Accelerated C++:通过示例进行编程实践——练习解答(第5章)
5-0. Compile, execute, and test the programs in this chapter.
a、根据学生成绩及格与否进行分类,及格、不及格分别存储。
//classify the students by grades
//fgrade(vector<Student_info>& s),classify students into two parts,fail and pass;file be placed in grade.h/.cpp
bool fgrade(vector<Student_info>& s)
{
return grade(s)<60;
}
//1.store by two new vector:fail and pass;this function was placed in Student_info.h/.cpp
vector<Student_info> extract_fails(vector<Student_info>& s)
{
vector<Student_info> fail,pass;
typedef vector<Student_info>::size_type size_tp;
size_tp size=s.size();
for(int i=0;i<size;++i)
{
if(fgrade(s[i]))
fail.push_back(s[i]);
else
pass.push_back(s[i]);
}
s=pass;
return fail;
}
//2.use one new vector to store fail students,pass still in old vector;this function was placed in Student_info.h/.cpp
vector<Student_info> extract_fails(vector<Student_info>& s)
{
vector<Student_info> fail,pass;
typedef vector<Student_info>::size_type size_tp;
for(size_tp i=0;i<s.size();)
{
if(fgrade(s[i]))
{
fail.push_back(s[i]);
i=s.erase(s.begin()+i);
}
else
++i;
}
return fail;
}
//3.use the iterator instead the index;file still be placed in Student_info.h/.cpp
vector<Student_info> extract_fails(vector<Student_info>& s)
{
vector<Student_info> fail;
for(vector<Student_info>::iterator it=s.begin();it!=s.end();)
{
if(fgrade(it))
{
fail.push_back(*it);
it=s.erase(it);
}
else
++it;
}
return fail;
}
//4.new data Structure--list to improve the efficiency
list<Student_info> extract_fails(list<Student_info>& s)
{
list<Student_info> fail;
for(list<Student_info>::iterator it=s.begin();it!=s.end();)
{
if(fgrade(it))
{
fail.push_back(*it);
it=s.erase(it);
}
else
++it;
}
return fail;
}
b、字符串连接
this is an **************
example * this is an *
to * to *
illustrate * illustrate *
framing * framing *
**************
//str_join.h #ifndef str_join_H #define str_join_H #include <string> #include <vector> std::string::size_type width(const std::vector<std::string>& v); std::vector<std::string> frame(const std::vector<std::string>& v); std::vector<std::string> hcat(const std::vector<std::string>& left,const std::vector<std::string>& right); #endif
//str_join.cpp
#include "str_join.h"
#include <iostream>
using namespace std;
string::size_type width(const vector<string>& v)
{
string::size_type maxlen=0;
for(vector<string>::const_iterator it=v.begin();
it!=v.end();++it)
{
string::size_type size=(*it).size();
if(maxlen<size)
maxlen=size;
}
return maxlen;
}
vector<string> frame(const vector<string>& v)
{
vector<string> ret;
string::size_type sz=width(v);
string border(sz+4,'*');
ret.push_back(border);
for(vector<string>::const_iterator it=v.begin();
it!=v.end();++it)
{
ret.push_back("* "+*it+string(sz-(*it).size(),' ')+" *");
}
ret.push_back(border);
return ret;
}
vector<string> hcat(const vector<string>& left,const vector<string>& right)
{
vector<string> ret;
string::size_type wt=width(left)+1;
vector<string>::size_type i=0,j=0;
while(i!=left.size()||j!=right.size())
{
string s;
if(i!=left.size())
s=left[i++];
s+=string(wt-s.size(),' ');
if(j!=right.size())
s+=right[j++];
ret.push_back(s);
}
return ret;
}
//main.cpp
#include "str_join.h"
#include <iostream>
using namespace std;
int main()
{
string str;
vector<string> vec;
vector<string> vec_f;
vector<string> vec_j;
while(getline(cin,str))
vec.push_back(str);
vec_f=frame(vec);
vec_j=hcat(vec,vec_f);
for(vector<string>::const_iterator it=vec_j.begin();
it!=vec_j.end();++it)
{
cout<<endl<<*it<<endl;
}
return 0;
}lyj@qt:~/Desktop/vm/bin/Debug$ ./vm
this is an
example
to
illustrate
framing
this is an **************
example * this is an *
to * example *
illustrate * to *
framing * illustrate *
* framing *
**************
lyj@qt:~/Desktop$
c、字符串分裂split
#include <iostream>
#include <string>
#include <vector>
#include <cctype>
using namespace std;
vector<string> split(const string& s)
{
vector<string> ret;
string::size_type size=s.size(),i=0,j;
while(i!=size)
{
while(i!=size && isspace(s[i]))++i;
j=i;
while(j!=size && !isspace(s[j]))++j;
if(j!=i)
{
ret.push_back(s.substr(i,j-i));
i=j;
}
}
return ret;
}
int main()
{
string str;
vector<string> vec;
while(getline(cin,str))
vec=split(str);
for(vector<string>::const_iterator it=vec.begin();
it!=vec.end();++it)
cout<<*it<<endl;
return 0;
}lyj@qt:~/Desktop$ ./split
This is an example to illustrate the string split!
This
is
an
example
to
illustrate
the
string
split!
lyj@qt:~/Desktop$
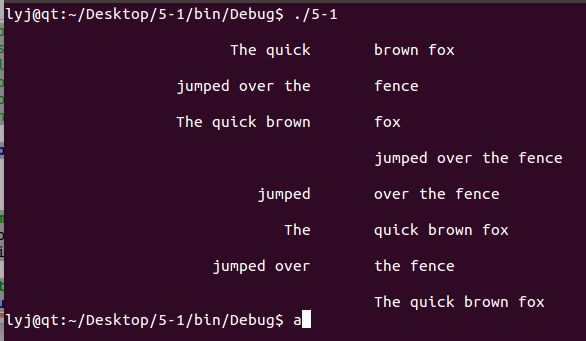
5-1. Design and implement a program to produce a permuted index. A permuted index is one in which each phrase is indexed by every word in the phrase. So, given the following input,
The quick brown fox jumped over the fence
the output would be
The quick brown fox
jumped over the fence
The quick brown fox
jumped over the fence
jumped over the fence
The quick brown fox
jumped over the fence
The quick brown fox
A good algorithm is suggested in The AWK Programming Language by Aho, Kernighan, and Weinberger (Addison-Wesley, 1988). That solution divides the problem into three steps:
- Read each line of the input and generate a set of rotations of that line. Each rotation puts the next word of the input in the first position and rotates the previous first word to the end of the phrase. So the output of this phase for the first line of our input would be
Of course, it will be important to know where the original phrase ends and where the rotated beginning begins.
The quick brown fox quick brown fox The brown fox The quick fox The quick brown
- Sort the rotations.
- Unrotate and write the permuted index, which involves finding the separator, putting the phrase back together, and writing it properly formatted.
Ans:Permuted index(置换索引),算法思想如下:



tips:对以下文件进行简单的功能介绍:
split文件:进行字符串分裂,以便进行短语轮转;
compare文件:sort(begin,end,谓词)的第三个参数谓词,因为短语中忽略大小写;
rotation文件:进行各个短语的轮转,轮转后的集合存储在容器中(本题该轮转集合有八个,故容器有8个string);
unrotation文件:当然在调用该unrotation函数之前,需要多rotation()之后的轮转集合进行sort(),反向轮转过程如上图3所示;
//split.h #ifndef split_H #define split_H #include <vector> #include <string> std::vector<std::string> split(const std::string& s); #endif // split_H
//split.cpp
#include "split.h"
#include <cctype>
using namespace std;
vector<string> split(const string& s)
{
vector<string> lt;
string s1;
typedef string::size_type size_tp;
size_tp size=s.size();
size_tp i=0,j=0;
while(i<size)
{
while(isspace(s[i])) ++i;
j=i;
while(!isspace(s[j])) ++j;
if(i!=j)
{
lt.push_back(s.substr(i,j-i));
}
i=j;
}
return lt;
}
//compare.h #ifndef compare_H #define compare_H #include <string> bool comparef(const std::string x,const std::string y); #endif // compare_H
//compare.cpp
#include "compare.h"
#include<cctype>
using namespace std;
#include <iostream>
bool comparef(const string x,const string y)
{
typedef string::size_type size_tp;
size_tp xsize=x.size(),ysize=y.size();
size_tp i=0,j=0;
string xx=x,yy=y;
for(;i<xsize;++i)
{
if(isupper(xx[i]))
xx[i]+=32;
}
for(;j<ysize;++j)
{
if(isupper(yy[j]))
yy[j]+=32;
}
return xx<yy;
}
//found.h #ifndef found_H #define found_H #include <string> std::string::size_type found(const std::string& s,std::string& k1,std::string& k2,std::string& key); #endif // found_H
//found.cpp
#include "found.h"
using namespace std;
string::size_type found(const string& s,string& k1,string& k2,string& key)
{
typedef string::size_type size_tp;
size_tp f1,f2;
f1=s.find(k1);//string.find(key),没有找到,则返回string所能表示的最大值
f2=s.find(k2);
if(f1<f2)
{
key=k1;
return f1;
}
if(f2<f1)
{
key=k2;
return f2;
}
}
//rotation.h #ifndef rotation_H #define rotation_H #include <vector> #include <string> std::vector<std::string> rotation(const std::vector<std::string>& v); #endif // rotation_H
//rotation.cpp
#include "rotation.h"
#include "split.h"
using namespace std;
//produce the rotations of each phase
vector<string> rotation(const vector<string>& v)
{
vector<string> rot;
for(vector<string>::const_iterator it=v.begin();it!=v.end();++it)
{
vector<string> vs;//待求轮转集合的短语
vs=split(*it);//origin phrase
typedef vector<string>::size_type size_tp;
size_tp size=vs.size();
size_tp k=0;//按短语所含单词数,进行循环轮转,求出该短语的所有轮转集合
vector<string> vrot;//待求轮转集合的短语vs的副本
vrot=vs;
while(k<size)//求一条短语的所有轮专集合rot
{
//将vector的元素连接成一个string,并存储于rot中
string s;
for(vector<string>::const_iterator j=vrot.begin();j!=vrot.end();++j)
{
s=s+' '+*j;
}
rot.push_back(s);
//对vs的副本vrot,进行轮转
//由于每次轮转都在前一次基础之上进行,故此处temp为临时轮转的一个短语
//轮转后下次被轮转对象为temp,即vrot=temp;
vector<string> temp;
vector<string>::iterator q=vrot.begin(),p;
for(p=q+1;p!=vrot.end();++p)
{
temp.push_back(*p);
}
temp.push_back(*q);
vrot=temp;
++k;
}
}
return rot;
}
//unrotation.h #ifndef unrotation_H #define unrotation_H #include <vector> #include <string> #include "found.h" std::vector<std::string> unrotation(const std::vector<std::string>& v); #endif // unrotation_H
//unrotation.cpp
#include "unrotation.h"
#include <iostream>
using namespace std;
vector<string> unrotation(const vector<string>& v)
{
vector<string> unrot;
typedef string::size_type size_tp;
string k1="fox";
string k2="fence";
for(vector<string>::const_iterator it=v.begin();it!=v.end();++it)
{
string key,s,s1,left,right;
string str=*it;
size_tp i,m,n;
i=found(str,k1,k2,key);
m=key.size();
n=str.size();
//right
right=str.substr(0,m+i);
//left
if(i==n)
s1.assign(n,' ');
else
s1.assign(n-m+i,' ');
left=s1+str.substr(i+m,n-m-i);
s=left+"\t"+right;
unrot.push_back(s);
}
return unrot;
}
//main.cpp
#include <iostream>
#include <fstream>
#include <algorithm>
#include "compare.h"
#include "rotation.h"
#include "unrotation.h"
using namespace std;
int main()
{
ifstream infile;
infile.open("/home/lyj/Desktop/5-1/in.txt",ios::in);
if(!infile.good())
{
cout<<"file open error!";
return -1;
}
string s;
vector<string> v;
while(getline(infile,s))
v.push_back(s);//按行存储短语
v=rotation(v);//vr存储两行短语的轮转集合
/*
for(vector<string>::const_iterator it=vr.begin();it!=vr.end();++it)
{
cout<<endl<<*it<<endl;
}
*/
sort(v.begin(),v.end(),comparef);//对轮转集合进行排序
/*
for(vector<string>::const_iterator it=v.begin();it!=v.end();++it)
{
cout<<endl<<*it<<endl;
}
*/
//反向轮转,分隔,连接
v=unrotation(v);
//最终输出
for(vector<string>::const_iterator it=v.begin();it!=v.end();++it)
{
cout<<endl<<*it<<endl;
}
return 0;
}
5-2. Write the complete new version of the student-grading program, which extracts records for failing students, usingvectors. Write another that useslists. Measure the performance difference on input files of ten lines, 1,000 lines, and 10,000 lines.
a、使用vector容器
//median.h #ifndef median_H #define median_H #include <vector> double median(std::vector<double> hw); #endif // median_H
//median.cpp
#include "median.h"
#include <algorithm>
using namespace std;
double median(vector<double> hw)
{
typedef vector<double>::size_type size_tp;
size_tp size=hw.size();
size_tp mid=size/2;
sort(hw.begin(),hw.end());
return size%2?(hw[mid-1]+hw[mid])/2:hw[mid];
}
//Student_info.h
#ifndef Student_info_H
#define Student_info_H
#include <string>
#include <vector>
class Student_info
{
public:
std::string name;
double midterm,fin;
std::vector<double> homework;
};
#endif // Student_info_H
//grade.h #ifndef grade_H #define grade_H #include "Student_info.h" double grade(double midterm,double fin,double homework); double grade(double midterm,double fin,const std::vector<double>& hw); double grade(const Student_info& s); bool fgrade(const Student_info& s); #endif // grade_H
//grade.cpp
#include "grade.h"
#include "median.h"
double grade(double midterm,double fin,double homework)
{
return 0.2*midterm+0.4*fin+0.4*homework;
}
double grade(double midterm,double fin,const std::vector<double>& hw)
{
return grade(midterm,fin,median(hw));
}
double grade(const Student_info& s)
{
return grade(s.midterm,s.fin,s.homework);
}
bool fgrade(const Student_info& s)
{
return grade(s)<60;
}
//extract_fails.h #ifndef extract_fails_H #define extract_fails_H #include <vector> std::vector<Student_info> extract_fails(std::vector<Student_info>& s); #endif // extract_fails_H
//extract_fails.cpp
#include "Student_info.h"
#include "grade.h"
using namespace std;
vector<Student_info> extract_fails(vector<Student_info>& s)
{
vector<Student_info> fail;
for(vector<Student_info>::iterator it=s.begin();it!=s.end();)
{
if(fgrade(*it))
{
fail.push_back(*it);
it=s.erase(it);
}
else
++it;
}
return fail;
}
//main.cpp
#include <iostream>
#include "Student_info.h"
#include "grade.h"
#include "extract_fails.h"
#include <fstream>
#include <cstdlib>
#include <cstring>
#include <time.h>
using namespace std;
int main()
{
//read file
ifstream infile;
infile.open("/home/lyj/Desktop/5-2/1.txt",ios::in);
if(!infile.good())
{
cout<<"file open error!"<<endl;
return 1;
}
vector<Student_info> vec;
//cout<<"here1"<<endl;
while(!infile.eof())
{
Student_info st;
infile>>st.name>>st.midterm>>st.fin;
double hw;
for(int i=0;i<3;++i)
{
infile>>hw;
st.homework.push_back(hw);
}
vec.push_back(st);
}
infile.close();
//cout<<"here2"<<endl;
vector<Student_info> fail;
clock_t start,finish;
start=clock();
fail=extract_fails(vec);
finish=clock();
long double t=double(finish-start)/CLOCKS_PER_SEC;
cout<<endl<<t<<"s"<<endl;
/*
cout<<"here3"<<endl;
for(vector<Student_info>::iterator iter=fail.begin();iter!=fail.end();++iter)
{
cout<<(*iter).name<<endl;
}
*/
return 0;
}
//学生成绩记录文件1.txt tianya 99 98 97 98 99 xiao 95 94 90 89 88 zhang 89 90 78 89 88 wang 99 92 91 92 93 zas 20 10 20 30 49 dc 30 40 50 60 90 ad 10 1 2 3 5 tianya 99 98 97 98 99 xiao 95 94 90 89 88 xiao 95 94 90 89 88向量容器vector,运行时间如下:
10行 0.000035s
1000行 0.0449863s
10000行 3.165763s
b、使用list容器
》list容器不支持随机访问只能顺序的访问,即不支持索引操作,不支持迭代器的算术运算,只支持迭代器的前置和后置的++、--、==、!=运算;
》list容器删除元素只会使指向被删除的元素的迭代器失效;
》list容器sort操作,与vector不同,list<double> stu; stu.sort(compare); 没有迭代器范围,且需要指定比较谓词;
将Student_info.h/cpp、grade.h/cpp、extract_fails.h/cpp、median.h、main.cpp的vector替换为list;因为,将median.cpp修改如下:
#include "median.h"
#include <algorithm>
using namespace std;
double median(list<double> hw)
{
list<double>::iterator it;
list<double>::size_type size=hw.size()/2+1;
int k=0;
hw.sort();
for(list<double>::iterator it=hw.begin();it!=hw.end();++it)
{
k++;
if(k==size && k%2!=0)
return *it;
else if(k==size && k%2==0)
return ( *(it)+*(--it) )/2;
}
}用list容器运行时间如下:
10行 0.000054s
1000行 0.004772s
10000行 0.043197s
结论:比较两个时间记录表,可知当需要处理的数据较少时两者效率差别不大,但当处理大量数据时list的效率就体现出来了,其效率将比vector容器高的多。
5-3. By using a typedef, we can write one version of the program that implements either avector-based solution or alist-based one. Write and test this version of the program.
Ans:利用typedef vector/list TYPE,用TYPE进行替换即可。
5-4. Look again at the driver functions you wrote in the previous exercise. Note that it is possible to write a driver that differs only in the declaration of the type for the data structure that holds the input file. If yourvector andlist test drivers differ in any other way, rewrite them so that they differ only in this declaration.
Ans:可以看出5-2使用vector和list编写的程序是有区别的,那就是计算家庭作业成绩的中值算法。因为list容器不支持随机访问,仅支持迭代器的前置和后置的++、--操作,故要编写一样的驱动程序,则需要修改vector程序的median.cpp实现部分即可。对vector实现算法的median.cpp的修改如下:
#include "median.h"
#include <algorithm>
using namespace std;
double median(vector<double> hw)
{
vector<double>::iterator it;
vector<double>::size_type size=hw.size()/2+1;
int k=0;
hw.sort();
for(vector<double>::iterator it=hw.begin();it!=hw.end();++it)
{
k++;
if(k==size && k%2!=0)
return *it;
else if(k==size && k%2==0)
return ( *(it)+*(--it) )/2;
}
}
5-5. Write a function named center(const vector<string>&) that returns a picture in which all the lines of the original picture are padded out to their full width, and the padding is as evenly divided as possible between the left and right sides of the picture. What are the properties of pictures for which such a function is useful? How can you tell whether a given picture has those properties?
Ans:根据题意要求返图案实际上是一个近似对称图案。说近似图案是因为:
》当每行字符数都为基数或者偶数时,返回图案是中间对称的;
》否则,即当最长行大小与每行相减所得为基数时,两边是不肯均匀填充的,故左右两边会相差一个填充字符;
//new.h实现center()函数 #ifndef new_H #define new_H #include <string> #include <vector> std::string::size_type maxlen(const std::vector<std::string>& vec); std::vector<std::string> center(const std::vector<std::string>& vec); #endif // new_H
//new.cpp
#include "new.h"
using namespace std;
typedef string::size_type size_tp;
string::size_type maxlen(const vector<string>& vec)
{
size_tp maxlen=0;
for(vector<string>::size_type i=0;i<vec.size();++i)
{
size_tp n=vec[i].size();
maxlen=maxlen<n?n:maxlen;
}
return maxlen;
}
vector<string> center(const vector<string>& vec)
{
size_tp width=maxlen(vec);
vector<string> new_vec;
for(vector<string>::size_type i=0;i<vec.size();++i)
{
size_tp size=width-vec[i].size();
size_tp mid=size/2;
string str;
if(size%2==0)
{
string star(mid,'*');
str=star+vec[i]+star;
new_vec.push_back(str);
}
else
{
str=string(mid,'*')+vec[i]+string(mid+1,'*');
new_vec.push_back(str);
}
}
return new_vec;
}
<pre name="code" class="cpp">//main.cpp
#include <iostream>
#include <fstream>
#include "new.h"
using namespace std;
int main()
{
//读取文件
ifstream infile;
infile.open("/home/lyj/Desktop/5-5/old.txt",ios::in);
if(!infile.good())
{
cout<<"open error!"<<endl;
return -1;
}
vector<string> old_vec,new_vec;
string line;
while(getline(infile,line))
{
old_vec.push_back(line);
}
infile.close()
//调用center,返回新图案
new_vec=center(old_vec);
//写文件
ofstream outfile;
outfile.open("/home/lyj/Desktop/5-5/new.txt",ios::out);
if(!outfile.good())
return -1;
for(vector<string>::const_iterator it=new_vec.begin();it!=new_vec.end();++it)
{
outfile<<*it<<'\n';
}
outfile.close();
}
//old.txt this is an exercises answer. to help people to better master the C++ language. have good time!
//运行后,在该目录产生新的文本文件new.txt,如下:(不清楚csdn编辑器的格式怎么回事,粘贴后显示不太正确)*******this is an exercises*******
************answer. to************
***********help people************
to better master the C++ language.
*********have good time!**********
5-6. Rewrite the extract_fails function from §5.1.1/77 so that instead of erasing each failing student from the input vectorv, it copies the records for the passing students to the beginning ofv, and then uses the resize function to remove the extra elements from the end ofv. How does the performance of this version compare with the one in §5.1.1/77?
//student_info.h
#ifndef Student_info_H
#define Student_info_H
#include <string>
#include <vector>
class Student_info
{
public:
std::string name;
double midterm,fin;
std::vector<double> homework;
};
#endif // Student_info_H
//grade.h #ifndef grade_H #define grade_H #include "Student_info.h" double grade(double midterm,double fin,double homework); double grade(double midterm,double fin,const std::vector<double>& hw); double grade(const Student_info& s); bool fgrade(const Student_info& s); #endif // grade_H
//grade.cpp
#include "grade.h"
#include "median.h"
double grade(double midterm,double fin,double homework)
{
return 0.2*midterm+0.4*fin+0.4*homework;
}
double grade(double midterm,double fin,const std::vector<double>& hw)
{
return grade(midterm,fin,median(hw));
}
double grade(const Student_info& s)
{
return grade(s.midterm,s.fin,s.homework);
}
bool fgrade(const Student_info& s)
{
return grade(s)<60;
}
//median.h #ifndef median_H #define median_H #include <vector> double median(std::vector<double> hw); #endif // median_H
//median.cpp
#include "median.h"
#include <algorithm>
using namespace std;
double median(vector<double> hw)
{
typedef vector<double>::size_type size_tp;
size_tp size=hw.size();
size_tp mid=size/2;
sort(hw.begin(),hw.end());
return size%2==0?(hw[mid]+hw[mid+1])/2:hw[mid];
}
//extract_fails.h #ifndef extract_fails_H #define extract_fails_H #include <vector> int extract_fails(std::vector<Student_info>& s); #endif // extract_fails_H
//extract_fails.cpp
#include "Student_info.h"
#include "extract_fails.h"
#include "grade.h"
using namespace std;
int extract_fails(vector<Student_info>& s)
{
vector<Student_info> fail;
for(vector<Student_info>::iterator it=s.begin();it!=s.end();++it)
{
if(fgrade(*it))
{
fail.push_back(*it);
//it=s.erase(it);
}
}
s.insert(s.begin(),fail.begin(),fail.end());
s.resize(fail.size());
return 0;
}
//main.cpp
#include <iostream>
#include "Student_info.h"
#include "grade.h"
#include "extract_fails.h"
#include <fstream>
#include <cstdlib>
#include <cstring>
#include <time.h>
using namespace std;
int main()
{
//read file
ifstream infile;
infile.open("/home/lyj/Desktop/5/5-2/1.txt",ios::in);
if(!infile.good())
{
cout<<"file open error!"<<endl;
return 1;
}
vector<Student_info> vec;
while(!infile.eof())
{
Student_info st;
infile>>st.name>>st.midterm>>st.fin;
double hw;
for(int i=0;i<3;++i)
{
infile>>hw;
st.homework.push_back(hw);
}
vec.push_back(st);
}
infile.close();
/* for(vector<Student_info>::iterator iter=vec.begin();iter!=vec.end();++iter)
{
cout<<(*iter).name<<endl;
}*/
clock_t start,finish;
start=clock();
extract_fails(vec);
finish=clock();
long double t=double(finish-start)/CLOCKS_PER_SEC;
cout<<endl<<t<<"s"<<endl;
return 0;
}运行结果如下表:
10行 0.000038s
1000行 0.002769s
10000行 0.008818s
比较练习5-2的结果可知,此版本性能高于list,即resize()版>list版>vector版。
5-7. Given the implementation of frame in §5.8.1/93, and the following code fragment
vector<string> v; frame(v);
describe what happens in this call. In particular, trace through how both thewidth function and the frame function operate. Now, run this code. If the results differ from your expectations, first understand why your expectations and the program differ, and then change one to match the other.
Ans:参见本练习题5-0的第二部分代码:“b、字符串连接”。
5-8. In the hcat function from §5.8.3/95, what would happen if we defineds outside the scope of thewhile? Rewrite and execute the program to confirm your hypothesis.
Ans:如果在while之外定义string s,每次循环后该string s并不会被销毁,故每次循环都会在前次的已有string s基础上进行连接;
但是s+=string(wt-s.size(),' ');又string::size_type wt=width(left)+1;即wt是left中最长字符串长度,大小固定,而当每次循环时string s是累加连接的故导致wt<s.size(),故提示如下错误:
terminate called after throwing an instance of 'std::length_error' what(): basic_string::_S_create Aborted (core dumped)程序如下:
//str_join.h #ifndef str_join_H #define str_join_H #include <string> #include <vector> std::string::size_type width(const std::vector<std::string>& v); std::vector<std::string> frame(const std::vector<std::string>& v); std::vector<std::string> hcat(const std::vector<std::string>& left,const std::vector<std::string>& right); #endif
//str_join.cpp
#include "str_join.h"
#include <iostream>
using namespace std;
string::size_type width(const vector<string>& v)
{
string::size_type maxlen=0;
for(vector<string>::const_iterator it=v.begin();
it!=v.end();++it)
{
string::size_type size=(*it).size();
if(maxlen<size)
maxlen=size;
}
return maxlen;
}
vector<string> frame(const vector<string>& v)
{
vector<string> ret;
string::size_type sz=width(v);
string border(sz+4,'*');
ret.push_back(border);
for(vector<string>::const_iterator it=v.begin();
it!=v.end();++it)
{
ret.push_back("* "+*it+string(sz-(*it).size(),' ')+" *");
}
ret.push_back(border);
return ret;
}
vector<string> hcat(const vector<string>& left,const vector<string>& right)
{
vector<string> ret;
string::size_type wt=width(left)+1;
vector<string>::size_type i=0,j=0;
string s;
while(i!=left.size()||j!=right.size())
{
//string s;
if(i!=left.size())
s=left[i++];
s+=string(wt-s.size(),' ');
if(j!=right.size())
s+=right[j++];
ret.push_back(s);
}
return ret;
}
//main.cpp
#include "str_join.h"
#include <iostream>
using namespace std;
int main()
{
string str;
vector<string> vec;
vector<string> vec_f;
vector<string> vec_j;
while(getline(cin,str))
vec.push_back(str);
vec_f=frame(vec);
vec_j=hcat(vec,vec_f);
for(vector<string>::const_iterator it=vec_j.begin();
it!=vec_j.end();++it)
{
cout<<endl<<*it<<endl;
}
return 0;
}
5-9. Write a program to write the lowercase words in the input followed by the uppercase words.
Ans:思路首先从文件逐个读取单词存储于一个string中,但是没有一个现成的接口来进行单词大小写判断,故利用<cctype>中的isupper()和islower()来对单词每个字符进行判断,若所有单词字符都是大写则将其存入容器vector<string> upper中,若不全是大写则存储在容器vector<string> lower中。程序实现如下:
我们的文本文件内容如下: this Is a test to test the PROGRAMME I AM A 123 student of the 789 USTC and SICT today's weather is very COLD she is a beautiful girl , and IN her school she is in the 1st . 123woed WORD!@# abc123 ABC789
//main.cpp
#include <iostream>
#include <fstream>
#include <vector>
#include <cctype>
using namespace std;
int main()
{
ifstream infile;
infile.open("/home/lyj/Desktop/5-9/1.txt",ios::in);
if(!infile.good())
{
cout<<"open error!";
return -1;
}
vector<string> upper,lower;
while(!infile.eof())
{
string word;
infile>>word;
typedef string::size_type size_tp;
size_tp size=word.size();
size_tp u=0,l=0;
for(size_tp i=0;i<size;++i)
{
if(isalpha(word[i]) && isupper(word[i]))
++u;
else if(isalpha(word[i]) && islower(word[i]))
++l;
}
if(u==size)
upper.push_back(word);
else if(l==size)
lower.push_back(word);
}
for(vector<string>::const_iterator it=upper.begin();it!=upper.end();++it)
{
cout<<*it<<" ";
}
cout<<endl;
for(vector<string>::const_iterator it=lower.begin();it!=lower.end();++it)
{
cout<<*it<<" ";
}
cout<<endl;
return 0;
}
输出如下: lyj@qt:~/Desktop/5-9/bin/Debug$ ./5-9 PROGRAMME I AM A USTC SICT COLD IN this a test to test the student of the and weather is very she is a beautiful girl and her school she is in the
5-10. Palindromes are words that are spelled the same right to left as left to right. Write a program to find all the palindromes in a dictionary. Next, find the longest palindrome.
Ans:用is_pslindrome()判断一个单词是否为回文,同时注意文本中最长回文不止一个,故当判断具有相同最长长度的回文时需要将其保存。
文本文件内容: abcba aabaa ccbcc this is a very goog , for palindrome test there are many wrong words in this txt. did done do , aha I can't list any more.
//palindrome.h #ifndef palindrome_H #define palindrome_H #include <string> bool is_palindrome(const std::string& s); #endif // palindrome_H
//palindrome.cpp
#include "palindrome.h"
using namespace std;
bool is_palindrome(const string& s)
{
typedef string::size_type size_tp;
size_tp i,j=s.size()-1;
for(i=0;i!=j;++i,--j)
{
if(s[i]!=s[j])
return false;
}
return true;
}
//main.cpp
#include <iostream>
#include <fstream>
#include <vector>
#include "palindrome.h"
using namespace std;
int main()
{
ifstream infile;
infile.open("/home/lyj/Desktop/5-10/1.txt",ios::in);
if(!infile.good())
{
cout<<"open failed!";
return -1;
}
string word;
vector<string> palind;
while(!infile.eof())
{
infile>>word;
if(is_palindrome(word))
palind.push_back(word);
}
infile.close();
typedef vector<string>::size_type size_tp;
typedef vector<string>::iterator iter_type;
iter_type it=palind.begin();
vector<iter_type> maxit;
size_tp maxlen=(*it).size();
for(;it!=palind.end();++it)
{
size_tp n=(*it).size();
if(maxlen<=n)
{
maxlen=n;
maxit.push_back(it);
}
cout<<*it<<" ";
}
cout<<endl<<"the longest palindrome is:"<<endl;
for(vector<iter_type>::const_iterator it=maxit.begin();it!=maxit.end();++it)
{
cout<<*(*it)<<" ";
}
cout<<endl;
return 0;
}
输出结果: abcba aabaa ccbcc a , did , aha I the longest palindrome is: abcba aabaa ccbcc
5-11. In text processing it is sometimes useful to know whether a word has any ascenders or descenders. Ascenders are the parts of lowercase letters that extend above the text line; in the English alphabet, the letters b, d, f, h, k, l, and t have ascenders. Similarly, the descenders are the parts of lowercase letters that descend below the line; In English, the letters g, j, p, q, and y have descenders. Write a program to determine whether a word has any ascenders or descenders. Extend that program to find the longest word in the dictionary that has neither ascenders nor descenders.
Ans:这里我们考虑扩展情况,因为扩展情况包含前述解决办法,首先利用函数is_updown(),判断一个单词对否为上行或下行单词。若是则将该单词存储于updown容器中;若不是上行或下行单词则将利用resize(),将其存储于原容器中。
文本文件内容: Today is a very cold day I found in my computer there is a Document. oh! it is to hard to list neither the up-word nor the down-word. aaaaaaaaaaa acee sssaazz is but not a meanningful words.
//updown.h #ifndef updown_H #define updown_H #include <string> bool is_updown(const std::string& word); #endif // updown_H
//updown.cpp
#include "updown.h"
using namespace std;
bool is_updown(const string& word)
{
typedef string::size_type size_tp;
size_tp size=word.size();
for(size_tp i=0;i<size;++i)
{
if(word[i]=='d' || word[i]=='f' || word[i]=='h' || word[i]=='k' || word[i]=='l' ||
word[i]=='t' || word[i]=='g' || word[i]=='j' || word[i]=='p' || word[i]=='q' || word[i]=='y')
return true;
}
return false;
}
//main.cpp
#include <iostream>
#include <fstream>
#include <vector>
#include "updown.h"
using namespace std;
int main()
{
ifstream infile;
infile.open("/home/lyj/Desktop/5-11/1.txt");
if(!infile.good())
{
cout<<"file open error!";
return -1;
}
//find it is a up or down word
string word;
vector<string> longest;
while(!infile.eof())
{
infile>>word;
if(!is_updown(word))
{
longest.push_back(word);
}
}
infile.close();
//the longest word
typedef string::size_type size_tp;
vector<string>::const_iterator it=longest.begin(),maxit=it;
size_tp maxlen=(*it).size();
for(it=it+1;it!=longest.end();++it)
{
size_tp n=(*it).size();
if(maxlen<=n)
{
maxlen=n;
maxit=it;
}
}
cout<<endl<<"the longest updown-word is: "<<*maxit<<" its size is: "<<maxlen<<endl;
return 0;
}
输出: the longest updown-word is: aaaaaaaaaaa its size is: 11