实践部署与使用apache kafka框架技术博文资料汇总
实践部署与使用apache kafka框架技术博文资料汇总
http://blog.csdn.net/zhongwen7710/article/details/41252649
前一篇Kafka框架设计来自英文原文(Kafka Architecture Design)的翻译及整理文章,很有借鉴性,本文是从一个企业使用Kafka框架的角度来记录及整理的Kafka框架的技术资料,也很有借鉴价值,为了便于阅读与分享,我将其整理一篇Blog。本文内容目录摘要如下:
1)apache kafka消息服务
2)kafka在zookeeper中存储结构3)kafka log4j配置
4)kafka replication设计机制5)apache kafka监控系列-监控指标
6)kafka.common.ConsumerRebalanceFailedException异常解决办法7)kafak安装与使用
8)apache kafka中server.properties配置文件参数说明9)apache kafka的consumer初始化时获取不到消息
10)Kafka Producer处理逻辑11)apache kafka源代码工程环境搭建(IDEA)
12)apache kafka监控系列-KafkaOffsetMonitor
13)Kafka Controller设计机制
14)Kafka性能测试报告(虚拟机版)15)apache kafka监控系列-kafka-web-console
16)apache kafka迁移与扩容工具用法17)kafka LeaderNotAvailableException
18)apache kafka jmx监控指标参数19)apache kafka性能测试命令使用和构建kafka-perf
20)apache kafka源码构建打包
21)Apache kafka客户端开发-java
22) kafka broker内部架构
23)apache kafka源码分析走读-kafka整体结构分析24)apache kafka源码分析走读-Producer分析
25)apache kafka性能优化架构分析26)apache kafka源码分析走读-server端网络架构分析
27)apache kafka源码分析走读-ZookeeperConsumerConnector分析28)kafka的ZkUtils类的java版本部分代码
29)kafka & mafka client开发与实践30) kafka文件系统设计那些事
31)kafka的ZookeeperConsumer实现
详细内容如下所示:
1)apache kafka消息服务
apache kafka参考
http://kafka.apache.org/documentation.html
消息队列分类:
点对点:
消息生产者生产消息发送到queue中,然后消息消费者从queue中取出并且消费消息。这里要注意:
- 消息被消费以后,queue中不再有存储,所以消息消费者不可能消费到已经被消费的消息。
- Queue支持存在多个消费者,但是对一个消息而言,只会有一个消费者可以消费。
发布/订阅
消息生产者(发布)将消息发布到topic中,同时有多个消息消费者(订阅)消费该消息。和点对点方式不同,发布到topic的消息会被所有订阅者消费。
kafka消息队列调研
背景介绍
kafka是最初由Linkedin公司开发,使用Scala语言编写,Kafka是一个分布式、分区的、多副本的、多订阅者的日志系统(分布式MQ系统),可以用于web/nginx日志,搜索日志,监控日志,访问日志等等。
kafka目前支持多种客户端语言:java,python,c++,php等等。
总体结构:

kafka名词解释和工作方式:
- Producer :消息生产者,就是向kafka broker发消息的客户端。
- Consumer :消息消费者,向kafka broker取消息的客户端
- Topic :咋们可以理解为一个队列。
- Consumer Group (CG):这是kafka用来实现一个topic消息的广播(发给所有的consumer)和单播(发给任意一个consumer)的手段。一个topic可以有多个CG。topic的消息会复制(不是真的复制,是概念上的)到所有的CG,但每个CG只会把消息发给该CG中的一个consumer。如果需要实现广播,只要每个consumer有一个独立的CG就可以了。要实现单播只要所有的consumer在同一个CG。用CG还可以将consumer进行自由的分组而不需要多次发送消息到不同的topic。
- Broker :一台kafka服务器就是一个broker。一个集群由多个broker组成。一个broker可以容纳多个topic。
- Partition:为了实现扩展性,一个非常大的topic可以分布到多个broker(即服务器)上,一个topic可以分为多个partition,每个partition是一个有序的队列。partition中的每条消息都会被分配一个有序的id(offset)。kafka只保证按一个partition中的顺序将消息发给consumer,不保证一个topic的整体(多个partition间)的顺序。
- Offset:kafka的存储文件都是按照offset.kafka来命名,用offset做名字的好处是方便查找。例如你想找位于2049的位置,只要找到2048.kafka的文件即可。当然the first offset就是00000000000.kafka
kafka特性:
- 通过O(1)的磁盘数据结构提供消息的持久化,这种结构对于即使数以TB的消息存储也能够保持长时间的稳定性能。
- 高吞吐量:即使是非常普通的硬件kafka也可以支持每秒数十万的消息。
- 支持同步和异步复制两种HA
- Consumer客户端pull,随机读,利用sendfile系统调用,zero-copy ,批量拉数据
- 消费状态保存在客户端
- 消息存储顺序写
- 数据迁移、扩容对用户透明
- 支持Hadoop并行数据加载。
- 支持online和offline的场景。
- 持久化:通过将数据持久化到硬盘以及replication防止数据丢失。
- scale out:无需停机即可扩展机器。
- 定期删除机制,支持设定partitions的segment file保留时间。
可靠性(一致性)
kafka(MQ)要实现从producer到consumer之间的可靠的消息传送和分发。传统的MQ系统通常都是通过broker和consumer间的确认(ack)机制实现的,并在broker保存消息分发的状态。
即使这样一致性也是很难保证的(参考原文)。kafka的做法是由consumer自己保存状态,也不要任何确认。这样虽然consumer负担更重,但其实更灵活了。
因为不管consumer上任何原因导致需要重新处理消息,都可以再次从broker获得。
kafak系统扩展性
kafka使用zookeeper来实现动态的集群扩展,不需要更改客户端(producer和consumer)的配置。broker会在zookeeper注册并保持相关的元数据(topic,partition信息等)更新。
而客户端会在zookeeper上注册相关的watcher。一旦zookeeper发生变化,客户端能及时感知并作出相应调整。这样就保证了添加或去除broker时,各broker间仍能自动实现负载均衡。
kafka设计目标
高吞吐量是其核心设计之一。
- 数据磁盘持久化:消息不在内存中cache,直接写入到磁盘,充分利用磁盘的顺序读写性能。
- zero-copy:减少IO操作步骤。
- 支持数据批量发送和拉取。
- 支持数据压缩。
- Topic划分为多个partition,提高并行处理能力。
Producer负载均衡和HA机制
- producer根据用户指定的算法,将消息发送到指定的partition。
- 存在多个partiiton,每个partition有自己的replica,每个replica分布在不同的Broker节点上。
- 多个partition需要选取出lead partition,lead partition负责读写,并由zookeeper负责fail over。
- 通过zookeeper管理broker与consumer的动态加入与离开。
Consumer的pull机制
由于kafka broker会持久化数据,broker没有cahce压力,因此,consumer比较适合采取pull的方式消费数据,具体特别如下:
- 简化kafka设计,降低了难度。
- Consumer根据消费能力自主控制消息拉取速度。
- consumer根据自身情况自主选择消费模式,例如批量,重复消费,从制定partition或位置(offset)开始消费等.
Consumer与topic关系以及机制
本质上kafka只支持Topic.每个consumer属于一个consumer group;反过来说,每个group中可以有多个consumer.对于Topic中的一条特定的消息,
只会被订阅此Topic的每个group中的一个consumer消费,此消息不会发送给一个group的多个consumer;那么一个group中所有的consumer将会交错的消费整个Topic.
如果所有的consumer都具有相同的group,这种情况和JMS queue模式很像;消息将会在consumers之间负载均衡.
如果所有的consumer都具有不同的group,那这就是"发布-订阅";消息将会广播给所有的消费者.
在kafka中,一个partition中的消息只会被group中的一个consumer消费(同一时刻);每个group中consumer消息消费互相独立;我们可以认为一个group是一个"订阅"者,
一个Topic中的每个partions,只会被一个"订阅者"中的一个consumer消费,不过一个consumer可以同时消费多个partitions中的消息.
kafka只能保证一个partition中的消息被某个consumer消费时是顺序的.事实上,从Topic角度来说,当有多个partitions时,消息仍不是全局有序的.
通常情况下,一个group中会包含多个consumer,这样不仅可以提高topic中消息的并发消费能力,而且还能提高"故障容错"性,如果group中的某个consumer失效,
那么其消费的partitions将会有其他consumer自动接管.kafka的设计原理决定,对于一个topic,同一个group中不能有多于partitions个数的consumer同时消费,
否则将意味着某些consumer将无法得到消息.
Producer均衡算法
kafka集群中的任何一个broker,都可以向producer提供metadata信息,这些metadata中包含"集群中存活的servers列表"/"partitions leader列表"
等信息(请参看zookeeper中的节点信息).当producer获取到metadata信心之后, producer将会和Topic下所有partition leader保持socket连接;
消息由producer直接通过socket发送到broker,中间不会经过任何"路由层".事实上,消息被路由到哪个partition上,有producer客户端决定.
比如可以采用"random""key-hash""轮询"等,如果一个topic中有多个partitions,那么在producer端实现"消息均衡分发"是必要的.
在producer端的配置文件中,开发者可以指定partition路由的方式.
Consumer均衡算法
当一个group中,有consumer加入或者离开时,会触发partitions均衡.均衡的最终目的,是提升topic的并发消费能力.
1) 假如topic1,具有如下partitions: P0,P1,P2,P3
2) 加入group中,有如下consumer: C0,C1
3) 首先根据partition索引号对partitions排序: P0,P1,P2,P3
4) 根据consumer.id排序: C0,C1
5) 计算倍数: M = [P0,P1,P2,P3].size / [C0,C1].size,本例值M=2(向上取整)
6) 然后依次分配partitions: C0 = [P0,P1],C1=[P2,P3],即Ci = [P(i * M),P((i + 1) * M -1)]
kafka broker集群内broker之间replica机制
kafka中,replication策略是基于partition,而不是topic;kafka将每个partition数据复制到多个server上,任何一个partition有一个leader和多个follower(可以没有);
备份的个数可以通过broker配置文件来设定.leader处理所有的read-write请求,follower需要和leader保持同步.Follower就像一个"consumer",
消费消息并保存在本地日志中;leader负责跟踪所有的follower状态,如果follower"落后"太多或者失效,leader将会把它从replicas同步列表中删除.
当所有的follower都将一条消息保存成功,此消息才被认为是"committed",那么此时consumer才能消费它,这种同步策略,就要求follower和leader之间必须具有良好的网络环境.
即使只有一个replicas实例存活,仍然可以保证消息的正常发送和接收,只要zookeeper集群存活即可.(备注:不同于其他分布式存储,比如hbase需要"多数派"存活才行)
kafka判定一个follower存活与否的条件有2个:
1) follower需要和zookeeper保持良好的链接
2) 它必须能够及时的跟进leader,不能落后太多.
如果同时满足上述2个条件,那么leader就认为此follower是"活跃的".如果一个follower失效(server失效)或者落后太多,
leader将会把它从同步列表中移除[备注:如果此replicas落后太多,它将会继续从leader中fetch数据,直到足够up-to-date,
然后再次加入到同步列表中;kafka不会更换replicas宿主!因为"同步列表"中replicas需要足够快,这样才能保证producer发布消息时接受到ACK的延迟较小。
当leader失效时,需在followers中选取出新的leader,可能此时follower落后于leader,因此需要选择一个"up-to-date"的follower.kafka中leader选举并没有采用"投票多数派"的算法,
因为这种算法对于"网络稳定性"/"投票参与者数量"等条件有较高的要求,而且kafka集群的设计,还需要容忍N-1个replicas失效.对于kafka而言,
每个partition中所有的replicas信息都可以在zookeeper中获得,那么选举leader将是一件非常简单的事情.选择follower时需要兼顾一个问题,
就是新leader server上所已经承载的partition leader的个数,如果一个server上有过多的partition leader,意味着此server将承受着更多的IO压力.
在选举新leader,需要考虑到"负载均衡",partition leader较少的broker将会更有可能成为新的leader.
在整几个集群中,只要有一个replicas存活,那么此partition都可以继续接受读写操作.
总结:
1) Producer端直接连接broker.list列表,从列表中返回TopicMetadataResponse,该Metadata包含Topic下每个partition leader建立socket连接并发送消息.
2) Broker端使用zookeeper用来注册broker信息,以及监控partition leader存活性.
3) Consumer端使用zookeeper用来注册consumer信息,其中包括consumer消费的partition列表等,同时也用来发现broker列表,并和partition leader建立socket连接,并获取消息.
性能测试
目前我已经在虚拟机上做了性能测试。
测试环境:cpu: 双核 内存 :2GB 硬盘:60GB
|
测试指标
|
性能相关说明
|
结论
|
|---|---|---|
| 消息堆积压力测试 | 单个kafka broker节点测试,启动一个kafka broker和Producer,Producer不断向broker发送数据, 直到broker堆积数据为18GB为止(停止Producer运行)。启动Consumer,不间断从broker获取数据, 直到全部数据读取完成为止,最后查看Producer==Consumer数据,没有出现卡死或broker不响应现象 |
数据大量堆积不会出现broker卡死 或不响应现象 |
| 生产者速率 | 1.200byte/msg,4w/s左右。2.1KB/msg,1w/s左右 | 性能上是完全满足要求,其性能主要由磁盘决定 |
| 消费者速率 | 1.200byte/msg,4w/s左右。2.1KB/msg,1w/s左右 | 性能上是完全满足要求,其性能主要由磁盘决定 |
2)kafka在zookeeper中存储结构
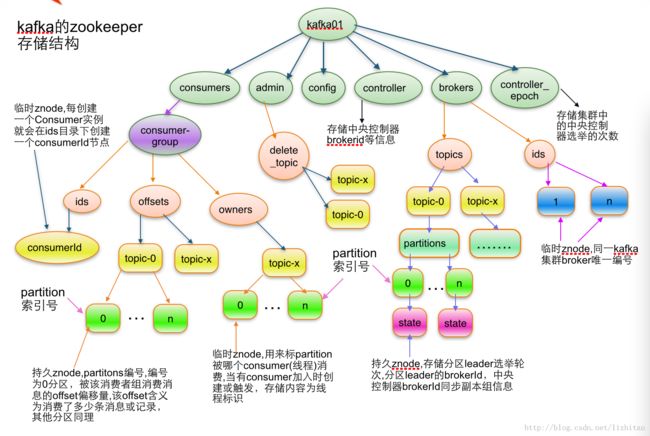
1.topic注册信息
/brokers/topics/[topic] :
存储某个topic的partitions所有分配信息
Schema:
"version": "版本编号目前固定为数字1", "partitions": { "partitionId编号": [ 同步副本组brokerId列表 ], "partitionId编号": [ 同步副本组brokerId列表 ], ....... } } Example:
{
"version": 1, "partitions": { "0": [1, 2], "1": [2, 1], "2": [1, 2], } }
说明:紫红色为patitions编号,蓝色为同步副本组brokerId列表
|
2.partition状态信息
/brokers/topics/[topic]/partitions/[0...N] 其中[0..N]表示partition索引号
/brokers/topics/[topic]/partitions/[partitionId]/state
Schema:
"controller_epoch": 表示kafka集群中的中央控制器选举次数, "leader": 表示该partition选举leader的brokerId, "version": 版本编号默认为1, "leader_epoch": 该partition leader选举次数, "isr": [同步副本组brokerId列表] } Example:
"controller_epoch": 1, "leader": 2, "version": 1, "leader_epoch": 0, "isr": [2, 1] } |
3. Broker注册信息
/brokers/ids/[0...N]
每个broker的配置文件中都需要指定一个数字类型的id(全局不可重复),此节点为临时znode(EPHEMERAL)
Schema:
"jmx_port": jmx端口号, "timestamp": kafka broker初始启动时的时间戳, "host": 主机名或ip地址, "version": 版本编号默认为1, "port": kafka broker的服务端端口号,由server.properties中参数port确定 } Example:
"jmx_port": 6061,
"timestamp":"1403061899859" "version": 1, "host": "192.168.1.148", "port": 9092 } |
4. Controller epoch:
/controller_epoch -> int (epoch)
此值为一个数字,kafka集群中第一个broker第一次启动时为1,以后只要集群中center controller中央控制器所在broker变更或挂掉,就会重新选举新的center controller,每次center controller变更controller_epoch值就会 + 1;
5. Controller注册信息:
/controller -> int (broker id of the controller) 存储center controller中央控制器所在kafka broker的信息
Schema:
"version": 版本编号默认为1, "brokerid": kafka集群中broker唯一编号, "timestamp": kafka broker中央控制器变更时的时间戳 } Example:
"version": 1, "brokerid": 3, "timestamp": "1403061802981" } |

a.每个consumer客户端被创建时,会向zookeeper注册自己的信息;
b.此作用主要是为了"负载均衡".
c.同一个Consumer Group中的Consumers,Kafka将相应Topic中的每个消息只发送给其中一个Consumer。
d.Consumer Group中的每个Consumer读取Topic的一个或多个Partitions,并且是唯一的Consumer;
e.一个Consumer group的多个consumer的所有线程依次有序地消费一个topic的所有partitions,如果Consumer group中所有consumer总线程大于partitions数量,则会出现空闲情况;举例说明:kafka集群中创建一个topic为report-log 4 partitions 索引编号为0,1,2,3假如有目前有三个消费者node:注意-->一个consumer中一个消费线程可以消费一个或多个partition.如果每个consumer创建一个consumer thread线程,各个node消费情况如下,node1消费索引编号为0,1分区,node2费索引编号为2,node3费索引编号为3总结 :如果每个consumer创建2个consumer thread线程,各个node消费情况如下(是从consumer node先后启动状态来确定的),node1消费索引编号为0,1分区;node2费索引编号为2,3;node3为空闲状态
从以上可知,Consumer Group中各个consumer是根据先后启动的顺序有序消费一个topic的所有partitions的。如果Consumer Group中所有consumer的总线程数大于partitions数量,则可能consumer thread或consumer会出现空闲状态。
Consumer均衡算法
当一个group中,有consumer加入或者离开时,会触发partitions均衡.均衡的最终目的,是提升topic的并发消费能力.
1) 假如topic1,具有如下partitions: P0,P1,P2,P3
2) 加入group中,有如下consumer: C0,C1
3) 首先根据partition索引号对partitions排序: P0,P1,P2,P3
4) 根据(consumer.id + '-'+ thread序号)排序: C0,C1
5) 计算倍数: M = [P0,P1,P2,P3].size / [C0,C1].size,本例值M=2(向上取整)
6) 然后依次分配partitions: C0 = [P0,P1],C1=[P2,P3],即Ci = [P(i * M),P((i + 1) * M -1)]
6. Consumer注册信息:
每个consumer都有一个唯一的ID(consumerId可以通过配置文件指定,也可以由系统生成),此id用来标记消费者信息.
/consumers/[groupId]/ids/[consumerIdString]
是一个临时的znode,此节点的值为请看consumerIdString产生规则,即表示此consumer目前所消费的topic + partitions列表.
consumerId产生规则:
StringconsumerUuid = null;
if(config.consumerId!=null && config.consumerId)
consumerUuid = consumerId;
else {
String uuid = UUID.randomUUID()
consumerUuid = "%s-%d-%s".format(
InetAddress.getLocalHost.getHostName, System.currentTimeMillis,
uuid.getMostSignificantBits().toHexString.substring(0,8));
}
String consumerIdString = config.groupId + "_" + consumerUuid;
Schema:
"version": 版本编号默认为1, "subscription": { //订阅topic列表 "topic名称": consumer中topic消费者线程数 }, "pattern": "static", "timestamp": "consumer启动时的时间戳" } Example:
{
"version": 1, "subscription": { "open_platform_opt_push_plus1": 5 }, "pattern": "static", "timestamp": "1411294187842" } |
7. Consumer owner:
/consumers/[groupId]/owners/[topic]/[partitionId] -> consumerIdString + threadId索引编号
当consumer启动时,所触发的操作:
a) 首先进行"Consumer Id注册";
b) 然后在"Consumer id 注册"节点下注册一个watch用来监听当前group中其他consumer的"退出"和"加入";只要此znode path下节点列表变更,都会触发此group下consumer的负载均衡.(比如一个consumer失效,那么其他consumer接管partitions).
c) 在"Broker id 注册"节点下,注册一个watch用来监听broker的存活情况;如果broker列表变更,将会触发所有的groups下的consumer重新balance.
8. Consumer offset:
/consumers/[groupId]/offsets/[topic]/[partitionId] -> long (offset)
用来跟踪每个consumer目前所消费的partition中最大的offset
此znode为持久节点,可以看出offset跟group_id有关,以表明当消费者组(consumer group)中一个消费者失效,
重新触发balance,其他consumer可以继续消费.
9. Re-assign partitions
/admin/reassign_partitions
{
"fields":[
{
"name":"version",
"type":"int",
"doc":"version id"
},
{
"name":"partitions",
"type":{
"type":"array",
"items":{
"fields":[
{
"name":"topic",
"type":"string",
"doc":"topic of the partition to be reassigned"
},
{
"name":"partition",
"type":"int",
"doc":"the partition to be reassigned"
},
{
"name":"replicas",
"type":"array",
"items":"int",
"doc":"a list of replica ids"
}
],
}
"doc":"an array of partitions to be reassigned to new replicas"
}
}
]
}
Example:
{
"version": 1,
"partitions":
[
{
"topic": "Foo",
"partition": 1,
"replicas": [0, 1, 3]
}
]
}
|
10. Preferred replication election
/admin/preferred_replica_election
{
"fields":[
{
"name":"version",
"type":"int",
"doc":"version id"
},
{
"name":"partitions",
"type":{
"type":"array",
"items":{
"fields":[
{
"name":"topic",
"type":"string",
"doc":"topic of the partition for which preferred replica election should be triggered"
},
{
"name":"partition",
"type":"int",
"doc":"the partition for which preferred replica election should be triggered"
}
],
}
"doc":"an array of partitions for which preferred replica election should be triggered"
}
}
]
}
例子:
{
"version": 1,
"partitions":
[
{
"topic": "Foo",
"partition": 1
},
{
"topic": "Bar",
"partition": 0
}
]
}
|
11. 删除topics
/admin/delete_topics
Schema:
{
"fields":
[ {"name": "version", "type": "int", "doc": "version id"},
{"name": "topics",
"type": { "type": "array", "items": "string", "doc": "an array of topics to be deleted"}
} ]
}
例子:
{
"version": 1,
"topics": ["foo", "bar"]
}
|
Topic配置
/config/topics/[topic_name]
例子
{
"version": 1,
"config": {
"config.a": "x",
"config.b": "y",
...
}
}
|
3)kafka log4j配置
kafka日志文件分为5种类型,依次为:controller,kafka-request,server,state-change,log-cleaner,不同类型log数据,写到不同文件中:
- kafka.logs.dir=logs
- log4j.rootLogger=INFO, stdout
- log4j.appender.stdout=org.apache.log4j.ConsoleAppender
- log4j.appender.stdout.layout=org.apache.log4j.PatternLayout
- log4j.appender.stdout.layout.ConversionPattern=[%d] %p %m (%c)%n
- log4j.appender.kafkaAppender=org.apache.log4j.DailyRollingFileAppender
- log4j.appender.kafkaAppender.DatePattern='.'yyyy-MM-dd-HH
- log4j.appender.kafkaAppender.File=${kafka.logs.dir}/server.log
- log4j.appender.kafkaAppender.layout=org.apache.log4j.PatternLayout
- log4j.appender.kafkaAppender.layout.ConversionPattern=[%d] %p %m (%c)%n
- log4j.appender.stateChangeAppender=org.apache.log4j.DailyRollingFileAppender
- log4j.appender.stateChangeAppender.DatePattern='.'yyyy-MM-dd-HH
- log4j.appender.stateChangeAppender.File=${kafka.logs.dir}/state-change.log
- log4j.appender.stateChangeAppender.layout=org.apache.log4j.PatternLayout
- log4j.appender.stateChangeAppender.layout.ConversionPattern=[%d] %p %m (%c)%n
- log4j.appender.requestAppender=org.apache.log4j.DailyRollingFileAppender
- log4j.appender.requestAppender.DatePattern='.'yyyy-MM-dd-HH
- log4j.appender.requestAppender.File=${kafka.logs.dir}/kafka-request.log
- log4j.appender.requestAppender.layout=org.apache.log4j.PatternLayout
- log4j.appender.requestAppender.layout.ConversionPattern=[%d] %p %m (%c)%n
- log4j.appender.cleanerAppender=org.apache.log4j.DailyRollingFileAppender
- log4j.appender.cleanerAppender.DatePattern='.'yyyy-MM-dd-HH
- log4j.appender.cleanerAppender.File=log-cleaner.log
- log4j.appender.cleanerAppender.layout=org.apache.log4j.PatternLayout
- log4j.appender.cleanerAppender.layout.ConversionPattern=[%d] %p %m (%c)%n
- log4j.appender.controllerAppender=org.apache.log4j.DailyRollingFileAppender
- log4j.appender.controllerAppender.DatePattern='.'yyyy-MM-dd-HH
- log4j.appender.controllerAppender.File=${kafka.logs.dir}/controller.log
- log4j.appender.controllerAppender.layout=org.apache.log4j.PatternLayout
- log4j.appender.controllerAppender.layout.ConversionPattern=[%d] %p %m (%c)%n
- # Turn on all our debugging info
- #log4j.logger.kafka.producer.async.DefaultEventHandler=DEBUG, kafkaAppender
- #log4j.logger.kafka.client.ClientUtils=DEBUG, kafkaAppender
- #log4j.logger.kafka.perf=DEBUG, kafkaAppender
- #log4j.logger.kafka.perf.ProducerPerformance$ProducerThread=DEBUG, kafkaAppender
- #log4j.logger.org.I0Itec.zkclient.ZkClient=DEBUG
- log4j.logger.kafka=INFO, kafkaAppender
- log4j.logger.kafka.network.RequestChannel$=WARN, requestAppender
- log4j.additivity.kafka.network.RequestChannel$=false
- #log4j.logger.kafka.network.Processor=TRACE, requestAppender
- #log4j.logger.kafka.server.KafkaApis=TRACE, requestAppender
- #log4j.additivity.kafka.server.KafkaApis=false
- log4j.logger.kafka.request.logger=WARN, requestAppender
- log4j.additivity.kafka.request.logger=false
- log4j.logger.kafka.controller=TRACE, controllerAppender
- log4j.additivity.kafka.controller=false
- log4j.logger.kafka.log.LogCleaner=INFO, cleanerAppender
- log4j.additivity.kafka.log.LogCleaner=false
- log4j.logger.kafka.log.Cleaner=INFO, cleanerAppender
- log4j.additivity.kafka.log.Cleaner=false
- log4j.logger.state.change.logger=TRACE, stateChangeAppender
- log4j.additivity.state.change.logger=false
4)kafka replication设计机制
概览:
其中一个broker被选举作为整个集群控制器,他将负责几个方面工作:
1.管理或领导分区变化.
2.create topic,delete topic
3.replicas(执行复制计划,复制partition)
集群控制器做出决定以后,操作信息或状态将永久注册并存储在zookeeper上,并且也可以通过RPC方式发送新的决定操作broker。控制器发布的决定来源真实,他将用于client请求路由和broker的重启或恢复状态。
如果有一个新的broker加入或启动。controller会通过RPC调用发出新的决定。
潜在的优点:
1.当leader发生变化时,更容易集中到一个地方做调试(排除故障)。
2.当leader发生变化时,ZK可以把读取/写状态信息成批广播到其他broker,因此当leader failover的时候会减少broker之间恢复的延迟时间。
3.需要更少的监听器。
4.使用更高效的RPC通信方式,代替在zookeeper中队列实现方式。
潜在的缺点:
需要考虑controller failover
zookeeper中路径列表说明
1.Controller path:存储当前controller信息.
- /controller --> {brokerid} (ephemeral; created by controller)
2.Broker path:存储当前所有活着的brokers信息。
- /brokers/ids/[broker_id] --> host:port (ephemeral; created by admin)
3.存储一个主题的所有分区副本任务。对于每一个副本,我们存储的副本指派一个broker ID。第一个副本是首选的复制品。注意,对于一个给定的分区,在一个broker上有至多一个副本。因此,broker ID可以作副本标识.
- /brokers/topics/[topic]/[partition_id]/leaderAndISR --> {leader_epoc: epoc, leader: broker_id, ISR: {broker1, broker2}}
- 此路径被controller或leader修改,当前leader只修改ISR一部分信息。当更新path需要使用条件同步到zookeeper上。
4.LeaderAndISR path:存储一个分区leader and ISR
- /brokers/topics/[topic]/[partition_id]/leaderAndISR --> {leader_epoc: epoc, leader: broker_id, ISR: {broker1, broker2}}
- 此路径被controller或leader修改,当前leader只修改ISR一部分信息。当更新path需要使用条件同步到zookeeper上。
每当某个管理员操作如下命令成功后,且这个分区迁移到目标broker成功后,源broker上的分区会自动删除。
- /admin/partitions_add/[topic]/[partition_id] --> {broker_id …} (created by admin)
- /admin/partitions_remove/[topic]/[partition_id] (created by admin)
kafka中专有词语解释:
AR(assign replicas):分配副本 ISR(in-sync replicas):在同步中的副本
- Replica { // 一个分区副本信息
- broker_id : int
- partition : Partition //分区信息
- log : Log //本地日志与副本关联信息
- hw : long //最后被commit的message的offset信息
- leo : long // 日志结尾offset
- isLeader : Boolean //是否为该副本的leader
- }
- Partition { //topic名称
- topic : string
- partition_id : int
- leader : Replica // 这个分区的leader副本
- ISR : Set[Replica] // 正在同步中的副本集合
- AR : Set[Replica] // 这个分区的所有副本分配集合
- LeaderAndISRVersionInZK : long // version id of the LeaderAndISR path; used for conditionally update the LeaderAndISR path in ZK
- }
- LeaderAndISRRequest {
- request_type_id : int16 // 当前request的版本
- version_id : int16 // request的版本号
- client_id : int32 // this can be the broker id of the controller
- ack_timeout : int32 // the time in ms to wait for a response
- isInit : byte // whether this is the first command issued by a controller
- leaderAndISRMap : Map[(topic: String, partitionId: int32) => LeaderAndISR) // a map of LeaderAndISR
- }
- LeaderAndISR {
- leader : int32 // leader的broker编号
- leaderEpoc : int32 // leader epoc, incremented on each leadership change
- ISR : Set[int32] // 所有在ISR复制副本的broker集合
- zkVersion : int64 // version of the LeaderAndISR path in ZK
- }
- LeaderAndISRResponse {
- version_id : int16 // 当前request的版本
- responseMap : Map[(topic: String, partitionId: int32) => int16) // error code表
- }
- StopReplicaRequest {
- request_type_id : int16 // request id
- version_id : int16 // 当前request的版本
- client_id : int32 // this can be the broker id of the controller
- ack_timeout : int32 // ack响应时间,单位为毫秒
- stopReplicaSet : Set[(topic: String, partitionId: int)) // 需要停止的分区集合
- }
- StopReplicaResponse {
- version_id : int16 // 当前request的版本
- responseMap : Map[(topic: String, partitionId: int32) => int16) //error code表
- }
5)apache kafka监控系列-监控指标
1、监控目标
1.当系统可能或处于亚健康状态时及时提醒,预防故障发生
2.报警提示 a.短信方式 b.邮件
2、监控内容
2.1 机器监控
Kafka服务器指标
- CPU Load
- Disk IO
- Memory
- 磁盘log.dirs目录下数据文件大小,要有定时清除策略
2.2 JVM监控
主要监控JAVA的 GC time(垃圾回收时间),JAVA的垃圾回收机制对性能的影响比较明显
2.3 Kafka系统监控
1、Kafka总体监控
- zookeeper上/XXX/broker/ids目录下节点数量
- leader 选举频率
2、Kafka Broker监控
- kafka集群中Broker列表,broker运行状况,包括node下线,活跃数量
- Broker是否提供服务
- 数据流量 流入速度,流出速度 (message / byte)
- ISR 收缩频率
3、Kafka Controller监控
- controller存活数目
4、Kafka Producer监控
- producer数量,排队情况
- 请求响应时间
- QPS/分钟
5、Kafka Consumer监控
- consumer队列中排队请求数
- 请求响应时间
- 最近一分钟平均每秒请求数
6、Topic监控
- 数据量大小;
- offset
- 数据流量 流入速度,流出速度 (message / byte)
3.监控指标
3.1 JVM监控
a.通过JMX获取GC time
b.jvm full gc次数
3.2 kafka系统监控
监控数据获取方式
1、生存节点信息可以从zookeeper获取
2、除生存节点 和
a、Broker是否提供服务。
b、Topic数据量大小,
c、Topic的offset 外,其他数据都可以通过JMX获取
6)kafka.common.ConsumerRebalanceFailedException异常解决办法
kafka.common.ConsumerRebalanceFailedException :log-push-record-consumer-group_mobile-pushremind02.lf.xxx.com-1399456594831-99f15e63 can't rebalance after 3 retries
at kafka.consumer.ZookeeperConsumerConnector$ZKRebalancerListener.syncedRebalance(Unknown Source)at kafka.consumer.ZookeeperConsumerConnector.kafka$consumer$ZookeeperConsumerConnector$$reinitializeConsumer(Unknown Source)
at kafka.consumer.ZookeeperConsumerConnector.consume(Unknown Source)
at kafka.javaapi.consumer.ZookeeperConsumerConnector.createMessageStreams(Unknown Source)
at com.xxx.mafka.client.consumer.DefaultConsumerProcessor.getKafkaStreams(DefaultConsumerProcessor.java:149)
at com.xxx.mafka.client.consumer.DefaultConsumerProcessor.recvMessage(DefaultConsumerProcessor.java:63)
at com.xxx.service.mobile.push.kafka.MafkaPushRecordConsumer.main(MafkaPushRecordConsumer.java:22)
at com.xxx.service.mobile.push.Bootstrap.main(Bootstrap.java:34)
出现以上问题原因分析:
同一个消费者组(consumer group)有多个consumer先后启动,就是一个消费者组内有多个consumer同时负载消费多个partition数据.
解决办法:
1.配置zk问题(kafka的consumer配置)
zookeeper.session.timeout.ms=5000
zookeeper.connection.timeout.ms=10000
zookeeper.sync.time.ms=2000
在使用高级API过程中,一般出现这个问题是zookeeper.sync.time.ms时间间隔配置过短,不排除有其他原因引起,但笔者遇到一般是这个原因。
给大家解释一下原因:一个消费者组中(consumer数量<partitions数量)每当有consumer发送变化,会触发负载均衡。第一件事就是释放当consumer资源,无则免之,调用ConsumerFetcherThread关闭并释放当前kafka broker所有连接,释放当前消费的partitons,实际就是删除临时节点(/xxx/consumer/owners/topic-xxx/partitions[0-n]),所有同一个consumer group内所有consumer通过计算获取本consumer要消费的partitions,然后本consumer注册相应临时节点卡位,代表我拥有该partition的消费所有权,其他consumer不能使用。
如果大家理解上面解释,下面就更容易了,当consumer调用Rebalance时,它是按照时间间隔和最大次数采取失败重试原则,每当获取partitions失败后会重试获取。举个例子,假如某个公司有个会议,B部门在某个时间段预订该会议室,但是时间到了去会议室看时,发现A部门还在使用。这时B部门只有等待了,每隔一段时间去询问一下。如果时间过于频繁,则会议室一直会处于占用状态,如果时间间隔设置长点,可能去个2次,A部门就让出来了。
同理,当新consumer加入重新触发rebalance时,已有(old)的consumer会重新计算并释放占用partitions,但是会消耗一定处理时间,此时新(new)consumer去抢占该partitions很有可能就会失败。我们假设设置足够old consumer释放资源的时间,就不会出现这个问题。
zookeeper.sync.time.ms时间设置过短就会导致old consumer还没有来得及释放资源,new consumer重试失败多次到达阀值就退出了。
zookeeper.sync.time.ms设置时间阀值,要考虑网络环境,服务器性能等因素在内综合衡量。
kafka zk节点存储,请参考:kafka在zookeeper中存储结构
7)kafak安装与使用
kafak安装与使用
1.前言
学习kafka的基础是先把kafka系统部署起来,然后简单的使用它,从直观上感觉它,然后逐步的深入了解它。
本文介绍了kafka部署方法,包括配置,安装和简单的使用。
2.kafka下载和安装
kafka版本一直在更新,且每次更新,变化均比较大,如配置文件有改动,kafka 0.7到0.8.1版本变化很大,包括加入,支持集群内复制,支持多个数据目录,请求处理改为异步,实现partition动态管理,基于时间的日志段删除
2.1下载地址:
https://www.apache.org/dyn/closer.cgi?path=/kafka/0.8.1.1/kafka_2.10-0.8.1.1.tgz。
kafka目录结构
如 图-1

说明:涂黑部分为我自己创建文件夹
| 目录 |
说明 |
| bin |
操作kafka的可执行脚本,还包含windows下脚本 |
| config |
配置文件所在目录 |
| libs |
依赖库目录 |
| logs |
日志数据目录,目录kafka把server端日志分为5种类型,分为:server,request,state,log-cleaner,controller |
2.1 安装以及启动kafka
步骤1:
lizhitao@localhost:~$ cd kafka_2.10-0.8.1.1.tgz
步骤2:
步骤3:
步骤4: 启动服务
lizhitao@localhost:~$ bin/kafka-server-start.sh config/server.properties
[2014-04-16 15:01:47,028] INFO Verifying properties (kafka.utils.VerifiableProperties)
[2014-04-16 15:01:47,051] INFO Property socket.send.buffer.bytes is overridden to 1048576 (kafka.utils.VerifiableProperties)
...
步骤5:创建topic
lizhitao@localhost:~$ bin/kafka-topics.sh --create --zookeeper localhost:2181 --replication-factor 1 --partitions 1 --topic test
步骤6:验证topic是否创建成功
lizhitao@localhost:~$ bin/kafka-topics.sh --list --zookeeper localhost:2181
test
Alternatively, instead of manually creating topics you can also configure your brokers to auto-create topics when a non-existent topic is published to.
步骤7:发送一些消息验证,在console模式下,启动producer
bin/kafka-console-producer.sh --broker-list localhost:9092 --topic test
This is a message
This is another message
步骤7:启动一个consumer
lizhitao@localhost:~$ bin/kafka-console-consumer.sh --zookeeper localhost:2181 --topic test --from-beginning
This is a message
This is another message
3.配置kafka集群模式,需要由多个broker组成
步骤1:
因为需要在同一个目录(config)下配置多个server.properties,操作步骤如下:
lizhitao@localhost:~$ cp config/server.properties config/server-1.properties
lizhitao@localhost:~$ cp config/server.properties config/server-2.properties
步骤2:
需要编辑并设置如下文件属性:
config/server-1.properties:
broker.id=1
port=9093
log.dir=/tmp/kafka-logs-1
config/server-2.properties:
broker.id=2
port=9094
log.dir=/tmp/kafka-logs-2
启动服务
lizhitao@localhost:~$ bin/kafka-server-start.sh config/server-1.properties &
...
lizhitao@localhost:~$ bin/kafka-server-start.sh config/server-2.properties &
...
步骤3:
创建topic
lizhitao@localhost:~$ bin/kafka-topics.sh --create --zookeeper localhost:2181 --replication-factor 3 --partitions 1 --topic my-replicated-topic
.....topic created success....
lizhitao@localhost:~$ bin/kafka-topics.sh --describe --zookeeper localhost:2181 --topic my-replicated-topic
Topic:my-replicated-topic PartitionCount:1 ReplicationFactor:3Configs:
Topic: my-replicated-topic Partition: 0Leader: 1Replicas: 1,2,0Isr: 1,2,0
描述topic中分区,同步副本情况
lizhitao@localhost:~$ bin/kafka-topics.sh --describe --zookeeper localhost:2181 --topic test
Topic:test PartitionCount:1 ReplicationFactor:1Configs:
Topic: test Partition: 0 Leader: 0Replicas: 0Isr: 0
步骤4:作为生产者发送消息
lizhitao@localhost:~$ bin/kafka-console-producer.sh --broker-list localhost:9092 --topic my-replicated-topic
...
my test message 1
my test message 2
步骤5:消费topic数据
lizhitao@localhost:~$ bin/kafka-console-consumer.sh --zookeeper localhost:2181 --from-beginning --topic my-replicated-topic
...
my test message 1
my test message 2
步骤6:
检查consumer offset位置
lizhitao@localhost:~$ bin/kafka-run-class.sh kafka.tools.ConsumerOffsetChecker --zkconnect localhost:2181 --group test
Group Topic Pid Offset logSize Lag Owner
my-group my-topic 0 0 0 0 test_jkreps-mn-1394154511599-60744496-0
my-group my-topic 1 0 0 0 test_jkreps-mn-1394154521217-1a0be913-0
每个kafka broker中配置文件server.properties默认必须配置的属性如下:
- broker.id=0
- num.network.threads=2
- num.io.threads=8
- socket.send.buffer.bytes=1048576
- socket.receive.buffer.bytes=1048576
- socket.request.max.bytes=104857600
- log.dirs=/tmp/kafka-logs
- num.partitions=2
- log.retention.hours=168
- log.segment.bytes=536870912
- log.retention.check.interval.ms=60000
- log.cleaner.enable=false
- zookeeper.connect=localhost:2181
- zookeeper.connection.timeout.ms=1000000
server.properties中所有配置参数说明(解释)如下列表:
| 参数 |
说明(解释) |
| broker.id =0 |
每一个broker在集群中的唯一表示,要求是正数。当该服务器的IP地址发生改变时,broker.id没有变化,则不会影响consumers的消息情况 |
| log.dirs=/data/kafka-logs |
kafka数据的存放地址,多个地址的话用逗号分割,多个目录分布在不同磁盘上可以提高读写性能 /data/kafka-logs-1,/data/kafka-logs-2 |
| port =9092 |
broker server服务端口 |
| message.max.bytes =6525000 |
表示消息体的最大大小,单位是字节 |
| num.network.threads =4 |
broker处理消息的最大线程数,一般情况下不需要去修改 |
| num.io.threads =8 |
broker处理磁盘IO的线程数,数值应该大于你的硬盘数 |
| background.threads =4 |
一些后台任务处理的线程数,例如过期消息文件的删除等,一般情况下不需要去做修改 |
| queued.max.requests =500 |
等待IO线程处理的请求队列最大数,若是等待IO的请求超过这个数值,那么会停止接受外部消息,应该是一种自我保护机制。 |
| host.name |
broker的主机地址,若是设置了,那么会绑定到这个地址上,若是没有,会绑定到所有的接口上,并将其中之一发送到ZK,一般不设置 |
| socket.send.buffer.bytes=100*1024 |
socket的发送缓冲区,socket的调优参数SO_SNDBUFF |
| socket.receive.buffer.bytes =100*1024 |
socket的接受缓冲区,socket的调优参数SO_RCVBUFF |
| socket.request.max.bytes =100*1024*1024 |
socket请求的最大数值,防止serverOOM,message.max.bytes必然要小于socket.request.max.bytes,会被topic创建时的指定参数覆盖 |
| log.segment.bytes =1024*1024*1024 |
topic的分区是以一堆segment文件存储的,这个控制每个segment的大小,会被topic创建时的指定参数覆盖 |
| log.roll.hours =24*7 |
这个参数会在日志segment没有达到log.segment.bytes设置的大小,也会强制新建一个segment会被 topic创建时的指定参数覆盖 |
| log.cleanup.policy = delete |
日志清理策略选择有:delete和compact主要针对过期数据的处理,或是日志文件达到限制的额度,会被 topic创建时的指定参数覆盖 |
| log.retention.minutes=3days |
数据存储的最大时间超过这个时间会根据log.cleanup.policy设置的策略处理数据,也就是消费端能够多久去消费数据 log.retention.bytes和log.retention.minutes任意一个达到要求,都会执行删除,会被topic创建时的指定参数覆盖 |
| log.retention.bytes=-1 |
topic每个分区的最大文件大小,一个topic的大小限制 = 分区数*log.retention.bytes。-1没有大小限log.retention.bytes和log.retention.minutes任意一个达到要求,都会执行删除,会被topic创建时的指定参数覆盖 |
| log.retention.check.interval.ms=5minutes |
文件大小检查的周期时间,是否处罚 log.cleanup.policy中设置的策略 |
| log.cleaner.enable=false |
是否开启日志压缩 |
| log.cleaner.threads = 2 |
日志压缩运行的线程数 |
| log.cleaner.io.max.bytes.per.second=None |
日志压缩时候处理的最大大小 |
| log.cleaner.dedupe.buffer.size=500*1024*1024 |
日志压缩去重时候的缓存空间,在空间允许的情况下,越大越好 |
| log.cleaner.io.buffer.size=512*1024 |
日志清理时候用到的IO块大小一般不需要修改 |
| log.cleaner.io.buffer.load.factor =0.9 |
日志清理中hash表的扩大因子一般不需要修改 |
| log.cleaner.backoff.ms =15000 |
检查是否处罚日志清理的间隔 |
| log.cleaner.min.cleanable.ratio=0.5 |
日志清理的频率控制,越大意味着更高效的清理,同时会存在一些空间上的浪费,会被topic创建时的指定参数覆盖 |
| log.cleaner.delete.retention.ms =1day |
对于压缩的日志保留的最长时间,也是客户端消费消息的最长时间,同log.retention.minutes的区别在于一个控制未压缩数据,一个控制压缩后的数据。会被topic创建时的指定参数覆盖 |
| log.index.size.max.bytes =10*1024*1024 |
对于segment日志的索引文件大小限制,会被topic创建时的指定参数覆盖 |
| log.index.interval.bytes =4096 |
当执行一个fetch操作后,需要一定的空间来扫描最近的offset大小,设置越大,代表扫描速度越快,但是也更好内存,一般情况下不需要搭理这个参数 |
| log.flush.interval.messages=None |
log文件”sync”到磁盘之前累积的消息条数,因为磁盘IO操作是一个慢操作,但又是一个”数据可靠性"的必要手段,所以此参数的设置,需要在"数据可靠性"与"性能"之间做必要的权衡.如果此值过大,将会导致每次"fsync"的时间较长(IO阻塞),如果此值过小,将会导致"fsync"的次数较多,这也意味着整体的client请求有一定的延迟.物理server故障,将会导致没有fsync的消息丢失. |
| log.flush.scheduler.interval.ms =3000 |
检查是否需要固化到硬盘的时间间隔 |
| log.flush.interval.ms = None |
仅仅通过interval来控制消息的磁盘写入时机,是不足的.此参数用于控制"fsync"的时间间隔,如果消息量始终没有达到阀值,但是离上一次磁盘同步的时间间隔达到阀值,也将触发. |
| log.delete.delay.ms =60000 |
文件在索引中清除后保留的时间一般不需要去修改 |
| log.flush.offset.checkpoint.interval.ms =60000 |
控制上次固化硬盘的时间点,以便于数据恢复一般不需要去修改 |
| auto.create.topics.enable =true |
是否允许自动创建topic,若是false,就需要通过命令创建topic |
| default.replication.factor =1 |
是否允许自动创建topic,若是false,就需要通过命令创建topic |
| num.partitions =1 |
每个topic的分区个数,若是在topic创建时候没有指定的话会被topic创建时的指定参数覆盖 |
|
|
|
| 以下是kafka中Leader,replicas配置参数 |
|
| controller.socket.timeout.ms =30000 |
partition leader与replicas之间通讯时,socket的超时时间 |
| controller.message.queue.size=10 |
partition leader与replicas数据同步时,消息的队列尺寸 |
| replica.lag.time.max.ms =10000 |
replicas响应partition leader的最长等待时间,若是超过这个时间,就将replicas列入ISR(in-sync replicas),并认为它是死的,不会再加入管理中 |
| replica.lag.max.messages =4000 |
如果follower落后与leader太多,将会认为此follower[或者说partition relicas]已经失效 ##通常,在follower与leader通讯时,因为网络延迟或者链接断开,总会导致replicas中消息同步滞后 ##如果消息之后太多,leader将认为此follower网络延迟较大或者消息吞吐能力有限,将会把此replicas迁移 ##到其他follower中. ##在broker数量较少,或者网络不足的环境中,建议提高此值. |
| replica.socket.timeout.ms=30*1000 |
follower与leader之间的socket超时时间 |
| replica.socket.receive.buffer.bytes=64*1024 |
leader复制时候的socket缓存大小 |
| replica.fetch.max.bytes =1024*1024 |
replicas每次获取数据的最大大小 |
| replica.fetch.wait.max.ms =500 |
replicas同leader之间通信的最大等待时间,失败了会重试 |
| replica.fetch.min.bytes =1 |
fetch的最小数据尺寸,如果leader中尚未同步的数据不足此值,将会阻塞,直到满足条件 |
| num.replica.fetchers=1 |
leader进行复制的线程数,增大这个数值会增加follower的IO |
| replica.high.watermark.checkpoint.interval.ms =5000 |
每个replica检查是否将最高水位进行固化的频率 |
| controlled.shutdown.enable =false |
是否允许控制器关闭broker ,若是设置为true,会关闭所有在这个broker上的leader,并转移到其他broker |
| controlled.shutdown.max.retries =3 |
控制器关闭的尝试次数 |
| controlled.shutdown.retry.backoff.ms =5000 |
每次关闭尝试的时间间隔 |
| leader.imbalance.per.broker.percentage =10 |
leader的不平衡比例,若是超过这个数值,会对分区进行重新的平衡 |
| leader.imbalance.check.interval.seconds =300 |
检查leader是否不平衡的时间间隔 |
| offset.metadata.max.bytes |
客户端保留offset信息的最大空间大小 |
| kafka中zookeeper参数配置 |
|
| zookeeper.connect = localhost:2181 |
zookeeper集群的地址,可以是多个,多个之间用逗号分割hostname1:port1,hostname2:port2,hostname3:port3 |
| zookeeper.session.timeout.ms=6000 |
ZooKeeper的最大超时时间,就是心跳的间隔,若是没有反映,那么认为已经死了,不易过大 |
| zookeeper.connection.timeout.ms =6000 |
ZooKeeper的连接超时时间 |
| zookeeper.sync.time.ms =2000 |
ZooKeeper集群中leader和follower之间的同步实际那 |
9)apache kafka的consumer初始化时获取不到消息
问题
发现一个问题,如果使用的是一个高级的kafka接口 那么默认的情况下如果某个topic没有变化 则consumer消费不到消息 比如某个消息生产了2w条,此时producer不再生产消息,然后另外一个consumer启动,此时拿不到消息.
原因解释:
auto.offset.reset:如果zookeeper没有offset值或offset值超出范围。那么就给个初始的offset。有smallest、largest、anything可选,分别表示给当前最小的offset、当前最大的offset、抛异常。默认largest
默认值:auto.offset.reset=largest
10)Kafka Producer处理逻辑
Kafka Producer处理逻辑
Kafka Producer产生数据发送给Kafka Server,具体的分发逻辑及负载均衡逻辑,全部由producer维护。
Kafka结构图
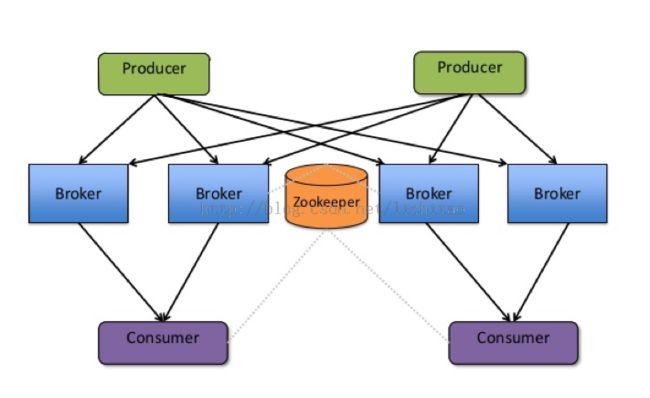
Kafka Producer默认调用逻辑

默认Partition逻辑
1、没有key时的分发逻辑
每隔 topic.metadata.refresh.interval.ms 的时间,随机选择一个partition。这个时间窗口内的所有记录发送到这个partition。
发送数据出错后也会重新选择一个partition
2、根据key分发
对key求hash,然后对partition数量求模
| Utils.abs(key.hashCode) % numPartitions |
如何获取Partition的leader信息(元数据)
决定好发送到哪个Partition后,需要明确该Partition的leader是哪台broker才能决定发送到哪里。
具体实现位置
| kafka.client.ClientUtils#fetchTopicMetadata |
实现方案
1、从broker获取Partition的元数据。由于Kafka所有broker存有所有的元数据,所以任何一个broker都可以返回所有的元数据
2、broker选取策略:将broker列表随机排序,从首个broker开始访问,如果出错,访问下一个
3、出错处理:出错后向下一个broker请求元数据
注意
- Producer是从broker获取元数据的,并不关心zookeeper。
- broker发生变化后,producer获取元数据的功能不能动态变化。
- 获取元数据时使用的broker列表由producer的配置中的 metadata.broker.list 决定。该列表中的机器只要有一台正常服务,producer就能获取元数据。
- 获取元数据后,producer可以写数据到非 metadata.broker.list 列表中的broker
错误处理
producer的send函数默认没有返回值。出错处理有EventHandler实现。
DefaultEventHandler的错误处理如下:
- 获取出错的数据
- 等待一个间隔时间,由配置 retry.backoff.ms 决定这段时间长短
- 重新获取元数据
- 重新发送数据
出错重试次数由配置 message.send.max.retries 决定
所有重试全部失败时,DefaultEventHandler会抛出异常。代码如下
- if(outstandingProduceRequests.size >0) {
- producerStats.failedSendRate.mark()
- val correlationIdEnd = correlationId.get()
- error("Failed to send requests for topics %s with correlation ids in [%d,%d]"
- .format(outstandingProduceRequests.map(_.topic).toSet.mkString(","),
- correlationIdStart, correlationIdEnd-1))
- thrownewFailedToSendMessageException("Failed to send messages after "+ config.messageSendMaxRetries +" tries.",null)
- }
11)apache kafka源代码工程环境搭建(IDEA)
1.gradle安装
2.下载apache kafka源代码
3.用gradle构建产生IDEA工程文件

4.项目导入到IDEA工程中

5.IDEA中查看源码工程

6.Kafka启动时,参数设置

7.log4j.properties文件路径设置

- [2014-05-24 23:45:31,965] INFO Verifying properties (kafka.utils.VerifiableProperties)
- [2014-05-24 23:45:32,009] INFO Property broker.id is overridden to 9 (kafka.utils.VerifiableProperties)
- [2014-05-24 23:45:32,009] INFO Property log.cleaner.enable is overridden to false (kafka.utils.VerifiableProperties)
- [2014-05-24 23:45:32,009] INFO Property log.dirs is overridden to /Users/lizhitao/kafka-logs (kafka.utils.VerifiableProperties)
- [2014-05-24 23:45:32,009] INFO Property log.retention.check.interval.ms is overridden to 60000 (kafka.utils.VerifiableProperties)
- [2014-05-24 23:45:32,010] INFO Property log.retention.hours is overridden to 168 (kafka.utils.VerifiableProperties)
- [2014-05-24 23:45:32,010] INFO Property log.segment.bytes is overridden to 536870912 (kafka.utils.VerifiableProperties)
- [2014-05-24 23:45:32,010] INFO Property num.io.threads is overridden to 8 (kafka.utils.VerifiableProperties)
- [2014-05-24 23:45:32,010] INFO Property num.network.threads is overridden to 2 (kafka.utils.VerifiableProperties)
- [2014-05-24 23:45:32,010] INFO Property num.partitions is overridden to 2 (kafka.utils.VerifiableProperties)
- [2014-05-24 23:45:32,010] INFO Property port is overridden to 9092 (kafka.utils.VerifiableProperties)
- [2014-05-24 23:45:32,010] INFO Property socket.receive.buffer.bytes is overridden to 1048576 (kafka.utils.VerifiableProperties)
- [2014-05-24 23:45:32,011] INFO Property socket.request.max.bytes is overridden to 104857600 (kafka.utils.VerifiableProperties)
- [2014-05-24 23:45:32,011] INFO Property socket.send.buffer.bytes is overridden to 1048576 (kafka.utils.VerifiableProperties)
- [2014-05-24 23:45:32,011] INFO Property zookeeper.connect is overridden to 192.168.2.225:2181,192.168.2.225:2182,192.168.2.225:2183 (kafka.utils.VerifiableProperties)
- [2014-05-24 23:45:32,011] INFO Property zookeeper.connection.timeout.ms is overridden to 1000000 (kafka.utils.VerifiableProperties)
- [2014-05-24 23:45:32,032] INFO [Kafka Server 9], starting (kafka.server.KafkaServer)
- [2014-05-24 23:45:32,036] INFO [Kafka Server 9], Connecting to zookeeper on 192.168.2.225:2181,192.168.2.225:2182,192.168.2.225:2183 (kafka.server.KafkaServer)
- [2014-05-24 23:45:32,045] INFO Starting ZkClient event thread. (org.I0Itec.zkclient.ZkEventThread)
- [2014-05-24 23:45:32,370] INFO Client environment:zookeeper.version=3.3.3-1203054, built on 11/17/2011 05:47 GMT (org.apache.zookeeper.ZooKeeper)
- [2014-05-24 23:45:32,370] INFO Client environment:host.name=192.168.2.104 (org.apache.zookeeper.ZooKeeper)
- [2014-05-24 23:45:32,370] INFO Client environment:java.version=1.7.0_55 (org.apache.zookeeper.ZooKeeper)
- [2014-05-24 23:45:32,370] INFO Client environment:java.vendor=Oracle Corporation (org.apache.zookeeper.ZooKeeper)
- [2014-05-24 23:45:32,370] INFO Client environment:java.home=/Library/Java/JavaVirtualMachines/jdk1.7.0_55.jdk/Contents/Home/jre (org.apache.zookeeper.ZooKeeper)
- [2014-05-24 23:45:32,370] INFO Client environment:java.class.path=/Library/Java/JavaVirtualMachines/jdk1.7.0_55.jdk/Contents/Home/lib/ant-javafx.jar:/Library/Java/JavaVirtualMachines/jdk1.7.0_55.jdk/Contents/Home/lib/dt.jar:/Library/Java/JavaVirtualMachines/jdk1.7.0_55.jdk/Contents/Home/lib/javafx-doclet.jar:/Library/Java/JavaVirtualMachines/jdk1.7.0_55.jdk/Contents/Home/lib/javafx-mx.jar:/Library/Java/JavaVirtualMachines/jdk1.7.0_55.jdk/Contents/Home/lib/jconsole.jar:/Library/Java/JavaVirtualMachines/jdk1.7.0_55.jdk/Contents/Home/lib/sa-jdi.jar:/Library/Java/JavaVirtualMachines/jdk1.7.0_55.jdk/Contents/Home/lib/tools.jar:/Library/Java/JavaVirtualMachines/jdk1.7.0_55.jdk/Contents/Home/jre/lib/charsets.jar:/Library/Java/JavaVirtualMachines/jdk1.7.0_55.jdk/Contents/Home/jre/lib/deploy.jar:/Library/Java/JavaVirtualMachines/jdk1.7.0_55.jdk/Contents/Home/jre/lib/htmlconverter.jar:/Library/Java/JavaVirtualMachines/jdk1.7.0_55.jdk/Contents/Home/jre/lib/javaws.jar:/Library/Java/JavaVirtualMachines/jdk1.7.0_55.jdk/Contents/Home/jre/lib/jce.jar:/Library/Java/JavaVirtualMachines/jdk1.7.0_55.jdk/Contents/Home/jre/lib/jfr.jar:/Library/Java/JavaVirtualMachines/jdk1.7.0_55.jdk/Contents/Home/jre/lib/jfxrt.jar:/Library/Java/JavaVirtualMachines/jdk1.7.0_55.jdk/Contents/Home/jre/lib/jsse.jar:/Library/Java/JavaVirtualMachines/jdk1.7.0_55.jdk/Contents/Home/jre/lib/management-agent.jar:/Library/Java/JavaVirtualMachines/jdk1.7.0_55.jdk/Contents/Home/jre/lib/plugin.jar:/Library/Java/JavaVirtualMachines/jdk1.7.0_55.jdk/Contents/Home/jre/lib/resources.jar:/Library/Java/JavaVirtualMachines/jdk1.7.0_55.jdk/Contents/Home/jre/lib/rt.jar:/Library/Java/JavaVirtualMachines/jdk1.7.0_55.jdk/Contents/Home/jre/lib/ext/dnsns.jar:/Library/Java/JavaVirtualMachines/jdk1.7.0_55.jdk/Contents/Home/jre/lib/ext/localedata.jar:/Library/Java/JavaVirtualMachines/jdk1.7.0_55.jdk/Contents/Home/jre/lib/ext/sunec.jar:/Library/Java/JavaVirtualMachines/jdk1.7.0_55.jdk/Contents/Home/jre/lib/ext/sunjce_provider.jar:/Library/Java/JavaVirtualMachines/jdk1.7.0_55.jdk/Contents/Home/jre/lib/ext/sunpkcs11.jar:/Library/Java/JavaVirtualMachines/jdk1.7.0_55.jdk/Contents/Home/jre/lib/ext/zipfs.jar:/Users/lizhitao/mt_wp/open_source/kafka-platform/kafka-0.8.1-src/out/production/core:/Users/lizhitao/.gradle/caches/modules-2/files-2.1/org.scala-lang/scala-library/2.8.0/95bf967bf2e0a26727736228bba3451f4dd3e5b9/scala-library-2.8.0.jar:/Users/lizhitao/.gradle/caches/modules-2/files-2.1/org.apache.zookeeper/zookeeper/3.3.4/6471e17c92181da9e143559c4c4779925a5e6eb0/zookeeper-3.3.4.jar:/Users/lizhitao/.gradle/caches/modules-2/files-2.1/com.101tec/zkclient/0.3/dedcf2b53fb742adba7080ac3aed781694ba616e/zkclient-0.3.jar:/Users/lizhitao/.gradle/caches/modules-2/files-2.1/com.yammer.metrics/metrics-core/2.2.0/f82c035cfa786d3cbec362c38c22a5f5b1bc8724/metrics-core-2.2.0.jar:/Users/lizhitao/.gradle/caches/modules-2/files-2.1/com.yammer.metrics/metrics-annotation/2.2.0/62962b54c490a95c0bb255fa93b0ddd6cc36dd4b/metrics-annotation-2.2.0.jar:/Users/lizhitao/.gradle/caches/modules-2/files-2.1/net.sf.jopt-simple/jopt-simple/3.2/d625f12ba08083c8c16dcedd5396ec730e9e77ab/jopt-simple-3.2.jar:/Users/lizhitao/.gradle/caches/modules-2/files-2.1/org.xerial.snappy/snappy-java/1.0.5/10cb4550360a0ec6b80f09a5209d00b6058e82bf/snappy-java-1.0.5.jar:/Users/lizhitao/.gradle/caches/modules-2/files-2.1/log4j/log4j/1.2.15/f0a0d2e29ed910808c33135a3a5a51bba6358f7b/log4j-1.2.15.jar:/Users/lizhitao/.gradle/caches/modules-2/files-2.1/org.slf4j/slf4j-api/1.7.2/81d61b7f33ebeab314e07de0cc596f8e858d97/slf4j-api-1.7.2.jar:/Applications/IntelliJ IDEA 12.app/lib/idea_rt.jar (org.apache.zookeeper.ZooKeeper)
- [2014-05-24 23:45:32,370] INFO Client environment:java.library.path=/Users/lizhitao/Library/Java/Extensions:/Library/Java/Extensions:/Network/Library/Java/Extensions:/System/Library/Java/Extensions:/usr/lib/java:. (org.apache.zookeeper.ZooKeeper)
- [2014-05-24 23:45:32,370] INFO Client environment:java.io.tmpdir=/var/folders/pn/qjf0v4k52mq965jxjd72hlx00000gp/T/ (org.apache.zookeeper.ZooKeeper)
- [2014-05-24 23:45:32,370] INFO Client environment:java.compiler=<NA> (org.apache.zookeeper.ZooKeeper)
- [2014-05-24 23:45:32,370] INFO Client environment:os.name=Mac OS X (org.apache.zookeeper.ZooKeeper)
- [2014-05-24 23:45:32,370] INFO Client environment:os.arch=x86_64 (org.apache.zookeeper.ZooKeeper)
- [2014-05-24 23:45:32,371] INFO Client environment:os.version=10.9.2 (org.apache.zookeeper.ZooKeeper)
- [2014-05-24 23:45:32,371] INFO Client environment:user.name=lizhitao (org.apache.zookeeper.ZooKeeper)
- [2014-05-24 23:45:32,371] INFO Client environment:user.home=/Users/lizhitao (org.apache.zookeeper.ZooKeeper)
- [2014-05-24 23:45:32,371] INFO Client environment:user.dir=/Users/lizhitao/mt_wp/open_source/kafka-platform/kafka-0.8.1-src (org.apache.zookeeper.ZooKeeper)
- [2014-05-24 23:45:32,372] INFO Initiating client connection, connectString=192.168.2.225:2181,192.168.2.225:2182,192.168.2.225:2183 sessionTimeout=6000 watcher=org.I0Itec.zkclient.ZkClient@6e739617 (org.apache.zookeeper.ZooKeeper)
- [2014-05-24 23:45:32,387] INFO Opening socket connection to server /192.168.2.225:2181 (org.apache.zookeeper.ClientCnxn)
- [2014-05-24 23:45:32,393] ERROR Unable to open socket to 192.168.2.225/192.168.2.225:2181 (org.apache.zookeeper.ClientCnxn)
12)apache kafka监控系列-KafkaOffsetMonitor
概览
最近kafka server消息服务上线了,基于jmx指标参数也写到zabbix中了,但总觉得缺少点什么东西,可视化可操作的界面。zabbix中数据比较分散,不能集中看整个集群情况。或者一个cluster中broker列表,自己写web-console比较耗时耗力,用原型工具画了一些管理界面东西,关键自己也不前端方面技术,这方面比较薄弱。这不开源社区提供了kafka的web管理平台KafkaOffsetMonitor.就迅速拿过来运行。大家不要着急,马上娓娓道来。
说明:
这个应用程序来实时监控你kafka服务的consumer以及他们在partition中的offset(偏移)。
你可以浏览当前的消费者组,每个topic的所有partition的消费情况都可以一览无余。这其实是很有用得,从这里你很快知道每个partition的message是否很快被消费(没有阻塞)。他能指导你(kafka producer和consumer)优化代码。
这个web管理平台保留的partition offset和consumer滞后的历史数据,所以你可以很轻易了解这几天consumer消费情况。
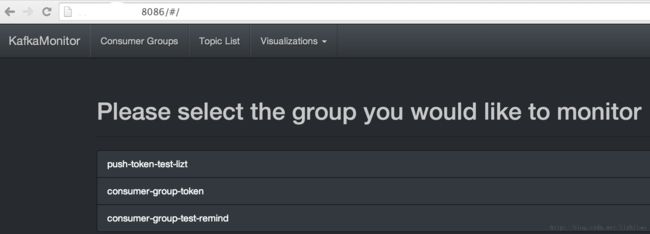
KafkaOffsetMonitor功能:
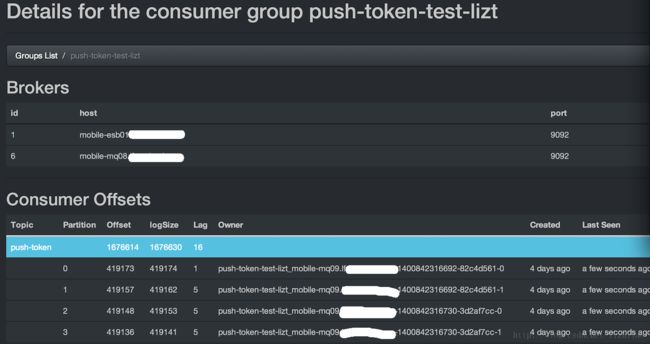
1.从标题都可以看出来,Kafka Offset Monitor,是对consumer消费情况进行监控,并能列出每个consumer offset,滞后数据。
2.消费者组列表
3.每个topic的所有parition列表(topic,pid,offset,logSize,lag,owner)
4.查看topic的历史消费信息.
虽然功能覆盖面不全,但是很实用。
1.下载
KafkaOffsetMonitor
百度云下载(网速快)
百度云KafkaOffsetMonitor下载
说明:百度云下载为修改版本,因为KafkaOffsetMonitor中有些资源文件(css,js)是访问外网的,特别是有访问google资源,大家都懂的,经常不能访问。建议下载修改版
2.安装
KafkaOffsetMonitor运行比较简单,因为所有运行文件,资源文件,jar文件都打包到KafkaOffsetMonitor-assembly-0.2.0.jar了,直接运行就可以,这种方式太棒了。既不用编译也不用配置,呵呵,也不是绝对不配置。
a.新建一个目录kafka-offset-console,然后把jar拷贝到该目录下.
b.新建脚本,因为您可能不是一个kafka集群。用脚本可以启动多个
lizhitao@users-MacBook-Pro: vim mobile_start_en.sh
#!/bin/bashjava -Xms512M -Xmx512M -Xss1024K -XX:PermSize=256m -XX:MaxPermSize=512m -cp KafkaOffsetMonitor-assembly-0.2.0.jar \ com.quantifind.kafka.offsetapp.OffsetGetterWeb \ --zk 192.168.2.101:2181,192.168.2.102:2182,192.168.2.103:2181/config/mobile/xxx \ --port 8086 \ --refresh 10.seconds \ --retain 7.days 1>mobile-logs/stdout.log 2>mobile-logs/stderr.log &
注意:/config/mobile/xxx 表示zk的根目录,需要手工创建,也可以不设置
3.运行
lizhitao@users-MacBook-Pro: chmod +x mobile_start_en.sh
lizhitao@users-MacBook-Pro: ./mobile_start_en.sh
serving resources from: jar:file:/opt/xxx/kafka-offset-console/KafkaOffsetMonitor-assembly-0.2.0.jar!/offsetapp
6 演示截图:
消费者组列表
topic的所有partiton消费情况列表
kafka正在运行的topic

kafka集群中topic列表
kafka集群中broker列表

13)Kafka Controller设计机制
在kafka集群中,其中一个broker server作为中央控制器,负责管理分区和副本状态并执行管理着这些分区的重新分配。下面说明如何通过中央控制器操作分区和副本的状态。
名词解释:
isr:同步副本组
OfflinePartitionLeaderSelector:分区下线后新的领导者选举
OAR:老的分配副本
PartitionStateChange:
其有效状态如下:
- NonExistentPartition: 这种状态表明该分区从来没有创建过或曾经创建过后来又删除了。
- NewPartition:创建分区后,分区处于NewPartition状态。在这种状态下,分区副本应该分配给它,但还没有领导者/同步复制组。
- OnlinePartition:一旦一个分区领导者被选出,就会为在线分区状态。
- OfflinePartition:如果分区领导者成功选举后,当领导者分区崩溃或挂了,分区状态转变下线分区状态。
其有效的状态转移如下:
NonExistentPartition -> NewPartition
1.群集中央控制器根据计算规则,从zk中读取分区信息,创建新分区和副本。
NewPartition -> OnlinePartition
1.分配第一个活着的副本作为分区领导者,并且该分区所有副本作为一个同步复制组,写领导者和同步副本组数据到zk中。
2.对于这个分区,发送LeaderAndIsr请求给每一个副本分区和并发送UpdateMetadata请求到每个活者的broker server。
OnlinePartition,OfflinePartition -> OnlinePartition
1.对于这个分区,需要选择新的领导者和同步副本组,一个副本组要接受LeaderAndIsr请求,最后写领导者和同步副本组信息到zk中。
a.OfflinePartitionLeaderSelector:新领导者=存活副本(最好是在isr);新isr =存活isr如果不是空或恰好为新领导者,否则;正在接受中副本=存活已分配副本。
b.ReassignedPartitionLeaderSelector:新领导者=存活分区重新分配副本;新isr =当前isr;正在接受中副本=重新分配副本
c.PreferredReplicaPartitionLeaderSelector:新领导这=第一次分配副本(如果在isr);新isr =当前isr;接受副本=分配副本
d.ControlledShutdownLeaderSelector:新领导者=当前副本在isr中且没有被关闭,新isr =当前isr -关闭副本;接受副本=存活已分配副本。
2.对于这个分区,发送LeaderAndIsr请求给每一个接收副本和UpdateMetadata请求到每个broker server
NewPartition,OnlinePartition -> OfflinePartition
1.这只不过标识该分区为下线状态
OfflinePartition -> NonExistentPartition
1.这只不过标识该分区为不存在分区状态
ReplicaStateChange:
有效状态如下:
1.NewReplica:当创建topic或分区重新分配期间副本被创建。在这种状态下,副本只能成为追随者变更请求状态。
2.OnlineReplica:一旦此分区一个副本启动且部分分配副本,他将处于在线副本状态。在这种状态下,它可以成为领导者或成为跟随者状态变更请求。
3.OfflineReplica:每当broker server副本宕机或崩溃发生时,如果一个副本崩溃或挂了,它将变为此状态。
4.NonExistentReplica:如果一个副本被删除了,它将变为此状态。
有效状态转移如下:
NonExistentReplica - - > NewReplica
1.使用当前领导者和isr分区发送LeaderAndIsr请求到新副本和UpdateMetadata请求给每一个存活borker
NewReplica - > OnlineReplica
1.添加新的副本到副本列表中
OnlineReplica,OfflineReplica - > OnlineReplica
1.使用当前领导者和isr分区发送LeaderAndIsr请求到新副本和UpdateMetadata请求给每一个存活borker
NewReplica,OnlineReplica - > OfflineReplica
1.发送StopReplicaRequest到相应副本(w / o删除)
2.从isr和发送LeaderAndIsr请求重删除此副本(isr)领导者副本和UpdateMetadata分区每个存活broker。
OfflineReplica - > NonExistentReplica
1.发送StopReplicaRequest到副本(删除)
KafkaController操作:
当新建topic时:
- 调用方法onNewPartitionCreation
当创建新分区时:
- 创建新分区列表 -> 调用方法NewPartition
- 创建所有新分区副本 -> 调用方法NewReplica
- 新分区在线列表 -> 调用方法OnlinePartition
- 新分区所有在线副本 -> OnlineReplica
当broker失败或挂掉时:
- 当前broker所有领导者分区为下线分区 -> 调用方法OfflinePartition
- 下线和在线分区列表 -> OnlinePartition (使用下线分区领导者选举)
- 在broker上所有fail副本 -> OfflineReplica
当broker启动时:
- 发送UpdateMetadate请求给新启动broker的所有分区。
- 新启动broker的分区副本-> OnlineReplica
- 下线和在线分区列表 -> OnlinePartition (使用下线分区领导者选举)
- 当新的broker启动时,对于所有分区副本,系统会调用方法onPartitionReassignment执行未完成的分区分配。
当分区重新分配时: (OAR: 老的分配副本; RAR:每当重新分配副本会有新的副本组)
- 用OAR + RAR副本组修改并分配副本列表.
- 当处于OAR + RAR时,发送LeaderAndIsr请求给每个副本。
- 副本处于RAR - OAR -> 调用方法NewReplica
- 等待直到新的副本加入isr中
- 副本处于RAR -> 调用方法OnlineReplica
- 设置AR to RAR并写到内存中
- send LeaderAndIsr request 给一个潜在领导者 (如果当前领导者不在RAR中)和一个被分配的副本列表(使用RAR) 和相同sir到每个处于RAR的broker中。
- replicas in OAR - RAR -> Offline (强制这些副本从isr重剔除)
- replicas in OAR - RAR -> NonExistentReplica (强制这些副本被删除)
- 在zk上修改重分配副本到RAR中。
- 在zk上修改 /admin/reassign_partitions路径,并删除此分区
- 选举领导者后,副本和isr信息变化,所以重新发送更新元数据请求给每一个broker。
例如, if OAR = {1, 2, 3} and RAR = {4,5,6}, 在zk上重分配副本和领导者/is这些值可能经历以下转化。
AR leader/isr
{1,2,3} 1/{1,2,3} (初始化状态)
{1,2,3,4,5,6} 1/{1,2,3} (step 2)
{1,2,3,4,5,6} 1/{1,2,3,4,5,6} (step 4)
{1,2,3,4,5,6} 4/{1,2,3,4,5,6} (step 7)
{1,2,3,4,5,6} 4/{4,5,6} (step 8)
{4,5,6} 4/{4,5,6} (step 10)
注意,当只有一个地方我们能存储OAR持久化数据,必须用RAR在zk修改AR节点数据,这样,如果控制器在这一步之前崩溃,我们仍然可以恢复。
当中央控制器failover时:
- replicaStateMachine.startup():
- 从任何下线副本或上线副本中初始化每个副本
- 每个副本 -> OnlineReplica (强制LeaderAndIsr请求发送到每个副本)
- partitionStateMachine.startup():
- 从新建分区中初始化每个分区, 下线或上线分区
- each OfflinePartition and NewPartition -> OnlinePartition (强制领导者选举)
- 恢复分区分配
- 恢复领导者选举
当发送首选副本选举时:
- 影响分区列表 -> 调用方法OnlinePartition (with PreferredReplicaPartitionLeaderSelector)
关闭broker:
- 在关闭broker中对于每个分区如果是领导者分区 -> 调用方法OnlinePartition (ControlledShutdownPartitionLeaderSelector)
- 在关闭broker中每个副本是追随者,将发送StopReplica请求 (w/o deletion)
- 在关闭broker中每个副本是追随者 -> 调用方法OfflineReplica (强制从同步副本组中删除副本)
14)Kafka性能测试报告(虚拟机版)
测试方法
在其他虚拟机上使用 Kafka 自带 kafka-producer-perf-test.sh 脚本进行测试 Kafka 写入性能
尝试使用 kafka-simple-consumer-perf-test.sh 脚本测试 Kafka Consumer 性能,但由于获取到的数据不靠谱,放弃这个测试方法
性能数据
注:Gzip 和 Snappy 的传输速度 MB/S 是通过压缩前数据计算的,压缩后的实际传输量并没有超过百兆网卡上限
| 单条消息大小 |
batch size/条 |
线程数 |
压缩方式 |
传输速度 MB/S |
传输速度 Message/S |
| 0~1000 (avg 500) |
200 |
10 |
不压缩 |
11.1513 (约为百兆网卡上线) |
23369.8916 |
| 0~1000 (avg 500) |
200 |
10 |
Gzip |
14.0450 |
29425.1878 |
| 0~1000 (avg 500) |
200 |
10 |
Snappy |
32.2064 |
67471.7850 |
| 0~100(avg 50) |
200 |
10 |
不压缩 |
5.3654 |
111399.5121 |
| 0~100(avg 50) |
200 |
10 |
Gzip |
2.6479 |
54979.4926 |
| 0~100(avg 50) |
200 |
10 |
Snappy |
4.4217 |
91836.6410 |
| 0~1800 (avg 900) 仿线上数据量大小 |
200 |
10 |
不压缩 |
11.0518 (约为百兆网卡上线) |
12867.3632 |
| 0~1800 (avg 900) 仿线上数据量大小 |
200 |
10 |
Gzip |
17.3944 |
20261.3717 |
| 0~1800 (avg 900) 仿线上数据量大小 |
200 |
10 |
Snappy |
31.0658 |
36174.2150 |
| 以下数据为第二天测试数据 |
|
|
|
|
|
| 0~100(avg 50) |
200 |
10 |
不压缩 |
1.8482 |
38387.7159 |
| 0~100(avg 50) |
200 |
10 |
Gzip |
1.3591 |
28219.0930 |
| 0~100(avg 50) |
200 |
10 |
Snappy |
2.0213 |
41979.7658 |
| 0~100(avg 50) |
200 |
50 |
不压缩 |
2.0900 |
43402.7778 |
| 0~100(avg 50) |
200 |
50 |
Gzip |
1.4639 |
30387.7477 |
| 0~100(avg 50) |
200 |
50 |
Snappy |
2.0871 |
43323.8021 |
| 0~1000 (avg 500) |
200 |
10 |
不压缩 |
9.8287 |
20594.3530 |
| 0~1000 (avg 500) |
200 |
10 |
Gzip |
13.0659 |
27386.0058 |
| 0~1000 (avg 500) |
200 |
10 |
Snappy |
20.1827 |
42265.4269 |
| 0~1000 (avg 500) |
200 |
1 |
不压缩 |
7.0980 |
14885.6041 |
| 0~1000 (avg 500) |
200 |
1 |
Gzip |
7.4438 |
15587.7356 |
| 0~1000 (avg 500) |
200 |
1 |
Snappy |
15.3256 |
32088.3070 |
测试结论
1、线上的实际message平均大小略小于1k,在这种情况下(对应 0~1800 的test case),虚拟机可以应对每秒上万条写入请求。测试环境下,网络带宽是其瓶颈。通过压缩可以绕过瓶颈,Snappy算法可以处理36000+条请求每秒
2、在使用小数据进行测试时,Kafka每秒可以处理10万条左右数据,网络和IO都不是瓶颈,说明Kafka在虚拟机上处理写入请求的上限约为10万条每秒。
3、第二天的测试在相同条件下与第一天差距很大(0~100 大小数据,10线程,batch size 200),第二天在不压缩情况下只有第一天的三分之一的处理能力,snappy压缩情况下也只有二分之一处理能力,说明虚拟机的性能不够稳定。
4、生产者线程数对比,说明在网络和IO及Kafka处理能力没有达到瓶颈时,更多的线程能够增加写入速度,但是增长不明显。
测试推论
1、虚拟机上的Kafka最高也可以处理10万条请求,物理机的处理能力强得多,应当超过10万条每秒的处理能力。对应线上平均数据大小接近1K,处理数据流量能力不会低于100MB/S,接近千兆网卡上限。说明物理机上,在遇到网络带宽瓶颈前,Kafka性能应当不会是瓶颈。
2、虚拟机测试是在单topic 单replication 的情况下测试的。无法确定在多个replication时性能下降情况。从网上查找看,性能下降不是很明显。
3、从测试看,虚拟机的性能能够承担线上请求。但虚拟机性能不稳定,需要非常谨慎。
15)apache kafka监控系列-kafka-web-console
Kafka Web Console是kafka的开源web监控程序.
功能介绍如下:
- brokers列表
- 连接kafka的zk集群列表
- 所有topic列表,操作相应topic可以浏览查看相应message生产和消费流量图.
1.下载Kafka Web Console
2.安装sbt
3.配置Kafka Web Console
- ......
- libraryDependencies ++= Seq(
- jdbc,
- cache,
- "org.squeryl" % "squeryl_2.10" % "0.9.5-6",
- "com.twitter" % "util-zk_2.10" % "6.11.0",
- "com.twitter" % "finagle-core_2.10" % "6.15.0",
- "org.apache.kafka" % "kafka_2.10" % "0.8.1",
- "org.quartz-scheduler" % "quartz" % "2.2.1",
- "mysql" % "mysql-connector-java" % "5.1.9"
- exclude("javax.jms", "jms")
- exclude("com.sun.jdmk", "jmxtools")
- exclude("com.sun.jmx", "jmxri")
- )
- .......
4.配置mysql的jdbc驱动
- .......
- db.default.driver=com.mysql.jdbc.Driver
- db.default.url="jdbc:mysql://192.168.2.105:3306/mafka?useUnicode=true&characterEncoding=UTF8&connectTimeout=5000&socketTimeout=10000"
- db.default.user=xxx
- db.default.password=xxx
- .......
5.执行sql语句(如下绿色选框所示)
6.编译
7.运行

8.浏览访问
16)apache kafka迁移与扩容工具用法
参考官网site:https://cwiki.apache.org/confluence/display/KAFKA/Replication+tools#Replicationtools-6.ReassignPartitionsTool
说明:
当我们对kafka集群扩容时,需要满足2点要求:
- 将指定topic迁移到集群内新增的node上。
- 将topic的指定partition迁移到新增的node上。
1. 迁移topic到新增的node上
- lizhitao@localhost:$ ./bin/kafka-reassign-partitions.sh --zookeeper 192.168.2.225:2183/config/mobile/mq/mafka
- --topics-to-move-json-file migration-push-token-topic.json --broker-list "104,105,106" --generate
脚本migration-push-token-topic.json文件内容如下:
- {
- "topics":
- [
- {
- "topic": "push-token-topic"
- }
- ],
- "version":1
- }
生成分配partitions的json脚本:
- Current partition replica assignment
- {"version":1,"partitions":[{"topic":"cluster-switch-topic","partition":10,"replicas":[8]},{"topic":"cluster-switch-topic","partition":5,"replicas":[4]},{"topic":"cluster-switch-topic","partition":3,"replicas":[5]},{"topic":"cluster-switch-topic","partition":4,"replicas":[5]},{"topic":"cluster-switch-topic","partition":9,"replicas":[5]},{"topic":"cluster-switch-topic","partition":1,"replicas":[5]},{"topic":"cluster-switch-topic","partition":11,"replicas":[4]},{"topic":"cluster-switch-topic","partition":7,"replicas":[5]},{"topic":"cluster-switch-topic","partition":2,"replicas":[4]},{"topic":"cluster-switch-topic","partition":0,"replicas":[4]},{"topic":"cluster-switch-topic","partition":6,"replicas":[4]},{"topic":"cluster-switch-topic","partition":8,"replicas":[4]}]}
重新分配parttions的json脚本如下:
- migration-topic-cluster-switch-topic.json
- {"version":1,"partitions":[{"topic":"cluster-switch-topic","partition":10,"replicas":[5]},{"topic":"cluster-switch-topic","partition":5,"replicas":[4]},{"topic":"cluster-switch-topic","partition":4,"replicas":[5]},{"topic":"cluster-switch-topic","partition":3,"replicas":[4]},{"topic":"cluster-switch-topic","partition":9,"replicas":[4]},{"topic":"cluster-switch-topic","partition":1,"replicas":[4]},{"topic":"cluster-switch-topic","partition":11,"replicas":[4]},{"topic":"cluster-switch-topic","partition":7,"replicas":[4]},{"topic":"cluster-switch-topic","partition":2,"replicas":[5]},{"topic":"cluster-switch-topic","partition":0,"replicas":[5]},{"topic":"cluster-switch-topic","partition":6,"replicas":[5]},{"topic":"cluster-switch-topic","partition":8,"replicas":[5]}]}
- lizhitao@localhost:$ bin/kafka-reassign-partitions.sh --zookeeper 192.168.2.225:2183/config/mobile/mq/mafka01 --reassignment-json-file migration-topic-cluster-switch-topic.json --execute
2.topic修改(replicats-factor)副本个数
- lizhitao@localhost:$ ./bin/kafka-reassign-partitions.sh --zookeeper 192.168.2.225:2183/config/mobile/mq/mafka
- --reassignment-json-file replicas-update-push-token-topic.json --execute
假如初始时push-token-topic为一个副本,为了提高可用性,需要改为2副本模式。
脚本replicas-push-token-topic.json文件内容如下:
- {
- "partitions":
- [
- {
- "topic": "log.mobile_nginx",
- "partition": 0,
- "replicas": [101,102,104]
- },
- {
- "topic": "log.mobile_nginx",
- "partition": 1,
- "replicas": [102,103,106]
- },
- {
- "topic": "xxxx",
- "partition": 数字,
- "replicas": [数组]
- }
- ],
- "version":1
- }
3.topic的分区扩容用法
a.先扩容分区数量,脚本如下:
例如:push-token-topic初始分区数量为12,目前到增加到15个
- lizhitao@localhost:$ ./bin/kafka-topics.sh --zookeeper 192.168.2.225:2183/config/mobile/mq/mafka --alter --partitions 15 --topic push-token-topic
b.设置topic分区副本
- lizhitao@localhost:$ ./bin/kafka-reassign-partitions.sh --zookeeper 192.168.2.225:2183/config/mobile/mq/mafka
- --reassignment-json-file partitions-extension-push-token-topic.json --execute
脚本partitions-extension-push-token-topic.json文件内容如下:
- {
- "partitions":
- [
- {
- "topic": "push-token-topic",
- "partition": 12,
- "replicas": [101,102]
- },
- {
- "topic": "push-token-topic",
- "partition": 13,
- "replicas": [103,104]
- },
- {
- "topic": "push-token-topic",
- "partition": 14,
- "replicas": [105,106]
- }
- ],
- "version":1
- }
17)kafka LeaderNotAvailableException
经常producer和consumer会包如下异常
LeaderNotAvailableException
原因:
1.其中该分区所在的broker挂了,如果是多副本,该分区所在broker恰好为leader
18)apache kafka jmx监控指标参数
Kafka使用Yammer Metrics来监控server和client指标数据。
JMX监控指标参数列表如下:
| 参数 | Mbean名称 | 说明 |
|---|---|---|
| Message in rate | "kafka.server":name="AllTopicsMessagesInPerSec",type="BrokerTopicMetrics" | 所有topic消息(进出)流量 |
| Byte in rate | "kafka.server":name="AllTopicsBytesInPerSec",type="BrokerTopicMetrics" | |
| Request rate | "kafka.network":name="{Produce|Fetch-consumer|Fetch-follower}-RequestsPerSec",type="RequestMetrics" | |
| Byte out rate | "kafka.server":name="AllTopicsBytesOutPerSec",type="BrokerTopicMetrics" | |
| Log flush rate and time | "kafka.log":name="LogFlushRateAndTimeMs",type="LogFlushStats" | |
| # of under replicated partitions (|ISR| < |all replicas|) | "kafka.server":name="UnderReplicatedPartitions",type="ReplicaManager" | 0 |
| Is controller active on broker | "kafka.controller":name="ActiveControllerCount",type="KafkaController" | only one broker in the cluster should have 1 |
| Leader election rate | "kafka.controller":name="LeaderElectionRateAndTimeMs",type="ControllerStats" | non-zero when there are broker failures |
| Unclean leader election rate | "kafka.controller":name="UncleanLeaderElectionsPerSec",type="ControllerStats" | 0 |
| Partition counts | "kafka.server":name="PartitionCount",type="ReplicaManager" | mostly even across brokers |
| Leader replica counts | "kafka.server":name="LeaderCount",type="ReplicaManager" | mostly even across brokers |
| ISR shrink rate | "kafka.server":name="ISRShrinksPerSec",type="ReplicaManager" | If a broker goes down, ISR for some of the partitions will shrink. When that broker is up again, ISR will be expanded once the replicas are fully caught up. Other than that, the expected value for both ISR shrink rate and expansion rate is 0. |
| ISR expansion rate | "kafka.server":name="ISRExpandsPerSec",type="ReplicaManager" | See above |
| Max lag in messages btw follower and leader replicas | "kafka.server":name="([-.\w]+)-MaxLag",type="ReplicaFetcherManager" | 副本消息滞后数量 |
| Lag in messages per follower replica | "kafka.server":name="([-.\w]+)-ConsumerLag",type="FetcherLagMetrics" | 副本消息滞后数量 |
| Requests waiting in the producer purgatory | "kafka.server":name="PurgatorySize",type="ProducerRequestPurgatory" | |
| Requests waiting in the fetch purgatory | "kafka.server":name="PurgatorySize",type="FetchRequestPurgatory" | |
| Request total time | "kafka.network":name="{Produce|Fetch-Consumer|Fetch-Follower}-TotalTimeMs",type="RequestMetrics" | |
| Time the request waiting in the request queue | "kafka.network":name="{Produce|Fetch-Consumer|Fetch-Follower}-QueueTimeMs",type="RequestMetrics" | |
| Time the request being processed at the leader | "kafka.network":name="{Produce|Fetch-Consumer|Fetch-Follower}-LocalTimeMs",type="RequestMetrics" | |
| Time the request waits for the follower | "kafka.network":name="{Produce|Fetch-Consumer|Fetch-Follower}-RemoteTimeMs",type="RequestMetrics" | |
| Time to send the response | "kafka.network":name="{Produce|Fetch-Consumer|Fetch-Follower}-ResponseSendTimeMs",type="RequestMetrics" | |
| Number of messages the consumer lags behind the producer by | "kafka.consumer":name="([-.\w]+)-MaxLag",type="ConsumerFetcherManager" |
19)apache kafka性能测试命令使用和构建kafka-perf
本来想用kafka官方提供的工具做性能测试的。但事与愿违,当我执行官方提供的kafka测试脚本,却报错没有找到ProducerPerformance,后来浏览一些代码文件,才发现没有把perf性能测试程序打包到kafka_2.x.0-0.8.x.x.jar发行版本中。
现在来教您如何打包做测试。
1.准备工作:
安装gradle
2.下载kafka源代码
kafka-0.8.1源代码
3.编译kafka-perf_2.x-0.8.1.x.jar
编译注意事项:默认情况下是编译为2.8.0版本,也可以指定版本编译。目前编译高版本的kafka-perf(2.8.0以上版本)是由问题的,因为build.gradle配置参数有问题(版本不同,会报如下错误,版本不兼容错误),如果要构建高版本kafka-perf多版本修改内容如下:
下载build.gradle 替换掉kafka-0.8.1.1-src根目录下文件即可
编译构建执行命令:
- gradle jar 默认生成2.8.0版本的kafka和kafka-perf的jar
- gradle jar_core_2_8_0 生成2.8.0版本的kafka的jar
- gradle jar_core_2_8_2 生成2.8.2版本的kafka的jar
- gradle jar_core_2_9_1 生成2.9.1版本的kafka的jar
- gradle jar_core_2_9_2 生成2.9.2版本的kafka的jar
- gradle jar_core_2_10_1 生成2.10.1版本的kafka的jar
- gradle perf:jar 生成2.8.0版本的kafka和kafka-perf的jar
- gradle perf_2_9_1 生成2.9.1版本的kafka和kafka-perf的jar
- gradle perf_2_10_1 生成2.10.1版本的kafka和kafka-perf的jar
- gradle -PscalaVersion=2.8.0 jar 编译scala 2.8.0版本编译所有jar
- gradle -PscalaVersion=2.8.2 jar 编译scala 2.8.2版本编译所有jar
- gradle -PscalaVersion=2.9.1 jar 编译scala 2.9.1版本编译所有jar
- gradle -PscalaVersion=2.10.1 jar 编译scala 2.10.1版本编译所有jar
如果不想编译jar,可以直接下载:kafka-perf_2.x.x-0.8.1.jar
- lizhitao@users-MacBook-Pro:~/mt_wp/tmp$ cd kafka-0.8.1.1-src
- lizhitao@users-MacBook-Pro:~/mt_wp/tmp/kafka-0.8.1.1-src$gradle jar
- lizhitao@users-MacBook-Pro:~/mt_wp/tmp/kafka-0.8.1.1-src$gradle perf:jar
- The TaskContainer.add() method has been deprecated and is scheduled to be removed in Gradle 2.0. Please use the create() method instead.
- Building project 'core' with Scala version 2.8.0
- Building project 'perf' with Scala version 2.8.0
- :core:compileJava UP-TO-DATE
- :core:compileScala
- /Users/lizhitao/mt_wp/tmp/kafka-0.8.1.1-src/core/src/main/scala/kafka/admin/AdminUtils.scala:243: non variable type-argument String in type pattern scala.collection.Map[String,_] is unchecked since it is eliminated by erasure
- case Some(map: Map[String, _]) =>
- ^
- /Users/lizhitao/mt_wp/tmp/kafka-0.8.1.1-src/core/src/main/scala/kafka/admin/AdminUtils.scala:246: non variable type-argument String in type pattern scala.collection.Map[String,String] is unchecked since it is eliminated by erasure
- case Some(config: Map[String, String]) =>
- ^
- /Users/lizhitao/mt_wp/tmp/kafka-0.8.1.1-src/core/src/main/scala/kafka/api/LeaderAndIsrResponse.scala:66: non variable type-argument String in type pattern (String, Int) is unchecked since it is eliminated by erasure
- for ((key:(String, Int), value) <- responseMap) {
- ^
- /Users/lizhitao/mt_wp/tmp/kafka-0.8.1.1-src/core/src/main/scala/kafka/utils/Utils.scala:363: non variable type-argument V in type pattern List[V] is unchecked since it is eliminated by erasure
- case Some(l: List[V]) => m.put(k, v :: l)
- ^
- four warnings found
- :core:processResources UP-TO-DATE
- :core:classes
- :core:copyDependantLibs UP-TO-DATE
- :core:jar UP-TO-DATE
- :perf:compileJava UP-TO-DATE
- :perf:compileScala
- :perf:processResources UP-TO-DATE
- :perf:classes
- :perf:jar UP-TO-DATE
- BUILD SUCCESSFUL
- Total time: 54.41 secs
编译jar包目录如下:
a. kafka_2.x-0.8.1.1.jar
kafka-0.8.1.1-src/core/build

b.kafka-perf_2.x-0.8.1.x.jar
kafka-0.8.1.1-src/perf/build/libs

kafka多版本jar:

4. kafka性能测试命令用法:
4.1 创建topic
bin/kafka-topics.sh --zookeeper 192.168.2.225:2182,192.168.2.225:2183/config/mobile/mq/mafka02 --create --topic test-rep-one --partitions 6 --replication-factor 1
4.2 kafka-producer-perf-test.sh中参数说明:
- messages 生产者发送总的消息数量
- message-size 每条消息大小
- batch-size 每次批量发送消息的数量
- topics 生产者发送的topic
- threads 生产者使用几个线程同时发送
- broker-list 安装kafka服务的机器ip:port列表
- producer-num-retries 一个消息失败发送重试次数
- request-timeout-ms 一个消息请求发送超时时间
4.3 bin/kafka-consumer-perf-test.sh中参数说明:
- zookeeperzk 配置
- messages 消费者消费消息总数量
- topic 消费者需要消费的topic
- threads 消费者使用几个线程同时消费
- group 消费者组名称
- socket-buffer-sizesocket 缓冲大小
- fetch-size 每次向kafka broker请求消费大小
- consumer.timeout.ms 消费者去kafka broker拿去一条消息超时时间
4.4 生产者发送数据:
- lizhitao@users-MacBook-Pro:~/mt_wp/tmp/kafka-0.8.1.1-src$ bin/kafka-producer-perf-test.sh --messages 5000000 --message-size 5000 --batch-size 5000 --topics test-rep-one --threads 8 --broker-list mobile-esb03:9092,mobile-esb04:9092,mobile-esb05:9092
- start.time, end.time, compression, message.size, batch.size, total.data.sent.in.MB, MB.sec, total.data.sent.in.nMsg, nMsg.sec
- [2014-07-06 12:52:36,139] WARN Property reconnect.interval is not valid (kafka.utils.VerifiableProperties)
- SLF4J: Failed to load class "org.slf4j.impl.StaticLoggerBinder".
- SLF4J: Defaulting to no-operation (NOP) logger implementation
- SLF4J: See http://www.slf4j.org/codes.html#StaticLoggerBinder for further details.
- [2014-07-06 12:52:36,199] WARN Property reconnect.interval is not valid (kafka.utils.VerifiableProperties)
- [2014-07-06 12:52:36,202] WARN Property reconnect.interval is not valid (kafka.utils.VerifiableProperties)
- [2014-07-06 12:52:36,204] WARN Property reconnect.interval is not valid (kafka.utils.VerifiableProperties)
- [2014-07-06 12:52:36,206] WARN Property reconnect.interval is not valid (kafka.utils.VerifiableProperties)
- [2014-07-06 12:52:36,207] WARN Property reconnect.interval is not valid (kafka.utils.VerifiableProperties)
- [2014-07-06 12:52:36,209] WARN Property reconnect.interval is not valid (kafka.utils.VerifiableProperties)
- [2014-07-06 12:52:36,214] WARN Property reconnect.interval is not valid (kafka.utils.VerifiableProperties)
4.5 消费者消费数据
- lizhitao@users-MacBook-Pro:~/mt_wp/tmp/kafka-0.8.1.1-src$ bin/kafka-consumer-perf-test.sh --zookeeper
- 192.168.2.225:2182,192.168.2.225:2183/config/mobile/mq/mafka02 --messages 50000000 --topic test-rep-one --threads 1
- start.time, end.time, fetch.size, data.consumed.in.MB, MB.sec, data.consumed.in.nMsg, nMsg.sec
- SLF4J: Failed to load class "org.slf4j.impl.StaticLoggerBinder".
- SLF4J: Defaulting to no-operation (NOP) logger implementation
- SLF4J: See http://www.slf4j.org/codes.html#StaticLoggerBinder for further details.
20)apache kafka源码构建打包
准备工作:
安装gradle
1.构建kafka的jar并运行
2.构建源代码jar

3.运行序列化测试
4.gradle任务列表

5.构建所有jar,包括tasks中各个版本jar
6.指定构建jar包版本
mavenUrl=
mavenUsername=
mavenPassword=
signing.keyId=
signing.password=
signing.secretKeyRingFile=
21)Apache kafka客户端开发-java
1.依赖包
<dependency>
<groupId>org.apache.kafka</groupId>
<artifactId>kafka_2.10</artifactId>
<version>0.8.1</version>
</dependency>
2.producer程序开发例子
2.1 producer参数说明
#指定kafka节点列表,用于获取metadata,不必全部指定
metadata.broker.list=192.168.2.105:9092,192.168.2.106:9092
# 指定分区处理类。默认kafka.producer.DefaultPartitioner,表通过key哈希到对应分区
#partitioner.class=com.meituan.mafka.client.producer.CustomizePartitioner
# 是否压缩,默认0表示不压缩,1表示用gzip压缩,2表示用snappy压缩。压缩后消息中会有头来指明消息压缩类型,故在消费者端消息解压是透明的无需指定。
compression.codec=none
# 指定序列化处理类(mafka client API调用说明-->3.序列化约定wiki),默认为kafka.serializer.DefaultEncoder,即byte[]
serializer.class=com.meituan.mafka.client.codec.MafkaMessageEncoder
# serializer.class=kafka.serializer.DefaultEncoder
# serializer.class=kafka.serializer.StringEncoder
# 如果要压缩消息,这里指定哪些topic要压缩消息,默认empty,表示不压缩。
#compressed.topics=
########### request ack ###############
# producer接收消息ack的时机.默认为0.
# 0: producer不会等待broker发送ack
# 1: 当leader接收到消息之后发送ack
# 2: 当所有的follower都同步消息成功后发送ack.
request.required.acks=0
# 在向producer发送ack之前,broker允许等待的最大时间
# 如果超时,broker将会向producer发送一个error ACK.意味着上一次消息因为某种
# 原因未能成功(比如follower未能同步成功)
request.timeout.ms=10000
########## end #####################
# 同步还是异步发送消息,默认“sync”表同步,"async"表异步。异步可以提高发送吞吐量,
# 也意味着消息将会在本地buffer中,并适时批量发送,但是也可能导致丢失未发送过去的消息
producer.type=sync
############## 异步发送 (以下四个异步参数可选) ####################
# 在async模式下,当message被缓存的时间超过此值后,将会批量发送给broker,默认为5000ms
# 此值和batch.num.messages协同工作.
queue.buffering.max.ms = 5000
# 在async模式下,producer端允许buffer的最大消息量
# 无论如何,producer都无法尽快的将消息发送给broker,从而导致消息在producer端大量沉积
# 此时,如果消息的条数达到阀值,将会导致producer端阻塞或者消息被抛弃,默认为10000
queue.buffering.max.messages=20000
# 如果是异步,指定每次批量发送数据量,默认为200
batch.num.messages=500
# 当消息在producer端沉积的条数达到"queue.buffering.max.meesages"后
# 阻塞一定时间后,队列仍然没有enqueue(producer仍然没有发送出任何消息)
# 此时producer可以继续阻塞或者将消息抛弃,此timeout值用于控制"阻塞"的时间
# -1: 无阻塞超时限制,消息不会被抛弃
# 0:立即清空队列,消息被抛弃
queue.enqueue.timeout.ms=-1
################ end ###############
# 当producer接收到error ACK,或者没有接收到ACK时,允许消息重发的次数
# 因为broker并没有完整的机制来避免消息重复,所以当网络异常时(比如ACK丢失)
# 有可能导致broker接收到重复的消息,默认值为3.
message.send.max.retries=3
# producer刷新topic metada的时间间隔,producer需要知道partition leader的位置,以及当前topic的情况
# 因此producer需要一个机制来获取最新的metadata,当producer遇到特定错误时,将会立即刷新
# (比如topic失效,partition丢失,leader失效等),此外也可以通过此参数来配置额外的刷新机制,默认值600000
topic.metadata.refresh.interval.ms=60000- import java.util.*;
- import kafka.javaapi.producer.Producer;
- import kafka.producer.KeyedMessage;
- import kafka.producer.ProducerConfig;
- public class TestProducer {
- public static void main(String[] args) {
- long events = Long.parseLong(args[0]);
- Random rnd = new Random();
- Properties props = new Properties();
- props.put("metadata.broker.list", "192.168.2.105:9092");
- props.put("serializer.class", "kafka.serializer.StringEncoder"); //默认字符串编码消息
- props.put("partitioner.class", "example.producer.SimplePartitioner");
- props.put("request.required.acks", "1");
- ProducerConfig config = new ProducerConfig(props);
- Producer<String, String> producer = new Producer<String, String>(config);
- for (long nEvents = 0; nEvents < events; nEvents++) {
- long runtime = new Date().getTime();
- String ip = “192.168.2.” + rnd.nextInt(255);
- String msg = runtime + “,www.example.com,” + ip;
- KeyedMessage<String, String> data = new KeyedMessage<String, String>("page_visits", ip, msg);
- producer.send(data);
- }
- producer.close();
- }
- }
2.1 指定关键字key,发送消息到指定partitions
- public class CustomizePartitioner implements Partitioner {
- public CustomizePartitioner(VerifiableProperties props) {
- }
- /**
- * 返回分区索引编号
- * @param key sendMessage时,输出的partKey
- * @param numPartitions topic中的分区总数
- * @return
- */
- @Override
- public int partition(Object key, int numPartitions) {
- System.out.println("key:" + key + " numPartitions:" + numPartitions);
- String partKey = (String)key;
- if ("part2".equals(partKey))
- return 2;
- // System.out.println("partKey:" + key);
- ........
- ........
- return 0;
- }
- }
3.consumer程序开发例子
3.1 consumer参数说明
# zookeeper连接服务器地址,此处为线下测试环境配置(kafka消息服务-->kafka broker集群线上部署环境wiki)
# 配置例子:"127.0.0.1:3000,127.0.0.1:3001,127.0.0.1:3002"
zookeeper.connect=192.168.2.225:2181,192.168.2.225:2182,192.168.2.225:2183/config/mobile/mq/mafka
# zookeeper的session过期时间,默认5000ms,用于检测消费者是否挂掉,当消费者挂掉,其他消费者要等该指定时间才能检查到并且触发重新负载均衡
zookeeper.session.timeout.ms=5000
zookeeper.connection.timeout.ms=10000
# 指定多久消费者更新offset到zookeeper中。注意offset更新时基于time而不是每次获得的消息。一旦在更新zookeeper发生异常并重启,将可能拿到已拿到过的消息
zookeeper.sync.time.ms=2000
#指定消费组
group.id=xxx
# 当consumer消费一定量的消息之后,将会自动向zookeeper提交offset信息
# 注意offset信息并不是每消费一次消息就向zk提交一次,而是现在本地保存(内存),并定期提交,默认为true
auto.commit.enable=true
# 自动更新时间。默认60 * 1000
auto.commit.interval.ms=1000
# 当前consumer的标识,可以设定,也可以有系统生成,主要用来跟踪消息消费情况,便于观察
conusmer.id=xxx
# 消费者客户端编号,用于区分不同客户端,默认客户端程序自动产生
client.id=xxxx
# 最大取多少块缓存到消费者(默认10)
queued.max.message.chunks=50
# 当有新的consumer加入到group时,将会reblance,此后将会有partitions的消费端迁移到新
# 的consumer上,如果一个consumer获得了某个partition的消费权限,那么它将会向zk注册
# "Partition Owner registry"节点信息,但是有可能此时旧的consumer尚没有释放此节点,
# 此值用于控制,注册节点的重试次数.
rebalance.max.retries=5
# 获取消息的最大尺寸,broker不会像consumer输出大于此值的消息chunk
# 每次feth将得到多条消息,此值为总大小,提升此值,将会消耗更多的consumer端内存
fetch.min.bytes=6553600
# 当消息的尺寸不足时,server阻塞的时间,如果超时,消息将立即发送给consumer
fetch.wait.max.ms=5000
socket.receive.buffer.bytes=655360
# 如果zookeeper没有offset值或offset值超出范围。那么就给个初始的offset。有smallest、largest、
# anything可选,分别表示给当前最小的offset、当前最大的offset、抛异常。默认largest
auto.offset.reset=smallest
# 指定序列化处理类(mafka client API调用说明-->3.序列化约定wiki),默认为kafka.serializer.DefaultDecoder,即byte[]
derializer.class=com.meituan.mafka.client.codec.MafkaMessageDecoder3.2 多线程并行消费topic
- import kafka.consumer.ConsumerIterator;
- import kafka.consumer.KafkaStream;
- public class ConsumerTest implements Runnable {
- private KafkaStream m_stream;
- private int m_threadNumber;
- public ConsumerTest(KafkaStream a_stream, int a_threadNumber) {
- m_threadNumber = a_threadNumber;
- m_stream = a_stream;
- }
- public void run() {
- ConsumerIterator<byte[], byte[]> it = m_stream.iterator();
- while (it.hasNext())
- System.out.println("Thread " + m_threadNumber + ": " + new String(it.next().message()));
- System.out.println("Shutting down Thread: " + m_threadNumber);
- }
- }
- import kafka.consumer.ConsumerConfig;
- import kafka.consumer.KafkaStream;
- import kafka.javaapi.consumer.ConsumerConnector;
- import java.util.HashMap;
- import java.util.List;
- import java.util.Map;
- import java.util.Properties;
- import java.util.concurrent.ExecutorService;
- import java.util.concurrent.Executors;
- public class ConsumerGroupExample {
- private final ConsumerConnector consumer;
- private final String topic;
- private ExecutorService executor;
- public ConsumerGroupExample(String a_zookeeper, String a_groupId, String a_topic) {
- consumer = kafka.consumer.Consumer.createJavaConsumerConnector(
- createConsumerConfig(a_zookeeper, a_groupId));
- this.topic = a_topic;
- }
- public void shutdown() {
- if (consumer != null) consumer.shutdown();
- if (executor != null) executor.shutdown();
- }
- public void run(int a_numThreads) {
- Map<String, Integer> topicCountMap = new HashMap<String, Integer>();
- topicCountMap.put(topic, new Integer(a_numThreads));
- Map<String, List<KafkaStream<byte[], byte[]>>> consumerMap = consumer.createMessageStreams(topicCountMap);
- List<KafkaStream<byte[], byte[]>> streams = consumerMap.get(topic);
- // 启动所有线程
- executor = Executors.newFixedThreadPool(a_numThreads);
- // 开始消费消息
- int threadNumber = 0;
- for (final KafkaStream stream : streams) {
- executor.submit(new ConsumerTest(stream, threadNumber));
- threadNumber++;
- }
- }
- private static ConsumerConfig createConsumerConfig(String a_zookeeper, String a_groupId) {
- Properties props = new Properties();
- props.put("zookeeper.connect", "192.168.2.225:2183/config/mobile/mq/mafka");
- props.put("group.id", "push-token");
- props.put("zookeeper.session.timeout.ms", "60000");
- props.put("zookeeper.sync.time.ms", "2000");
- props.put("auto.commit.interval.ms", "1000");
- return new ConsumerConfig(props);
- }
- public static void main(String[] args) {
- String zooKeeper = args[0];
- String groupId = args[1];
- String topic = args[2];
- int threads = Integer.parseInt(args[3]);
- ConsumerGroupExample example = new ConsumerGroupExample(zooKeeper, groupId, topic);
- example.run(threads);
- try {
- Thread.sleep(10000);
- } catch (InterruptedException ie) {
- }
- example.shutdown();
- }
- }
kafka消费者api分为high api和low api,目前上述demo是都是使用kafka high api,高级api不用关心维护消费状态信息和负载均衡,系统会根据配置参数,
定期flush offset到zk上,如果有多个consumer且每个consumer创建了多个线程,高级api会根据zk上注册consumer信息,进行自动负载均衡操作。
注意事项:
1.高级api将会内部实现持久化每个分区最后读到的消息的offset,数据保存在zookeeper中的消费组名中(如/consumers/push-token-group/offsets/push-token/2。
其中push-token-group是消费组,push-token是topic,最后一个2表示第3个分区),每间隔一个(默认1000ms)时间更新一次offset,
那么可能在重启消费者时拿到重复的消息。此外,当分区leader发生变更时也可能拿到重复的消息。因此在关闭消费者时最好等待一定时间(10s)然后再shutdown()
2.消费组名是一个全局的信息,要注意在新的消费者启动之前旧的消费者要关闭。如果新的进程启动并且消费组名相同,kafka会添加这个进程到可用消费线程组中用来消费
topic和触发重新分配负载均衡,那么同一个分区的消息就有可能发送到不同的进程中。
3.如果消费者组中所有consumer的总线程数量大于分区数,一部分线程或某些consumer可能无法读取消息或处于空闲状态。
4.如果分区数多于线程数(如果消费组中运行者多个消费者,则线程数为消费者组内所有消费者线程总和),一部分线程会读取到多个分区的消息
5.如果一个线程消费多个分区消息,那么接收到的消息是不能保证顺序的。
备注:可用zookeeper web ui工具管理查看zk目录树数据: xxx/consumers/push-token-group/owners/push-token/2其中
push-token-group为消费组,push-token为topic,2为分区3.查看里面的内容如:
push-token-group-mobile-platform03-1405157976163-7ab14bd1-0表示该分区被该标示的线程所执行。
producer性能优化:异步化,消息批量发送,具体浏览上述参数说明。consumer性能优化:如果是高吞吐量数据,设置每次拿取消息(fetch.min.bytes)大些,
拿取消息频繁(fetch.wait.max.ms)些(或时间间隔短些),如果是低延时要求,则设置时间时间间隔小,每次从kafka broker拿取消息尽量小些。
22) kafka broker内部架构
下面介绍kafka broker的主要子模块,帮助您更好地学习并理解kafka源代码和架构。
如下介绍几个子模块:
- Kafka API layer
- LogManager and Log
- ReplicaManager
- ZookeeperConsumerConnector
- service Schedule

kafka源代码工程目录结构如下图:

下面只对core目录结构作说明,其他都是测试类或java客户端代码
admin --管理员模块,操作和管理topic,paritions相关,包含create,delete topic,扩展patitions
Api --该模块主要负责组装数据,组装2种类型数据,
1.读取或解码客户端发送的二进制数据.
2.编码log消息数据,组装为需要发送的数据。
client --该模块比较简单,就一个类,Producer读取kafka broker元数据信息,
topic和partitions,以及leader
cluster --该模块包含几个实体类,Broker,Cluster,Partition,Replica,解释他们之间关系:Cluster由多个broker组成,一个Broker包含多个partition,一个 topic的所有partitions分布在不同broker的中,一个Replica包含多个Partition。
common --通用模块,只包含异常类和错误验证
consumer --consumer处理模块,负责所有客户端消费者数据和逻辑处理
contoroller --负责中央控制器选举,partition的leader选举,副本分配,副本重新分配,
partition和replica扩容。
javaapi --提供java的producer和consumer接口api
log --kafka文件系统,负责处理和存储所有kafka的topic数据。
message --封装kafka的ByteBufferMessageSet
metrics --内部状态的监控模块
network --网络事件处理模块,负责处理和接收客户端连接
producer --producer实现模块,包括同步和异步发送消息。
serializer --序列化或反序列化当前消息
kafka --kafka门面入口类,副本管理,topic配置管理,leader选举实现(由contoroller模块调用)。
tools --一看这就是工具模块,包含内容比较多:
a.导出对应consumer的offset值.
b.导出LogSegments信息,当前topic的log写的位置信息.
c.导出zk上所有consumer的offset值.
d.修改注册在zk的consumer的offset值.
f.producer和consumer的使用例子.
utils --Json工具类,Zkutils工具类,Utils创建线程工具类,KafkaScheduler公共调度器类,公共日志类等等。
1.kafka启动类:kafka.scala
kafka为kafka broker的main启动类,其主要作用为加载配置,启动report服务(内部状态的监控),注册释放资源的钩子,以及门面入口类。
kafka类代码如下:
- ......
- try {
- val props = Utils.loadProps(args(0)) //加载配置文件
- val serverConfig = new KafkaConfig(props)
- KafkaMetricsReporter.startReporters(serverConfig.props) //启动report服务(内部状态的监控)
- val kafkaServerStartble = new KafkaServerStartable(serverConfig) //kafka server核心入口类
- // attach shutdown handler to catch control-c
- Runtime.getRuntime().addShutdownHook(new Thread() { //钩子程序,当jvm退出前,销毁所有资源
- override def run() = {
- kafkaServerStartble.shutdown
- }
- })
- kafkaServerStartble.startup
- kafkaServerStartble.awaitShutdown
- }
- ......
KafkaServerStartble类包装了KafkaSever类,其实啥都没有做。只是调用包装类而已
KafkaSever类是kafka broker运行控制的核心入口类,它是采用门面模式设计的。

kafka中KafkaServer类,采用门面模式,是网络处理,io处理等得入口.
ReplicaManager 副本管理
KafkaApis api处理
KafkaRequestHandlerPoolkafka 请求处理池 <-- num.io.threads io线程数量
LogManager kafka文件系统,负责处理和存储所有kafka的topic数据
TopicConfigManager topic管理
KafkaHealthcheck 健康检查
KafkaController kafka集群中央控制器选举,leader选举,副本分配。
KafkaScheduler 负责副本管理和日志管理调度等等
ZkClient 负责注册zk相关信息.
BrokerTopicStats topic信息统计和监控
ControllerStats 中央控制器统计和监控
KafkaServer部分主要代码如下:
- ......
- def startup() {
- info("starting")
- isShuttingDown = new AtomicBoolean(false)
- shutdownLatch = new CountDownLatch(1)
- /* start scheduler */
- kafkaScheduler.startup()
- /* setup zookeeper */
- zkClient = initZk()