C4.5算法笔记
1.简介
C4.5算法是机器学习和数据挖掘领域中的一个用于处理分类问题的算法。该算法是有监督学习类型的,即:给定一个数据集,所有实例都由一组属性来描述,每个实例仅属于一个类别,在给定数据集上运行C4.5算法可以学习得到一个从属性值到类别的映射,进而可使用该映射去分类新的未知实例。C4.5算法是由J.Ross Quinlan设计的,源于名为ID3的一种决策树诱导算法,而ID3是被称为“迭代分解器”系列算法的第3代。决策树相当于将一系列问题组织成树。具体说,每个问题对应一个属性,根据属性值来生成判断分支,一直到决策树的叶节点产生了类别的预测结果。
2.算法描述
所有的树诱导方法都大体遵循一种统一的递归模式,即:首先,用根节点表示一个给定的数据集;然后,从根节点开始在每个节点上测试一个特定的属性,把节点数据集划分成更小的子集,并用子树表示;该过程就要一直进行,知道子集成为“纯”的,就是说直到子集中的所有实例都属于同一个类别,树才停止增长。如下数据集,表示天气情况和是否去打高尔夫球的关系:

通过C4.5算法诱导出树:
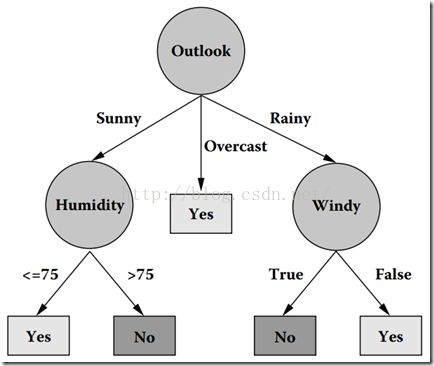
现在我们看下该树是怎么转化而来的。
2.1信息熵(Entropy)
信息熵是用来衡量一个随机变量出现的期望值,一个变量的信息熵越大,那么他出现的各种情况也就越多,也就是包含的内容多,我们要描述他就需要付出更多的表达才可以,也就是需要更多的信息才能确定这个变量。而C4.5算法中属性的熵的计算公式为:所以,PlayGolf?的取值是9(Yes)和5(No),所以它的熵值计算如:
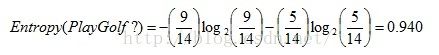
2.2信息增益
在树诱导过程中,C4.5算法的目标就通过核实的提问来获得信息,实现这个熵值的下降。我们依次考察每个属性,计算该属性导致的熵值下降幅度。我们称这种下降幅度为信息增益。信息增益的计算公式为:
所以,对于Outlook而言,它包含有三个属性:Sunny、OverCast、Rainy,而Sunny有2(Yes)和3(No),OverCast有4(Yes),Rainy有3(Yes)和2(No)。则:
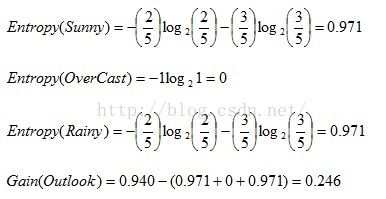
同理,计算出其他属性的信息增益:

我们可以看到Outlook的信息增益最大,所以Outlook作为根节点,从Outlook下面出来三个树枝:Sunny、OverCast、Rainy。然后从Sunny的实例数据中,找到信息增益最大的那个,以此类推。
2.3分离信息
数据集通过条件属性A的分离信息。分离信息的计算公式,即为求属性A的信息熵:
如Outlook有三个属性:Sunny、OverCast、Rainy,所以它的分离信息为:
![]()
2.4信息增益率
C4.5算法默认的分裂准则实际是信息增益率,而非信息增益。而信息增益率的计算公式为: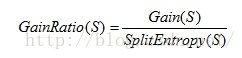
所以,Outlook的信息增益率计算如下:

3.剪枝
C4.5算法创造性地提出了被称为悲观剪枝的方法,该方法不再需要一个单独的测试数据集,而是通过在训练数据集上的错误分类数据量来估算未知实例上的错误率。悲观剪枝方法通过递归计算目标节点的分支的错误率来获得该目标节点的错误率。例如,对有N个实例和E个错误(就是说所属类别与该叶节点预测类别不一致的实例数量)的叶节点,悲观剪枝首先用比值