CentOS下Hadoop伪分布模式安装笔记
一. 概要
经过几天的调试,终于在Linux Cent OS 6.3下成功搭建Hadoop测试环境。本次测试在一台服务器上进行伪分布式搭建。
Hadoop 伪分布式模式是在单机上模拟 Hadoop 分布式,单机上的分布式并不是真正的伪分布式,而是使用线程模拟分布式。Hadoop 本身是无法区分伪分布式和分布式的,两种配置也很相似,唯一不同的地方是伪分布式是在单机器上配置,数据节点和名字节点均是一个机
器。虽然Hadoop的安装步骤并不复杂,但是我在安装期间还是遇到了很多琐碎的问题,现将自己搭建Hadoop的详细过程和遇到的问题记录下来。
二. 环境搭建
搭建测试环境所需的软件包括:
jdk1.6.0_38、hadoop-1.1.1.tar.gz。测试服务器操作系统Linux Cent OS 6.3。
1. SSH无密码验证配置
Hadoop 需要使用SSH 协议,namenode 将使用SSH 协议启动 namenode和datanode 进程,伪分布式模式数据节点和名称节点均是本身,必须配置 SSH localhost无密码验证。
用root用户登录,在家目录下执行如下命令:ssh-keygen -t rsa
[root@master ~]# ssh-keygen -t rsa
Generating public/private rsa key pair.
Enter file in which to save the key (/root/.ssh/id_rsa): & 按回车默认路径 &
Created directory '/root/.ssh'. &创建/root/.ssh目录&
Enter passphrase (empty for no passphrase):
Enter same passphrase again:
Your identification has been saved in /root/.ssh/id_rsa.
Your public key has been saved in /root/.ssh/id_rsa.pub.
The key fingerprint is:
c6:7e:57:59:0a:2d:85:49:23:cc:c4:58:ff:db:5b:38 root@master
通过以上命令将在/root/.ssh/ 目录下生成id_rsa私钥和id_rsa.pub公钥。进入/root/.ssh目录在namenode节点下做如下配置:
Generating public/private rsa key pair.
Enter file in which to save the key (/root/.ssh/id_rsa): & 按回车默认路径 &
Created directory '/root/.ssh'. &创建/root/.ssh目录&
Enter passphrase (empty for no passphrase):
Enter same passphrase again:
Your identification has been saved in /root/.ssh/id_rsa.
Your public key has been saved in /root/.ssh/id_rsa.pub.
The key fingerprint is:
c6:7e:57:59:0a:2d:85:49:23:cc:c4:58:ff:db:5b:38 root@master
通过以上命令将在/root/.ssh/ 目录下生成id_rsa私钥和id_rsa.pub公钥。进入/root/.ssh目录在namenode节点下做如下配置:
[root@master .ssh]# cat id_rsa.pub > authorized_keys
配置完毕,可通过ssh 本机IP 测试是否需要密码登录。
如果出现错误:ssh: connect to host localhost port 22: Connection refused,输入以下命令启动ssh:
#/etc/init.d/sshd start
2. JDK安装及Java环境变量的配置
2.1 JDK安装
root 用户登陆,新建文件夹 /usr/program ,下载 JDK 安装包
sudo chmod u+x jdk-6u38-linux-i586.bin
jdk-6u38-linux-i586.bin,复制到目录/usr/ program 下,在命令行进入该目录,执行命令“./ jdk-6u38-linux-i586.bin”,命令运行完毕,将在目录下生成文件夹jdk1.6.0_38,安装完毕。
jdk-6u38-linux-i586.bin,复制到目录/usr/ program 下,在命令行进入该目录,执行命令“./ jdk-6u38-linux-i586.bin”,命令运行完毕,将在目录下生成文件夹jdk1.6.0_38,安装完毕。
在64系统里执行32位程序如果出现/lib/ld-linux.so.2: bad ELF interpreter: No such file or directory,安装下glic即可
sudo yum install glibc.i686
2.2 java环境变量配置
root 用户登陆,命令行中执行命令“vi /etc/profile”,并加入以下内容,配置环境变量(注意/etc/profile 这个文件很重要,后面 Hadoop 的配置还会用到)。
# set java environment
export JAVA_HOME=/usr/program/jdk1.6.0_38
export JRE_HOME=/usr/program/jdk1.6.0_38/jre
export CLASSPATH=.:$JAVA_HOME/lib:$JAVA_HOME/jre/lib
export PATH=$JAVA_HOME/bin:$JAVA_HOME/jre/bin:$PATH
# set java environment
export JAVA_HOME=/usr/program/jdk1.6.0_38
export JRE_HOME=/usr/program/jdk1.6.0_38/jre
export CLASSPATH=.:$JAVA_HOME/lib:$JAVA_HOME/jre/lib
export PATH=$JAVA_HOME/bin:$JAVA_HOME/jre/bin:$PATH
在vi编辑器增加以上内容后保存退出,并执行以下命令使配置生效
chmod +x /etc/profile ;增加执行权限
source /etc/profile ;
配置完毕后,在命令行中输入java -version,如出现下列信息说明java环境安装成功。
java version "1.6.0_38"
Java(TM) SE Runtime Environment (build 1.6.0_38-b05)
Java HotSpot(TM) Server VM (build 20.13-b02, mixed mode, sharing)
Java(TM) SE Runtime Environment (build 1.6.0_38-b05)
Java HotSpot(TM) Server VM (build 20.13-b02, mixed mode, sharing)
2. Hadoop配置
下载 hadoop-1.1.1.tar.gz,将其解压到/usr/local/hadoop 目录下,解压后目录形式是/usr/local/hadoop/hadoop-1.1.1。使用如下命令:
tar zxvf hadoop-1.1.1.tar.gz 进行hadoop压缩文件解压。
tar zxvf hadoop-1.1.1.tar.gz 进行hadoop压缩文件解压。
2.1 进入/usr/local/hadoop/hadoop-1.1.1/conf, 配置Hadoop配置文件
2.1.1 配置hadoop-env.sh文件
添加 # set java environment
export JAVA_HOME=/usr/program/jdk1.6.0_20
export JAVA_HOME=/usr/program/jdk1.6.0_20
编辑后
保存退出。
2.1.2 配置core-site.xml
[root@master conf]# vi core-site.xml
<?xml version="1.0"?>
<?xml-stylesheet type="text/xsl" href=\'#\'" /font>
<?xml-stylesheet type="text/xsl" href=\'#\'" /font>
<!-- Put site-specific property overrides in this file. -->
<configuration>
<property>
<name>fs.default.name</name>
<value>hdfs://202.173.253.36:9000/</value>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>/usr/local/hadoop/hadooptmp</value>
</property>
</configuration>
2.1.3 配置hdfs-site.xml
[root@master conf]# vi hdfs-site.xml
<?xml version="1.0"?>
<?xml-stylesheet type="text/xsl" href=\'#\'" /font>
<?xml-stylesheet type="text/xsl" href=\'#\'" /font>
<!-- Put site-specific property overrides in this file. -->
<configuration>
<property>
<name>dfs.name.dir</name>
<value>/usr/local/hadoop/hdfs/name</value>
</property>
<property>
<name>dfs.data.dir</name>
<value>/usr/local/hadoop/hdfs/data</value>
</property>
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
</configuration>
2.1.4 配置mapred-site.xml
[root@master conf]# vi mapred-site.xml
<?xml version="1.0"?>
<?xml-stylesheet type="text/xsl" href=\'#\'" /font>
<?xml-stylesheet type="text/xsl" href=\'#\'" /font>
<!-- Put site-specific property overrides in this file. -->
<configuration>
<property>
<name>mapred.job.tracker</name>
<value>202.173.253.36:9001</value>
</property>
<property>
<name>mapred.local.dir</name>
<value>/usr/local/hadoop/mapred/local</value>
</property>
<property>
<name>mapred.system.dir</name>
<value>/tmp/hadoop/mapred/system</value>
</property>
</configuration>
2.1.5 配置masters文件和slaves文件
[root@master conf]# vi masters
202.173.253.36
[root@master conf]# vi slaves
202.173.253.36
注:因为在伪分布模式下,作为master的namenode与作为slave的datanode是同一台服务器,所以配置文件中的ip是一样的。
2.1.6 编辑主机名
[root@master ~]# vi /etc/hosts
# Do not remove the following line, or various programs
that require network functionality will fail.
that require network functionality will fail.
127.0.0.1 localhost
202.173.253.36 master
202.173.253.36 slave
202.173.253.36 master
202.173.253.36 slave
注:因为是在伪分布模式下,所以master与slave是一台机
2.2 Hadoop启动
2.2.1 进入 /usr/local/hadoop/hadoop-0.20.2/bin目录下,格式化namenode
[root@master bin]# hadoop namenode -format
10/07/19 10:46:41 INFO namenode.NameNode: STARTUP_MSG:
/************************************************************
STARTUP_MSG: Starting NameNode
STARTUP_MSG: host = master/202.173.253.36
STARTUP_MSG: args = [-format]
STARTUP_MSG: version = 0.20.2
STARTUP_MSG: build = https://svn.apache.org/repos/asf/hadoop/common/branches/branch-0.20-r 911707; compiled by 'chrisdo' on Fri Feb 19 08:07:34 UTC 2010
************************************************************/
Re-format filesystem in /usr/local/hadoop/hdfs/name ? (Y or N) Y
10/07/19 10:46:43 INFO namenode.FSNamesystem: fsOwner=root,root,bin,daemon,sys,adm,disk,wheel
10/07/19 10:46:43 INFO namenode.FSNamesystem: supergroup=supergroup
10/07/19 10:46:43 INFO namenode.FSNamesystem: isPermissionEnabled=true
10/07/19 10:46:43 INFO common.Storage: Image file of size 94 saved in 0 seconds.
10/07/19 10:46:43 INFO common.Storage: Storage directory /usr/local/hadoop/hdfs/name has been successfully formatted.
10/07/19 10:46:43 INFO namenode.NameNode: SHUTDOWN_MSG:
/************************************************************
SHUTDOWN_MSG: Shutting down NameNode at master/202.173.253.36
************************************************************/
10/07/19 10:46:41 INFO namenode.NameNode: STARTUP_MSG:
/************************************************************
STARTUP_MSG: Starting NameNode
STARTUP_MSG: host = master/202.173.253.36
STARTUP_MSG: args = [-format]
STARTUP_MSG: version = 0.20.2
STARTUP_MSG: build = https://svn.apache.org/repos/asf/hadoop/common/branches/branch-0.20-r 911707; compiled by 'chrisdo' on Fri Feb 19 08:07:34 UTC 2010
************************************************************/
Re-format filesystem in /usr/local/hadoop/hdfs/name ? (Y or N) Y
10/07/19 10:46:43 INFO namenode.FSNamesystem: fsOwner=root,root,bin,daemon,sys,adm,disk,wheel
10/07/19 10:46:43 INFO namenode.FSNamesystem: supergroup=supergroup
10/07/19 10:46:43 INFO namenode.FSNamesystem: isPermissionEnabled=true
10/07/19 10:46:43 INFO common.Storage: Image file of size 94 saved in 0 seconds.
10/07/19 10:46:43 INFO common.Storage: Storage directory /usr/local/hadoop/hdfs/name has been successfully formatted.
10/07/19 10:46:43 INFO namenode.NameNode: SHUTDOWN_MSG:
/************************************************************
SHUTDOWN_MSG: Shutting down NameNode at master/202.173.253.36
************************************************************/
2.2.2 启动hadoop所有进程
在/usr/local/hadoop/hadoop-0.20.2/bin 目录下,执行start-all.sh命令
启动完成后,可用jps命令查看hadoop进程是否启动完全。正常情况下应该有如下进程:
10910 NameNode
11431 Jps
11176 SecondaryNameNode
11053 DataNode
11254 JobTracker
11378 TaskTracker
11431 Jps
11176 SecondaryNameNode
11053 DataNode
11254 JobTracker
11378 TaskTracker
我在搭建过程中,在此环节出现的问题最多,经常出现启动进程不完整的情况,要不是datanode无法正常启动,就是namenode或是TaskTracker启动异常。解决的方式如下:
1.在Linux下关闭防火墙:使用service iptables stop命令;
2.再次对namenode进行格式化:在/usr/local/hadoop/hadoop-0.20.2/bin 目录下执行hadoop namenode -format命令
3.对服务器进行重启
4.查看datanode或是namenode对应的日志文件,日志文件保存在/usr/local/hadoop/hadoop-0.20.2/logs目录下。仔细查看日志报错的原因,(上次日志报错的信息忘记了)解决方法是进入/usr/local/hadoop/hdfs/name 和usr/local/hadoop/hdfs/data目录下,将目录下的文件全部删除。
5.再次在/bin目录下用start-all.sh命令启动所有进程,通过以上的几个方法应该能解决进程启动不完全的问题了。
2.2.3 查看集群状态
在 bin目录下执行:hadoop dfsadmin -report
[root@master bin]# hadoop dfsadmin -report
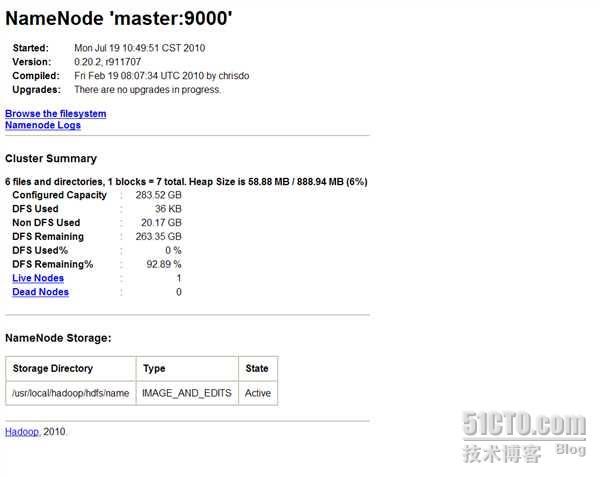
Configured Capacity: 304427253760 (283.52 GB)
Present Capacity: 282767941632 (263.35 GB)
DFS Remaining: 282767904768 (263.35 GB)
DFS Used: 36864 (36 KB)
DFS Used%: 0%
Under replicated blocks: 0
Blocks with corrupt replicas: 0
Missing blocks: 0
Configured Capacity: 304427253760 (283.52 GB)
Present Capacity: 282767941632 (263.35 GB)
DFS Remaining: 282767904768 (263.35 GB)
DFS Used: 36864 (36 KB)
DFS Used%: 0%
Under replicated blocks: 0
Blocks with corrupt replicas: 0
Missing blocks: 0
-------------------------------------------------
Datanodes available: 1 (1 total, 0 dead)
Datanodes available: 1 (1 total, 0 dead)
Name: 202.173.253.36:50010
Decommission Status : Normal
Configured Capacity: 304427253760 (283.52 GB)
DFS Used: 36864 (36 KB)
Non DFS Used: 21659312128 (20.17 GB)
DFS Remaining: 282767904768(263.35 GB)
DFS Used%: 0%
DFS Remaining%: 92.89%
Last contact: Mon Jul 19 11:07:22 CST 2010
Decommission Status : Normal
Configured Capacity: 304427253760 (283.52 GB)
DFS Used: 36864 (36 KB)
Non DFS Used: 21659312128 (20.17 GB)
DFS Remaining: 282767904768(263.35 GB)
DFS Used%: 0%
DFS Remaining%: 92.89%
Last contact: Mon Jul 19 11:07:22 CST 2010
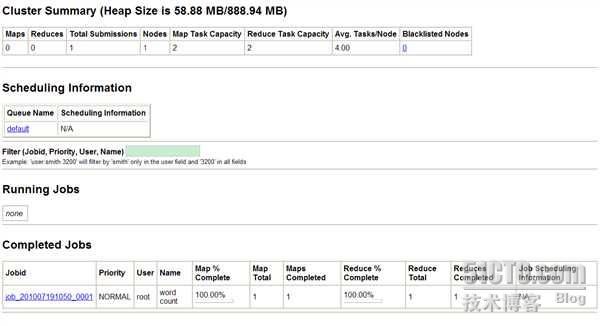
2.3 在WEB页面下查看Hadoop工作情况
打开IE浏览器输入部署Hadoop服务器的IP:
http://localhost:50070;
http://localhost:50030。
3. Hadop使用
一个测试例子wordcount
计算输入文本中词语数量的程序。WordCount在Hadoop主目录下的java程序包hadoop-0.20.2-examples.jar 中,执行步骤如下:
在/usr/local/hadoop/hadoop-0.20.2/bin/目录下进行如下操作:
hadoop fs -mkdir bxy(新建目录名称,可任意命名)
[root@master log]# hadoop fs -copyFromLocal secure.2 bxy
(找一个任意文件将其copy到bxy文件夹)
在/usr/local/hadoop/hadoop-0.20.2下执行:
[root@master hadoop-0.20.2]# hadoop jar hadoop-0.20.2-examples.jar wordcount bxy output (提交作业,此处需注意bxy与output是一组任务,下次再执行wordcount程序,还要新建目录bxy1与output1不能跟bxy与output重名)
执行完毕后,可进入web界面刷新查看running job及completed job的显示。