gustafson定理,这两个定理随后将会提到。
3. 异构计算
异构计算是指运用多种不同架构的处理器来完成计算任务,使用CUDA,我们可以协调CPU和GPU,让它们分工合作以达到计算的目的。
在CUDA中,CPU用主机(Host)来表示,GPU则用设备(Device)来表示。主机和设备之间是有一些区别的,这些区别的主要部分集中在线程模型和物理内存方面:
线程资源(Threading resources)
CPU所支持的同时运行的线程数是极其有限的,一个拥有4个6核心处理器的服务器处理器在同一时刻只能同时运行24个线程(注意是同一时刻!),而现代NVIDIA GPU则可以支持同一时刻数千个活动线程同时运行。
线程(Threads)
在CPU中线程切换由于涉及到上下文(Context)的改变,代价很大。与之相比,GPU中的线程则非常轻巧,切换几乎没有代价。简言之,CPU的设计初衷是为了最小化线程切换的延迟,而GPU的设计理念是为了处理大量同时运行的轻量级线程以最大化吞吐量。
内存(RAM)
主机和设备都拥有各自的物理内存,它们之间通过PCI-E总线来交换信息。为了使用CUDA,数据必须通过PCI-E总线从主机传输到设备上。传输的开销是非常可观的,因此,为了获得更好的性能表现,数据重用是非常重要的。简单来说,数据应当尽可能久地保存在设备上以备运算所用。
4. 性能分析
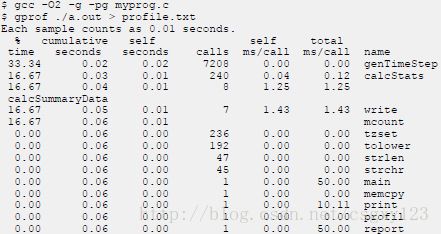
在很多项目中,完成了绝大多数工作任务的是相对较少的一部分核心代码。使用性能分析器,开发人员可以识别这样的热点代码,找到瓶颈,进而有针对性地对代码进行优化。性能分析的工具非常多,典型的工具如gprof便是其中之一,它是一款Linux平台上的开源性能分析器。下面则是其分析结果的部分截图:
4.1 强标度与Amdahl定律(Strong Scaling and Amdahl's Law)
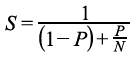
4.2 弱标度与Gustafson定律(Weak Scaling and Gustafson's Law)
5. 得到正解
得到正确的计算结果是我们的最初目的,但是使用CUDA这种并行编程模型是很容易出错的,这时我们就需要一些方法和工具来帮助我们验证计算结果的正确性,同时,在CUDA编程中也有一些值得我们注意的问题。
5.1 正确性验证
正确性验证主要有两种方法:
1、引用比较(Reference Comparison)
引用比较的核心思想是使用未并行化代码产生的一些具有代表性的结果与并行化后的程序运行结果,当它们的绝对差在可接受范围内时,就认为并行化的结果是正确的。注意,改写前和改写后代码运行结果的不一致是由浮点数表示的不确切性造成的。
第一步完成后,我们使用APOD(Assess、Parallelize、Optimize、Deployment)过程对并行化代码实施进一步优化,我们只要保证每一步优化的引用比较结果正确,那么对于最终的并行化程序,其结果的正确性是可以得到保证的。
2、单元测试(Unit Testing)
单元测试与引用比较的方法是相辅相成的。单元测试是指开发人员在编写代码时就将项目代码组织成单元级别,然后运用一定的技术手段对各个单元分别测试其正确性。在CUDA中,我们可以把内核(kernels)写成一系列小的__device__函数的组合而不是将代码封装到一个庞大的__global__函数中。这样,我们就可以在连接各部分代码之前对各个设备(device)代码进行单独测试。
5.2 调试(Debugging)
调试CUDA需要一些特别的工具:
1. CUDA-GDB
CUDA-GDB是Linux和Mac环境中GNU调试器的一个端口(Port),具体信息参见:GNU-GDB
2. NVIDIA Parallel Nsight
NVIDIA Parallel Nsight调试和性能分析器是可以在Windows环境下作为Microsoft Visual Studio的插件使用,具体参见:NVIDIA Parallel Nsight
3. 一些第三方调试工具
一些第三方工具也支持CUDA的调试,具体参见:Debugging solutions
5.3 数值精度问题
由于CUDA使用的是浮点数进行运算,涉及到一些精确度问题,需要我们在编程时注意一下。
1、单精度与双精度问题
单精度和双精度浮点运算的结果差别是很大的,在CUDA中,只有运算能力大于或等于1.3的硬件才能本地支持双精度运算。执行运算时,程序员务必搞清进行的是哪一种运算以获得正确的结果。nvcc编译命令行中使用-arch=sm_13可开启双精度运算。
2、浮点运算不遵从结合律
对于三个浮点数A、B以及C,需要注意的是,(A+B)+C并不等于A+(B+C)。
3、双精度扩展和单精度截断
由于单精度浮点数和双精度浮点数运算结果的不一致性,CUDA程序员应注意避免一些精度细节问题,如下面这段代码:
- float a;
- a = a * 1.02;
在C语言中,1.02会被隐含解释为double类型,那么第二个式子右边的a将会被扩展为双精度浮点数而执行double乘法,得到的结果为双精度浮点数,最后再将这一结果截断为单精度浮点数赋值给式子左边的a。这会带来隐患,解决这一问题的方法是用1.02f来表示单精度浮点常数。
6. 性能度量(Performance Metrics)
为了优化CUDA程序的性能,我们需要一种定量的方法来对程序性能进行衡量,同时,我们也需要明晰带宽(bandwidth)在性能衡量中所扮演的角色。下面我们将依依介绍这些概念。
6.1 定时
CUDA调用和内核执行可以使用CPU和GPU定时器来计时,使用这些计时器需要注意相关的问题:
1、使用CPU定时器
使用CPU定时器需要注意很多CUDA API函数是异步的,即这些函数在任务完成之前就会把控制权返回给CPU。它们一般都会在函数名之前带有Async,遇到这类函数时需要特别小心。为了达到精准定时的效果,我们需要同步CPU和GPU,这可以通过在开始和停止定时器前调用函数cudaDeviceSynchronize()来实现。cudaDeviceSynchronize()阻塞当前CPU线程,直到指定流(Stream)中所有之前的CUDA调用运行完毕之后CPU线程才开始继续执行。类似地,CPU线程也可以与GPU流或者GPU事件进行同步,使用cudaStreamSynchronize()函数或者cudaEventSynchronize()函数可以达到这样的效果。然而需要注意的是,上述两个函数不适合在默认流以外的其他流中使用,因为驱动程序可能安排不同流中的代码交错运行,这样就会造成计时错误。而默认流(Stream 0)在设备上表现为串行运行,因此可以使用上面两个函数进行计时。
2、使用CUDA GPU定时器
CUDA event API提供了用于创建和消除以及记录事件(使用timestamp)的调用函数,通过timestamp之间的差值换算,我们可以得到毫秒级的GPU运行时间信息。下面的代码片段展示了这一技术:
How to time code using CUDA events
- cudaEvent_t start, stop;
- float time;
- cudaEventCreate(&start);
- cudaEventCreate(&stop);
- cudaEventRecord(start, 0);
- kernel<<<grid, threads>>>(d_odata, d_idata, size_x, size_y, NUM_REPS);
- cudaEventRecord(stop, 0);
- cudaEventSynchronize(stop);
- cudaEventElapsedTime(&time, start, stop);
- cudaEventDestroy(start);
- cudaEventDestroy(stop);