使用libcurl获取经过gzip压缩的网页文件
转自:http://blog.csdn.net/zengraoli/article/details/13623237
有些网页是经过gzip压缩的,如果直接从web获取网页的源代码后,得到的是一些乱码,比如“http://www.fenzhi.com/”这个网站的
你就是保存到本地,得到的数据,也是一个乱码的,当然用cout输出的也会是乱码;
下面我们封装一下libcurl(参考了网上的代码,加入了自己的一些属性)
看看封装后类:
get_web_data_from_url.h:
- #ifndef __GETPAGEBYURL_INCLUDE_H__
- #define __GETPAGEBYURL_INCLUDE_H__
- #include "curl.h"
- #include "string"
- #include "iostream"
- using namespace std;
- class GetWebDataFromUrl
- {
- public:
- GetWebDataFromUrl(void);
- public:
- ~GetWebDataFromUrl(void);
- private:
- static string web_data_;
- static CURL *curl_;
- private:
- static size_t WriteFunc(char *data, size_t size, size_t nmemb, string *writerData);
- public:
- static bool Initialize(string curlopt_proxy_ip = "", string curlopt_proxy_port = "");
- static bool GetPage(const string& urlStr, string& page);
- static void Cleanup();
- static void GetPageContent(string page_link, string &page_content);
- };
- #endif // !__GETPAGEBYURL_INCLUDE_H__
get_web_data_from_url.cpp:
- #include "StdAfx.h"
- #include "get_web_data_from_url.h"
- #define HAVE_LIBZ
- #define HAVE_ZLIB_H
- //static member variable define
- string GetWebDataFromUrl::web_data_ = "";//当前保存的网页源码
- CURL* GetWebDataFromUrl::curl_ = NULL;
- GetWebDataFromUrl::GetWebDataFromUrl(void)
- {
- }
- GetWebDataFromUrl::~GetWebDataFromUrl(void)
- {
- }
- /************************************************************************/
- /* 函数名:Initialize
- /* 功 能: 初始化libcurl库
- /* 返回值:成功,返回true;失败,返回false
- /************************************************************************/
- bool GetWebDataFromUrl::Initialize(string curlopt_proxy_ip, string curlopt_proxy_port)
- {
- curl_global_init(CURL_GLOBAL_ALL);
- curl_ = curl_easy_init();
- struct curl_slist *chunk = NULL;
- if (curl_)
- {
- cout << curl_version() << endl;
- chunk = curl_slist_append(chunk, "Accept:text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8");
- chunk = curl_slist_append(chunk, "Accept-Charset:GBK,utf-8;q=0.7,*;q=0.3");
- chunk = curl_slist_append(chunk, "Accept-Language:zh-TW,zh;q=0.8,en-US;q=0.6,en;q=0.4,zh-CN;q=0.2");
- chunk = curl_slist_append(chunk, "Connection:keep-alive");
- chunk = curl_slist_append(chunk, "Accept-Charset:GBK,utf-8;q=0.7,*;q=0.3");
- chunk = curl_slist_append(chunk, "Accept:text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8");
- chunk = curl_slist_append(chunk, "Accept-Encoding:gzip,deflate,sdch");
- chunk = curl_slist_append(chunk, "User-Agent: Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.31 (KHTML, like Gecko) Chrome/26.0.1410.64 Safari/537.31");
- chunk = curl_slist_append(chunk, "Expect:");
- if (!curlopt_proxy_ip.empty() && !curlopt_proxy_port.empty())
- {
- curl_easy_setopt(curl_, CURLOPT_PROXY, curlopt_proxy_ip.c_str());
- curl_easy_setopt(curl_, CURLOPT_PROXYPORT, std::atoi(curlopt_proxy_port.c_str()));
- // curl_easy_setopt(m_curl, CURLOPT_PROXYTYPE, CURLPROXY_HTTP);
- }
- curl_easy_setopt(curl_, CURLOPT_FOLLOWLOCATION, 1L);
- curl_easy_setopt(curl_, CURLOPT_WRITEFUNCTION, WriteFunc);
- curl_easy_setopt(curl_, CURLOPT_WRITEDATA, &web_data_);
- curl_easy_setopt(curl_, CURLOPT_ACCEPT_ENCODING, "gzip");
- curl_easy_setopt(curl_, CURLOPT_HTTPHEADER, chunk);
- }
- else
- {
- MessageBoxA(NULL,"GetPageByURL::Initialize Failed!", "GetPageByURL::Initialize", MB_ICONERROR);
- return false;
- }
- return true;
- }
- /************************************************************************/
- /* 函数名:WriteFunc
- /* 功 能: libcurl会调用这个标准的函数,
- /* size_t function( void *ptr, size_t size, size_t nmemb, void *userdata);
- /* 以提供格式化网页数据的机会
- /* curl_easy_setopt(curl, CURLOPT_WRITEFUNCTION, WriteFunc);
- /* 返回值:返回buffer的大小
- /************************************************************************/
- size_t GetWebDataFromUrl::WriteFunc(char *data, size_t size, size_t nmemb, string *writerData)
- {
- if (writerData == NULL)
- return 0;
- size_t len = size*nmemb;
- writerData->append(data, len);
- return len;
- }
- /************************************************************************/
- /* 函数名:GetPage
- /* 功 能: 根据url,抓取对应的网页源码;使用了libcurl库
- /* 返回值:成功,返回包含网页源码的字符串;失败,返回空字符串
- /************************************************************************/
- bool GetWebDataFromUrl::GetPage(const string& urlStr, //url字符串
- string& page //输出参数,返回对应页面源码
- )
- {
- _ASSERT("" != urlStr);
- if(!curl_)
- {
- MessageBoxA(NULL,"You must initialize curl first!", "GetPageByURL", MB_ICONERROR);
- return false;
- }
- web_data_.clear();
- curl_easy_setopt(curl_, CURLOPT_URL, urlStr.c_str());
- CURLcode res = curl_easy_perform(curl_);
- if(res != CURLE_OK)
- {
- MessageBoxA(NULL,"curl call false!", "GetWebDataFromUrl::GetPage2", MB_ICONERROR);
- return false;
- }
- else
- {
- page = web_data_;
- return true;
- }
- }
- /************************************************************************/
- /* 函数名:Cleanup
- /* 功 能: 清理内存
- /* 返回值:无
- /************************************************************************/
- void GetWebDataFromUrl::Cleanup()
- {
- if(curl_)
- {
- /* always cleanup */
- curl_easy_cleanup(curl_);
- curl_ = NULL;
- }
- }
- void GetWebDataFromUrl::GetPageContent(string page_link, string &page_content)
- {
- page_content = "";
- GetWebDataFromUrl::GetPage(page_link, page_content);
- }
这样,对于像“http://www.fenzhi.com/”那样的网站(始终进行gzip压缩),都能够正确获取到源代码了,其实主要是在初始化curl的时候,给了一个标志
curl_easy_setopt(curl_, CURLOPT_ACCEPT_ENCODING, "gzip");
这个标志,需要在编译curl的时候,假如zlib。要不然找不到这个标志
但是在cout到屏幕的时候,看到的还是乱码,那是因为cout使用的对汉字编码格式不同的缘故:

但是我们看到的输出到文件的部分已经是正确的了:
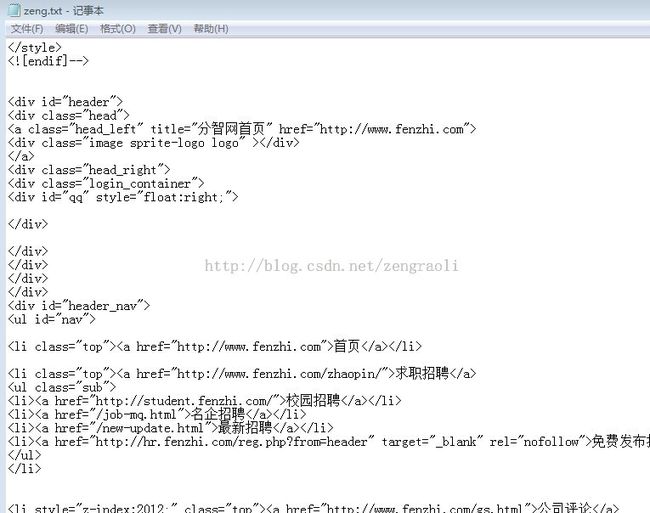
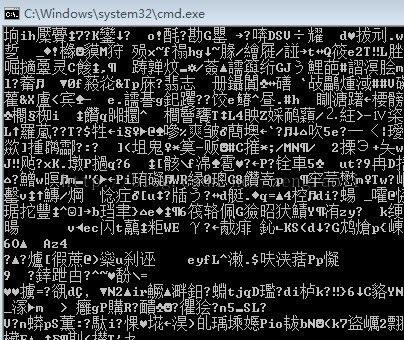
为了对比,把其中一行代码去掉,可以看到原始效果:
- // curl_easy_setopt(m_curl, CURLOPT_ACCEPT_ENCODING, "gzip");
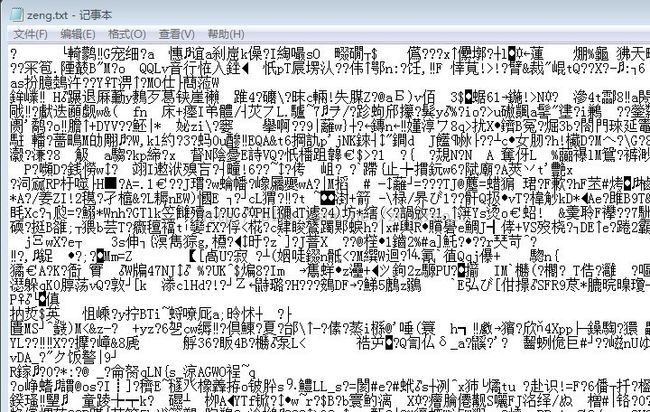
忘了,最好说一下我的对应版本:

目前的这一部分工程已经上传到我的资源中,对应的下载地址如下:
http://download.csdn.net/download/zengraoli/6474927