JAVA集合类框架
1 问题提出
通常,程序总是根据运行时才知道的某些条件去创建新对象。在此之前,不会知道所需对象的数量,甚至不知道确切的类型。如何解决这个问题呢?即如何在任意时刻和任意位置创建任意数量的对象?
Java类库提供了一套完整的容器类/集合类来解决这个问题。

2 集合框架中的接口(java.util)
所谓框架就是一个类库的集合。集合框架就是一个用来表示和操作集合的统一的架构,包含了实现集合的接口与类。
1)由此我们也可以看出来map接口和Collection是没有继承关系的。
2)Collection是所有序列容器的共性的根接口。Java.util.AbstractCollection类提供了Collection的默认实现,使得你可以创建AbstractCollection的子类型,而没有不必要的代码重复。
3)Map是所有键-值对的根接口。
4)规律:
Set是无序的,不能包含重复的元素。
List是一个有序(按一定次序排放)的集合,可以包含重复的元素。
Queue是队列,存取数据是按照先进先出原则(FIFO)。
Map是用来存储健—值对(key-value),Map不能包含重复的key。
Hash表示内部存储方式是采用哈希算法。
Link表示底层是链表数据结构。
Tree表示数据结构是树状结构。
Sort表示升序
3 用法举例
下面举例说明如何使用集合类
3.1 实现Set接口的类
1 Set如何判断元素是否重复
HashSet、LinkedHashSet、TreeSet
Set的实现类判断元素是否重复的方法差异很大,大致可以分为三种:使用equals,使用hashCode,使用compareTo。
1)HashSet依靠HashMap实现,类的对象作为HashSet的元素时,该类要重写父类的hashCode方法。
2)TreeSet是依靠TreeMap来实现的。类的对象作为TreeSet的元素时,该类要实现Comparable接口。
3)如果创建自己的类要添加到CopyOnWriteArraySet时,要重写equals方法。
类CopyOnWriteArraySet是java.util.concurrent包中的一个类,所以它是线程安全的。
CopyOnWriteArraySet是使用CopyOnWriteArrayList作为其盛放元素的容器。当往CopyOnWriteArrayList添加新元素,它都要遍历整个List,并且用equals来比较两个元素是否相同。
2 HashSet和TreeSet的比较
HashSet是基于Hash算法实现的,其性能通常都优于TreeSet。我们通常都应该使用HashSet,在我们需要排序的功能时,我们才使用TreeSet。
3.2 实现List接口的类
1 ArrayList
可以将ArrayList看作是能够自动增长容量的数组。
ArrayList al=new ArrayList();
al.add("google");
al.add("microsofte");
for(int i=0;i<al.size();i++)
{
System.out.println(al.get(i));
}//end for
数组与集合类间的转化
1)利用ArrayList的toArray()返回一个数组。
Object[] objs=al.toArray();
2)Arrays.asList()返回一个列表。
List l=Arrays.asList(数组名);
迭代器(Iterator) 给我们提供了一种通用的方式来访问集合中的元素。
1)每个集合类接口及其实现类都有一个iterator()方法,用来返回对应的Iterator方法。
Iterator it=al.iterator(); //ArrayList的迭代器,利用它来访问集合中的元素
2)Iterator的三个方法:
hasNext() //返回boolean,是否有一个元素
next() //返回下一个元素
remove() //删除next()方法返回的元素
//读取元素
public static void printElements(Collection c)
{
Iterator it=c.iterator();
while(it.hasNext())
{
System.out.println(it.next());
}//end while
}//end printElements()
//使用方法读取元素
printElements(al);
2 LinkedList
LinkedList是采用双向循环链表实现的。因为LinkedLis同时实现了List接口和Queue接口,所以可以用LinkedList实现单向链表、双向循环链表、栈、队列等数据结构,需要注意的是在操作元素(添加、删除、访问)的时候按照对应数据结构的方法进行操作。
descendingIterator() 方法返回以逆向顺序在此双端队列的元素上进行迭代的迭代器,可以通过该方法逆向访问元素
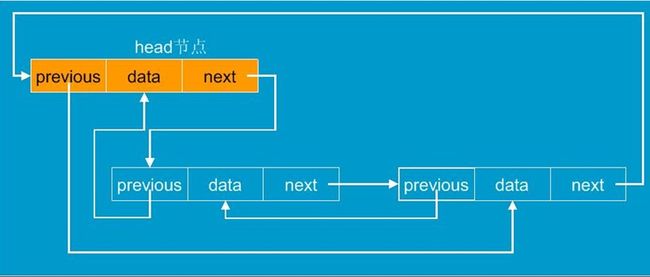
LinkedList源码分析
LinkedList 增删查改例子
LinkedList ll=new LinkedList();
public void insert(String key){
ll.add(key);
}//end insert()
public boolean delete(String key){
return ll.remove(key);
}//end delete()
public boolean find(String key){
boolean isFound=false;
String temp=null;
Iterator it=ll.iterator();
while(it.hasNext()){
temp=(String)it.next();
if(temp.equals(key)){
isFound=true;
}//end if
}//end while
return isFound;
}//end find()
3.3 实现Queue接口的类
LinkedList、PrioirtyQueue
3.3 实现Map接口的类
HashMap、LinkedHashMap、TreeMap
4 总结
各数据结构与JSE中类的对应关系如下
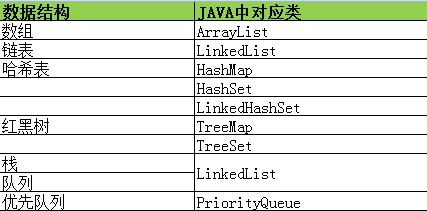
其中有排序功能的类是TreeSet和TreeMap
集合增删查改方法总结

