Linux内核链表的研究与应用
http://blog.csdn.net/tigerjb/article/details/8299599
(“2012年度CSDN博客之星”评选,欢迎为我投上一票,多谢)
Author:tiger-john
Time:2012-12-20
Mail:[email protected]
Blog:http://blog.csdn.net/tigerjb/article/details/8299599
转载请注明出处。
前言:
在Linux内核中使用了大量的链表来组织其数据,其采用了双向链表作为其基本的数据结构。但是与我们传统的数据结构中所学的双向链表又有着本质的一些不同(其不包含数据域)。其主要是Linux内核链表在设计时给出了一种抽象的定义。
采用这种定义有以下两种好处:1是可扩展性,2是封装。可扩展性肯定是必须的,内核一直都是在发展中的,所以代码都不能写成死代码,要方便修改和追加。将链表常见的操作都进行封装,使用者只关注接口,不需关注实现。
分析内核中的链表我们可以做些什么呢?
个人认为我们可以将其复用到用户态编程中,以后在用户态下编程就不需要写一些关于链表的代码了,直接将内核中list.h中的代码拷贝过来用。也可以整理出my_list.h,在以后的用户态编程中直接将其包含到C文件中。
一.Linux 内核链表数据结构
1.其代码位于include/linux/list.h中,3.0内核中将其数据结构定义放在了include/linux/types.h中
链表的数据定义:
struct list_head{
struct list_head * next,*prev;
}
这个不含数据域的链表,可以嵌入到任何结构中,例如可以按如下方式定义含有数据域的链表:
struct test_list{
void *testdata;
structlist_head list;
};
说明:
1>list 域隐蔽了链表的指针特性
2>struct list_head 可以位于结构的任何位置,可以给其起任何名字。
3>在一个结构体中可以有多个list域。
以struct list_head 为基本对象,对链表进行插入、删除、合并以及遍历等各种操作。
2.内核链表数据结构的设计思想是:
尽可能的代码重用,化大堆的链表设计为单个链表。
3.使用循环链表的好处:
双向循环链表的效率是最高的,找头节点,尾节点,直接前驱,直接后继时间复杂度都是O (1) ,而使用单链表,单向循环链表或其他形式的链表是不能完成的。
4.链表的构造:
如果需要构造某类对象的特定列表,则在其结构中定义一个类型为list_head
指针的成员(例如上面所说的struct test_list),通过这个成员将这类对象连接起来,形成所需列表,并通过通用链表函数对其进行操作。其优点是只需编写通用链表函数,即可构造和操作不同对象的列表,而无需为每类对象的每种列表编写专用函数,实现了代码的重用。
5.如何内核链表使用:
如果想对某种类型创建链表,就把一个list_head类型的变量嵌入到该类型中,用list_head中的成员和相对应的处理函数来对链表进行遍历。如果想得到相应的结构的指针,使用list_entry可以算出来。
二.链表的声明和初始化宏
实际上,struct list_head 只定义了链表结点,并没有专门定义链表头,可以 使用以下两个宏
#define LIST_HEAD_INIT(name) { &(name), &(name) }
#define LIST_HEAD(name) \
struct list_head name = LIST_HEAD_INIT(name)
1>name 为结构体struct list_head{}的一个结构体变量,&(name)为该结构体变量的地址。用name结构体变量的始地址将改结构体变量进行初始化。
2>LIST_HEAD_INIT(name)函数宏只进行初始化
3>LIST_HEAD(name)函数宏声明并进行初始化
4>如果要声明并初始化自己的链表头mylist_head,则直接调用LIST_HEAD:
LIST_HEAD(mylist_head)
调用之后,mylist_head的next,prev指针都初始化为指向自己,这样就有了一个空链表。因此可以得知在Linux中用头指针的next是否指向自己来判断链表是否为空。
5>除了LIST_HEAD宏在编译时静态初始化,还可以使用内嵌函数INIT_LIST_HEAD(struct list_head *list)在运行时进行初始化。
例如:调用INIT_LIST_HEAD(&mylist_head)对mylist_head链表进行初始化。
static inline void INIT_LIST_HEAD(struct list_head *list)
{
list->next = list;
list->prev = list;
}
注无论是采用哪种方式,新生成的链表头的指针next,prev都初始化为指向自己
三.链表的基本操作(插入,删除,判空)
1.判断链表是否为空
1>function:
函数判读链表是否为空链表,如果为空链表返回1,否则返回0.
2>函数接口
static inline int list_empty(const struct list_head *head)
static inline int list_empty_careful(const struct list_head *head)
3>以下两个函数都是判断一个链表是不是为空链表,
static inline int list_empty(const struct list_head *head)
{
return head->next == head;
}
static inline int list_empty_careful(const struct list_head *head)
{
struct list_head *next = head->next;
return (next == head) && (next == head->prev);
}
list_empty()函数和list_empty_careful()函数都是用来检测链表是否为空的。但是稍有区别的就是第一个链表使用的检测方法是判断表头的结点的下一个结点是否为其本身,如果是则返回为1,否则返回0。第二个函数使用的检测方法是判断表头的前一个结点和后一个结点是否为其本身,如果同时满足则返回0,否则返回值为1。
这主要是为了应付另一个cpu正在处理同一个链表而造成next、prev不一致的情况。但代码注释也承认,这一安全保障能力有限:除非其他cpu的链表操作只有list_del_init(),否则仍然不能保证安全,也就是说,还是需要加锁保护。
2.链表的插入
1>function:
将一个新结点插入到链表中(在表头插入和表尾插入)
2>Linux内核链表提供了两个函数:
static inline void list_add(struct list_head *new, struct list_head *head)
static inline void list_add_tail(struct list_head *new, struct list_head *head)
3>函数实现
static inline void list_add(struct list_head *new, struct list_head *head)
{
__list_add(new, head, head->next);
}
static inline void list_add_tail(struct list_head *new, struct list_head *head)
{
__list_add_tail(new, head->prev, head);
}
4>list_add和list_add_tail的区别并不大,都是调用了__list_add()函数
static inline void __list_add(struct list_head *new,struct list_head *prev,struct list_head *next)
{
next->prev = new;
new->next = next;
new->prev = prev;
prev->next = new;
}
__list_add(new,prev,next)函数表示在prev和next之间添加一个新的节点new
5>对于list_add()函数中的__list_add(new, head, head->next)表示的在head和head->next之间加入一个新的节点。即表头插入法(即先插入的后输出,可以用来实现一个栈)
6>对于list_add_tail()中的__list_add(new, head->prev, head)表示在head->prev(双向循环链表的最后一个结点)和head之间添加一个新的结点。即表尾插入法(先插入的先输出,可以用来实现一个队列)
3.链表的删除
1>function:
将一个结点从链表中删除
2>函数接口
static inline void list_del(struct list_head *entry)
static inline void list_del_init(struct list_head *entry)
注:在3.0内核中新添加了
static inline void __list_del_entry(struct list_head *entry)
3>函数实现
static inline void __list_del(struct list_head * prev, struct list_head* next)
{
next->prev = prev;
prev->next = next;
}
static inline void list_del(struct list_head *entry)
{
__list_del(entry->prev, entry->next);
entry->next = LIST_POISON1;
entry->prev = LIST_POISON2;
}
static inline void list_del_init(struct list_head *entry)
{
__list_del(entry->prev, entry->next);
INIT_LIST_HEAD(entry);
}
static inline void __list_del_entry(struct list_head *entry)
{
__list_del(entry->prev, entry->next);
}
(1)__list_del(entry->prev, entry->next)表示将entry的前一个和后一个之间建立关联。
(2)list_del()函数将删除后的prev、next指针分别被设为LIST_POSITION2和LIST_POSITION1两个特殊值,这样设置是为了保证不在链表中的节点项不可访问。对LIST_POSITION1和LIST_POSITION2的访问都将引起页故障。
注意:
这里的entry结点所占用的内存并没有被释放。
LIST_POSTION1和LIST_POSTION1在linux/poison.h中定义
#define LIST_POISON1 ((void *) 0x00100100 + POISON_POINTER_DELTA)
#define LIST_POISON2 ((void *) 0x00200200 + POISON_POINTER_DELTA)
POISON_POINTER_ELTA在linux/poison.h中定义
#ifdef CONFIG_ILLEGAL_POINTER_VALUE
#define POISON_POINTER_DELTA _AC(CONFIG_ILLEGAL_POINTER_VALUE, UL)
#else
#define POISON_POINTER_DELTA 0
#endif
其中POISON_POINTER_DELTA的值在CONFIG_ILLEGAL_POINTER_VALUE中未配置时为0
(3)list_del_init这个函数首先将entry从双向链表中删除之后,并且将entry初始化为一个空链表。
说明:list_del(entry)和list_del_init(entry)唯一不同的是对entry的处理,前者是将entry设置为不可用,后者是将其设置为一个空的链表的开始。
(4)__list_del_entry()函数实现只是简单的对__list_del进行了简单的封装实现了只用传入一个entry结点即可将其从链表中删除;与list_del的不同点是只是简单的删除结点,但并没有使entry结点不可用。
注意:在3.0内核中listd_move,和list_move_tail函数内部改成调用__list_del_entry。2.6内核中调用的是__list_del函数。
四.链表的其他操作
1.结点的替换
1>function:
结点的替换是将old的结点替换成new
2>linux内核提供了两个函数接口:
static inline void list_replace(struct list_head *old,struct list_head *new)
static inline void list_replace_init(struct list_head *old,struct list_head *new)
3> list_replace()函数的实现:
static inline void list_replace(struct list_head *old, struct list_head *new)
{
new->next = old->next;
new->next->prev = new;
new->prev = old->prev;
new->prev->next = new;
}
list_repleace()函数只是改变new和old的指针关系,然而old指针并没有释放。
4> list_replace_init()函数的实现:
static inline void list_replace_init(struct list_head *old, struct list_head *new)
{
list_replace(old, new);
INIT_LIST_HEAD(old);
}
List_repleace_init首先调用list_replace改变new和old的指针关系,然后调用INIT_LIST_HEAD(old)将old结点初始化空结点。
2结点的移动
1>function:
将一个结点从一个链表中删除,添加到另一个链表中。
2>linxu内核链表中提供了两个接口
static inline void list_move(struct list_head *list, struct list_head *head)
static inline void list_move_tail(struct list_head *list, struct list_head *head)
前者添加的时候使用的是头插法,后者使用的是尾插法
3> list_move函数实现
static inline void list_move(struct list_head *list, struct list_head *head)
{
__list_del_entry(list);
list_add(list, head);
}
List_move函数调用__list_del_entry()函数将lis结点删除,然后调用list_add()函数将其插入到head结点中(使用头插法)
4>list_move_tail函数实现
static inline void list_move_tail(struct list_head *list, struct list_head *head)
{
__list_del_entry(list);
list_add_tail(list, head);
}
list_move_tail()函数调用_list_del_entry函数将list结点删除,然后调用list_add_tail函数将list结点插入到head结点中(使用尾插法)
3检测是否为最后结点
1>function:
判断一个结点是不是链表head的最后一个结点。
2>linux内核函数接口
static inline int list_empty(const struct list_head *list, const struct list_head *head )
{
return list->next == head;
}
如果结点的后继为头结点,则说明此结点为最后一个结点。
4.检测链表中是否只有一个结点
1>function:
函数是用来判断head这个链表是不是只有一个成员结点(不算带头结点的那个head),是则返回1,否则返回0.
2>函数接口:
static inline int list_is_singular(const struct list_head *head)
3>函数实现:
static inline int list_is_singular(const struct list_head *head)
{
return !list_empty(head) && (head->next == head->prev);
}
首先判断链表是否为空,如果非空则判断
5.链表的旋转
1>function:
这个函数把head后的第一个结点放到最后位置。
2> 函数接口:
static inline void list_rotate_left(struct list_head *head)
3>lis_rotate_left函数实现
static inline void list_rotate_left(struct list_head *head)
{
struct list_head *first;
if (!list_empty(head)) {
first = head->next;
list_move_tail(first, head);
}
}
List_rotate_left函数每次将头结点后的一个结点放到head链表的末尾,直到head结点后没有其他结点。
6.分割链表
1>function:
函数将head(不包括head结点)到entry结点之间的所有结点截取下来添加到list链表中。该函数完成后就产生了两个链表head和list
2>函数接口:
static inline void list_cut_position(struct list_head *list,struct list_head *head,struct list_head *entry)
list: 将截取下来的结点存放到list链表中
head: 被剪切的链表
entry: 所指位于由head所指的链表内。它是分割线,entry之前的结点存放到list之中。Entry之后的结点存放到head链表中。
3>list_cut_position函数实现:
static inline void list_cut_position(struct list_head *list,
struct list_head *head, struct list_head *entry)
{
if (list_empty(head))
return;
if (list_is_singular(head) &&
(head->next != entry && head != entry))
return;
if (entry == head)
INIT_LIST_HEAD(list);
else
__list_cut_position(list, head, entry);
}
函数进行了判断:
(1)head链表是否为空,如果为空直接返回不进行操作。否则进行第二步操作
(2)head是否只有一个结点,如果只有一个结点则继续判断该结点是否是entry,如果不是entry则直接返回。(即head链表中没有entry结点则返回,不进行操作)
(3)如果entry指向head结点,则不进行剪切。直接将list链表初始化为空.
(4)判断完后,调用__list_cut_position(list,head,entry)函数完成链表剪切。
4>__list_splice函数:
(1)功能:函数将head(不包括head结点)到entry结点之间的所有结点截取下来添加到list链表。将entry之后的结点放到head链表中。
(2)函数接口:
static inline void __list_cut_position(struct list_head *list, struct list_head *head, struct list_head *entry)
(3)__list_cut_position函数实现
static inline void __list_cut_position(struct list_head *list, struct list_head *head, struct list_head *entry)
{
struct list_head *new_first = entry->next;
list->next = head->next;
list->next->prev = list;
list->prev = entry;
entry->next = list;
head->next = new_first;
new_first->prev = head;
}
函数实现过程见图:
起始:
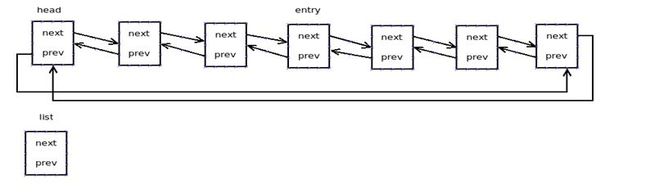
函数执行完:
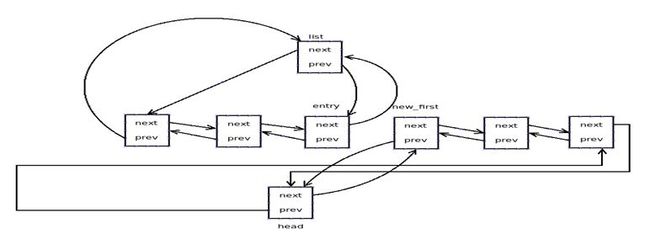
说明:list_cut_position只是添加了一些条件判断,真正的操作是在__list_cut_position函数中完成。
7.链表合并
1>function:
实现将list链表(不包括list结点)插入到head链表中
2>Linux内核链表提供了四个函数接口
static inline void list_splice(const struct list_head *list,struct list_head *head)
static inline void list_splice_init(struct list_head *list,struct list_head *head)
static inline void list_splice_tail(struct list_head *list,struct list_head *head)
static inline void list_splice_tail_init(struct list_head *list,struct list_head *head)
list:新添加的链表
head:将list链表添加到head链表中
3>函数实现
static inline void __list_splice(const struct list_head *list, struct list_head *prev, struct list_head *next)
{
struct list_head *first = list->next;
struct list_head *last = list->prev;
first->prev = prev;
prev->next = first;
last->next = next;
next->prev = last;
}
static inline void list_splice(const struct list_head *list, struct list_head *head)
{
if (!list_empty(list))
__list_splice(list, head, head->next);
}
static inline void list_splice_tail(struct list_head *list, struct list_head *head)
{
if (!list_empty(list))
__list_splice(list, head->prev, head);
}
static inline void list_splice_init(struct list_head *list, struct list_head *head)
{
if (!list_empty(list)) {
__list_splice(list, head, head->next);
INIT_LIST_HEAD(list);
}
}
static inline void list_splice_tail_init(struct list_head *list, struct list_head *head)
{
if (!list_empty(list)) {
__list_splice(list, head->prev, head);
INIT_LIST_HEAD(list);
}
}
(1)四个函数都调用了__list_splice()函数来实现添加链表。
(2)list_splice和list_splice_init表示将新添加的链表用头插法插入在head链表中.他们之间的区别是.list_splice中的list结点没有被初始化,list_splice_init将list结点进行了初始化。
(3) list_splice_tail和list_splice_init表示将新添加的链表list用尾插入法插入在head链表中。他们之间的区别是list_splice_tail和list_splice_init的区别是list_splice_tail中的list结点没有被初始化,而list_splice_tail_init将list结点进行了初始化。
(4)list_splice和list_splice_tail都调用了__list_splice实现将整个list链表(不包括list结点)添加到head链表中,他们的区别是list_splice将list链表添加到head结点之后,list_splice_tail将list链表添加尾结点之后
五.内核链表的遍历操作
遍历链表常用操作。为了方便核心应用遍历链表,linux链表将遍历操作抽象成几个宏。在分析遍历宏之前,先分析下如何从链表中访问到我们所需要的数据项
1.list_entry(ptr,type,member)
1>function:
通过成员指针获得整个结构体的指针
Linux链表中仅保存了数据项结构中list_head成员变量的地址,可以通过list_entry宏通过list_head成员访问到作为它的所有者的结点数据
2>接口:
list_entry(ptr,type,member)
ptr:ptr是指向该数据结构中list_head成员的指针,即存储该数据结构中链表的地址值。
type:是该数据结构的类型。
member:改数据项类型定义中list_head成员的变量名。
3>list_entry宏的实现
#define list_entry(ptr, type, member) \
container_of(ptr, type, member)
list_entry宏调用了container_of宏,关于container_of宏的用法见:
2.list_first_entry(ptr,type,member)
1>function:
这里的 ptr是一个链表的头结点,这个宏就是取的这个链表第一元素所指结构体的首地址。
2>接口:
list_first_entry(ptr,type,member)
ptr:ptr是指向该数据结构中list_head成员的指针,即存储该数据结构中链表的地址值。此处的ptr是一个链表的头结点
type:是该数据结构的类型。
member:该数据项类型定义中list_head成员的变量名。
3>list_entry宏的实现
#define list_first_entry(ptr, type, member) \
list_entry((ptr)->next, type, member)
list_first_entry调用了list_entry来获取ptr链表结点后的第一个结点其结构体的地址。
六链表遍历
1.list_for_each(pos,head)
1>function:
实际上就是一个for循环,以顺时针方向遍历双向循环链表,由于是双向循环链表,所以循环终止条件是pos!=head.在遍历过程中,不能删除pos(必须保证pos->next有效),否则会造成SIGSEGV错误。
2>接口:
list_for_each(pos,head)
pos:pos是一个辅助指针(即链表类型),用于链表遍历
head:链表的头指针(即结构体中成员struct list_head)
3>list_for_each实现
#define list_for_each(pos,head) \
for(pos= (head->next);prefetch(pos->next),pos !=(head); \
pos = pos->head)
Ø pos是辅助指针,pos是从第一个结点开始的,并没有访问结点,直到pos到达结点指针head的时候结束
Ø 遍历是双循环链表的基本操作,head为头节点,遍历过程中首先从(head)->next开始,当pos==head时退出,故head节点并没有访问,这和链表的结构设计有关,通常头节点都不含有其它有效信息,因此可以把头节点作为双向链表遍历一遍的检测标志来使用。在list_for_each宏中读者可能发现一个比较陌生的面孔,我们在此就不将prefetch展开了讲解了,有兴趣的读者可以自己查看下它的实现,其功能是预取内存的内容,也就是程序告诉CPU哪些内容可能马上用到,CPU预先其取出内存操作数,然后将其送入高速缓存,用于优化,是的执行速度更快。
2.__list_for_each
1>function:
功能和list_for_each相同,即以顺时针方向遍历双向循环链表,只不过去掉了prefetch(pos->next)。在遍历过程中,不能删除pos(必须保证pos->next有效),否则会造成SIGSEGV错误。
2> __list_for_each(pos,head)
pos:pos是一个辅助指针(即链表类型),用于链表遍历
head:链表的头指针。
3>实现:
#define __list_for_each(pos,head) \
for (pos =(head)->next;pos!=(head);pos = pos->next)
区别:__list_for_each没有采用pretetch来进行预取。
3.list_for_each_prev
1>function:
2>接口:
list_for_each_prev(pos,head)
3>实现
#define list_for_each_prev(pos,head) \
for(pos = (head)->prev;prefetch(pos->prev),pos !=(head); \
pos = pos->prev)
注:实现方法与list_for_each相同,不同的是用head的前趋结点进行遍历。实现链表的逆向遍历。
4.list_for_each_safe
1>function:
以顺时针方向遍历链表,与list_for_each不同的是使用list_head结构体变量n作为临时存储变量。主要用于链表删除时操作。
2>接口
list_for_each_safe(pos,n,head)
pos:pos是一个辅助指针(即链表类型),用于链表遍历
head:链表的头指针
n:临时指针用于占时存储pos的下一个指针
3>list_for_each_safe实现
#define list_for_each_safe(pos,n,head) \
for (pos = (head)->next,n = pos->next; pos != (head); \
pos = n, n = pos->next)
前面介绍了用于链表遍历的几个宏,它们都是通过移动pos指针来达到遍历的目的。但如果遍历的操作中包含删除pos指针所指向的节点,pos指针的移动就会被中断,因为list_del(pos)将把pos的next、prev置成LIST_POSITION2和LIST_POSITION1的特殊值。当然,调用者完全可以自己缓存next指针使遍历操作能够连贯起来,但为了编程的一致性,Linxu内核链表要求调用者另外提供一个与pos同类型的指针n,在for循环中暂存pos下一个节点的地址,避免因pos节点被释放而造成的断链。
5.list_for_each_prev_safe
1>function:
功能与list_for_each_prev相同,用于逆向遍历链表。不同的是使用list_head结构体变量n作为临时存储变量。主要用于链表删除时操作。
2>接口:
list_for_each_prev_safe(pos,n,head)
list_for_each_safe(pos,n,head)
pos:pos是一个辅助指针(即链表类型struct list_head),用于链表遍历
head:链表的头指针
n:临时指针用于占时存储pos的下一个指针
3>list_for_each_prev_safe实现
#define list_for_each_safe(pos,n,head) \
for (pos = (head)->prev,n = pos->prev; \
prefecth(pos->prev),pos!=(head); \
pos = n, n = pos->prev)
6.用链表外的结构体地址来进行遍历,而不用链表的地址进行遍历
1>funtion:
遍历链表,所不同的是它是根据链表的结构体地址来进行遍历。大多数情况下,遍历链表的时候都需要获得链表节点数据项,也就是说list_for_each()和list_entry()总是同时使用。与list_for_each()不同,这里的pos是数据项结构指针类型,而不是(struct list_head 类型。
Linxu提供了以下函数:
list_for_each_entry
list_for_each_entry_safe
list_for_each_entry_reverse
list_for_each_entry_safe_reverse
2>函数接口
list_for_each_entry(pos,head,member)
pos:用于遍历的指针,只是它的数据类型是结构体类型而不是strut list_head 类型
head:链表头指针
member:该数据项类型定义中list_head成员的变量名。
list_for_each_entry_safe(pos,n,head,member)
pos:用于遍历的指针,只是它的数据类型是结构体类型而不是strut list_head 类型
n: 临时指针用于占时存储pos的下一个指针
head:链表头指针
member:该数据项类型定义中list_head成员的变量名。
list_for_each_entry_rverse(pos,head,member)
pos:用于遍历的指针,只是它的数据类型是结构体类型而不是strut list_head 类型
head:链表头指针
member:该数据项类型定义中list_head成员的变量名。
list_for_each_entry_safe_reverse(pos,n,head,member)
pos:用于遍历的指针,只是它的数据类型是结构体类型而不是strut list_head 类型
n: 临时指针用于占时存储pos的下一个指针
head:链表头指针
member:该数据项类型定义中list_head成员的变量名。
3>函数实现
(1)list_for_each_entry实现
#define list_for_each_entry(pos, head, member) \
for (pos = list_entry((head)->next, typeof(*pos), member); \
&pos->member != (head); \
pos = list_entry(pos->member.next, typeof(*pos), member))
这个函数是根据member成员遍历head链表,并且将每个结构体的首地址赋值给pos,这样的话,我们就可以在循环体里面通过pos来访问该结构体变量的其他成员了。大多数情况下,遍历链表的时候都需要获得链表节点数据项,也就是说list_for_each()和list_entry()总是同时使用。与list_for_each()不同,这里的pos是数据项结构指针类型,而不是struct list_head 类型。
(2)list_for_each_entry_safe(pos,n,head,member)实现
#define list_for_each_entry_safe(pos, n, head, member) \
for (pos = list_entry((head)->next, typeof(*pos), member), \
n = list_entry(pos->member.next, typeof(*pos), member); \
&pos->member != (head); \
pos = n, n = list_entry(n->member.next, typeof(*n), member))
list_for_each_entry_safe与list_for_each_entry功能相同,不同的是list_for_each_entry_safe主要用于链表删除时进行遍历操作。
(3) list_for_each_entry_reverse实现
#define list_for_each_entry_reverse(pos, head, member) \
for (pos = list_entry((head)->prev, typeof(*pos), member); \
&pos->member != (head); \
pos = list_entry(pos->member.prev, typeof(*pos), member))
逆向遍历链表。功能和list_for_each_entry相同,不同的是采用逆序遍历。与list_for_each_prev不同的是这里的pos是数据项结构指针类型,而不是struct list_head 类型。
(4)list_for_each_entry_safe_reverse实现
#define list_for_each_entry_safe_reverse(pos, n, head, member) \
for (pos = list_entry((head)->prev, typeof(*pos), member), \
n = list_entry(pos->member.prev, typeof(*pos), member); \
&pos->member != (head); \
pos = n, n = list_entry(n->member.prev, typeof(*n), member))
逆向遍历链表,与list_for_each_entry_reverse不同的是该函数主要用于删除操作时进行遍历。与list_for_each_prev_safe不同的是这里的pos是数据项结构指针类型,而不是struct list_head 类型
7.list_prepare_entry
1>function:
这个函数是如果pos非空,那么pos的值就为其本身,如果pos为空,那么就从链表头强制扩展一个虚pos指针,这个宏定义是为了在list_for_entry_continue()中使用做准备的。
2>接口:
list_prepare_entry(pos,head,member)
pos: 用于遍历的指针,只是它的数据类型是结构体类型而不是strut list_head 类型
head:链表的头指针
member:该数据项类型定义中list_head成员的变量名。
3>list_prepare_entry 实现
#define list_prepare_entry(pos, head, member) \
((pos) ? : list_entry(head, typeof(*pos), member))
如果pos非空,那么pos的值就为其本身,如果pos为空,那么就从链表头强制扩展一个虚pos指针.
8 如果遍历不是从链表头开始,而是从已知的某个结点pos开始遍历
1>Linux内核链表提供了以下函数实现从已知的某个结点pos开始遍历
list_for_each_entry_continue
list_for_each_entry_continue_reverse
list_for_each_entry_safe_continue
2>函数接口:
list_for_each_entry_continue(pos,head,member)
pos: 用于遍历的指针,只是它的数据类型是结构体类型而不是strut list_head 类型
head: 链表的头指针
member: 该数据项类型定义中list_head成员的变量名。
list_for_each_entry_continue_reverse(pos,head,member)
pos: 用于遍历的指针,只是它的数据类型是结构体类型而不是strut list_head 类型
head: 链表的头指针
member: 该数据项类型定义中list_head成员的变量名。
list_for_each_entry_safe_continue(pos,n,head,member)
pos: 用于遍历的指针,只是它的数据类型是结构体类型而不是strut list_head 类型
n: 临时指针用于占时存储pos的下一个指针
head: 链表的头指针
member: 该数据项类型定义中list_head成员的变量名
3>函数实现:
#define list_for_each_entry_continue(pos, head, member) \
for (pos = list_entry(pos->member.next, typeof(*pos), member); \
&pos->member != (head); \
pos = list_entry(pos->member.next, typeof(*pos), member))
#define list_for_each_entry_continue_reverse(pos, head, member) \
for (pos = list_entry(pos->member.prev, typeof(*pos), member); \
&pos->member != (head); \
pos = list_entry(pos->member.prev, typeof(*pos), member))
#define list_for_each_entry_safe_continue(pos, n, head, member) \
for (pos = list_entry(pos->member.next, typeof(*pos), member), \
n = list_entry(pos->member.next, typeof(*pos), member); \
&pos->member != (head); \
pos = n, n = list_entry(n->member.next, typeof(*n), member))
说明:
(1)list_for_each_entry_continue:从已知的某个结点pos后一个结点开始,进行遍历。
(2)list_for_each_entry_continue_reverse:从已知的某个结点前一个结点开始进行逆序遍历
(3)list_for_each_entry_safe_continue:从已知的某个结点pos后一个结点开始进行遍历,与list_for_each_entry_continue不同的是,它主要用于链表进行删除时进行的遍历。
(4)list_for_each_entry_continue中,传入的pos不能为NULL,必须是已经指向链表某个结点的有效指针。而在list_for_each_entry中对传入的pos无要求,可以为空。因此list_for_entry_continue常常与list_prepare_entry宏一起使用,以确保pos非空。
9.从当前某个结点开始进行遍历
1>function:
从当前某个结点开始进行遍历,list_for_entry_continue是从某个结点之后开始进行遍历。Linux提供了以下函数进行从当前某个结点开始进行遍历
list_for_each_entry_from(pos,head,member)
list_for_each_entry_safe_from(pos,n,head,member)
2>接口
list_for_each_entry_from(pos,head,member)
pos: 用于遍历的指针,只是它的数据类型是结构体类型而不是strut list_head 类型
head: 链表的头指针
member:该数据项类型定义中list_head成员的变量名
list_for_each_entry_safe_from(pos,n,head,member)
pos:用于遍历的指针,只是它的数据类型是结构体类型而不是strut list_head 类型
n: 临时指针用于占时存储pos的下一个指针
head:链表的头指针
member该数据项类型定义中list_head成员的变量名
3>函数实现
(1)list_for_each_entry_from实现
#define list_for_each_entry_from(pos, head, member) \
for (; &pos->member != (head); \
pos = list_entry(pos->member.next, typeof(*pos), member))
可以看到for循环从当前结点开始进行遍历。
(2)list_for_each_entry_safe_from实现
#define list_for_each_entry_safe_from(pos, n, head, member) \
for (n = list_entry(pos->member.next, typeof(*pos), member);\
&pos->member != (head); \
pos = n, n = list_entry(n->member.next, typeof(*n), member))
功能与list_for_each_entry_safe_from相同,不同的是list_for_each_entry_from不能用于遍历链表时进行删除操作,而list_for_entry_safe_entry_from可以用于链表遍历时进行删除操作。
10.list_safe_reset_next
1>function:
通过pos结构体指针获得结构体n的指针(具体在什么场合使用不太清楚,往大牛指点)
2>接口:
list_safe_reset_next(pos,n,member)
pos:用于遍历循环的指针(用于list_for_each_entry_safe遍历中),只是它的数据类型是结构体类型而不是strut list_head 类型
n:在list_for_each_entry_safe中用于临时存储post的下一个指针
member: 该数据项类型定义中list_head成员的变量名
六.内核链表的应用
分析了内核链表就要对其进行应用。个人认为我们可以将其复用到用户态编程中,以后在用户态下编程就不需要写一些关于链表的代码了,直接将内核中list.h中的代码拷贝过来用。也可以整理出my_list.h,在以后的用户态编程中直接将其包含到C文件中。当然,我们也可以在内核层对其进行应用。
代码见:http://download.csdn.net/detail/tigerjb/4887030
说明:切记在删除元素时,要用list_for_each_safe,而不能用list_for_each来遍历链表元素