spark 笔记(二) 参数设置和调优
在迁移相关的spark程序到yarn的过程中间,对有些地方的配置进行了调整和优化, 总结起来,常用的一些设置如下:
1. spark.serializer 对象的序列化设置可以设置成spark的序列化类型,相对比较高效和紧凑,网络传输性能比较好
2. spark.kryoserializer.buffer.mb 用来设置对象序列化占用空间大小,当对象比较大的时候需要设置这个选项
3. spark.akka.frameSize 控制通信中消息的最大容量,默认为10M, 可以根据日志中的serialized size of result 来确定是否有问题
以上相关的配置可以通过以下方式或者在环境变量里面设置:
SparkConf sparkConf = new SparkConf().setAppName("BigData-Wnstance") .set("spark.serializer", "org.apache.spark.serializer.KryoSerializer") .set("spark.kryoserializer.buffer.mb","128") .set("spark.akka.frameSize", "1024");
4. spark.storage.memoryFraction 用来控制缓存的堆空间,如果RDD占用内存较小,可以把该参数设置小一点,不然会在启动的时候默认分配2/3的堆内存用来作为cache.
5. 并行相关的设置
a. num-executors 用来设置执行任务的executor的数量
b. executor-cores 这个是设置每个executor并发数的
c. spark.default.parallelism 用来控制shuffle过程中的task的数量 ,默认为8,需要根据实际数据量进行相应设置,不是越大越好
d. spark.hadoop.mapreduce.input.fileinputformat.split.minsize 用来控制输入文件块的大小,当小文件太多的时候需要设置这个,但是如果设置太大,输入切分较少,也会影响并行度.
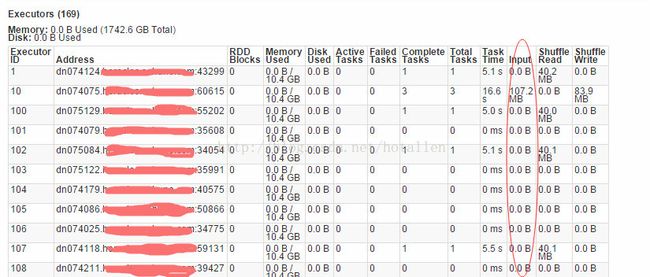
可以通过spark UI查看相关的executor执行情况,看有没有空闲的executor以及输入输出,shuffle的数据量等进行调整. 简单的设置如下: ${SPARK} --queue da \ --executor-memory 10g \ --driver-memory 20g \ --master yarn-cluster \ --num-executors 200 \ --executor-cores 16 \ --conf spark.default.parallelism=400 \ --conf "spark.hadoop.mapreduce.input.fileinputformat.split.minsize=107374182"
以上设置针对spark-yarn来进行设置的,目前用的版本是spark-1.2.1 有些解释不一定全面,但是都做过测试,如有疑问,可以再进行交流,spark发展越来越好了,本身提供了非常好用的工具进行跟踪程序的运行状态以方便调优,毕竟程序写出来是很基本的,如何让程序比较高效、优雅的运行是更重要的。spark新里程碑 通过可视化更好的理解你的程序, 这个功能真是太赞了。参考资料: spark调优