FP-Tree算法的实现
FP-Tree算法的实现
在关联规则挖掘领域最经典的算法法是Apriori,其致命的缺点是需要多次扫描事务数据库。于是人们提出了各种裁剪(prune)数据集的方法以减少I/O开支,韩嘉炜老师的FP-Tree算法就是其中非常高效的一种。
支持度和置信度
严格地说Apriori和FP-Tree都是寻找频繁项集的算法,频繁项集就是所谓的“支持度”比较高的项集,下面解释一下支持度和置信度的概念。
设事务数据库为:
A E F G A F G A B E F G E F G
则{A,F,G}的支持度数为3,支持度为3/4。
{F,G}的支持度数为4,支持度为4/4。
{A}的支持度数为3,支持度为3/4。
{F,G}=>{A}的置信度为:{A,F,G}的支持度数 除以 {F,G}的支持度数,即3/4
{A}=>{F,G}的置信度为:{A,F,G}的支持度数 除以 {A}的支持度数,即3/3
强关联规则挖掘是在满足一定支持度的情况下寻找置信度达到阈值的所有模式。
FP-Tree算法
我们举个例子来详细讲解FP-Tree算法的完整实现。
事务数据库如下,一行表示一条购物记录:
牛奶,鸡蛋,面包,薯片 鸡蛋,爆米花,薯片,啤酒 鸡蛋,面包,薯片 牛奶,鸡蛋,面包,爆米花,薯片,啤酒 牛奶,面包,啤酒 鸡蛋,面包,啤酒 牛奶,面包,薯片 牛奶,鸡蛋,面包,黄油,薯片 牛奶,鸡蛋,黄油,薯片
我们的目的是要找出哪些商品总是相伴出现的,比如人们买薯片的时候通常也会买鸡蛋,则[薯片,鸡蛋]就是一条频繁模式(frequent pattern)。
FP-Tree算法第一步:扫描事务数据库,每项商品按频数递减排序,并删除频数小于最小支持度MinSup的商品。(第一次扫描数据库)
薯片:7鸡蛋:7面包:7牛奶:6啤酒:4 (这里我们令MinSup=3)
以上结果就是频繁1项集,记为F1。
第二步:对于每一条购买记录,按照F1中的顺序重新排序。(第二次也是最后一次扫描数据库)
薯片,鸡蛋,面包,牛奶 薯片,鸡蛋,啤酒 薯片,鸡蛋,面包 薯片,鸡蛋,面包,牛奶,啤酒 面包,牛奶,啤酒 鸡蛋,面包,啤酒 薯片,面包,牛奶 薯片,鸡蛋,面包,牛奶 薯片,鸡蛋,牛奶
第三步:把第二步得到的各条记录插入到FP-Tree中。刚开始时后缀模式为空。
插入第一条(薯片,鸡蛋,面包,牛奶)之后

插入第二条记录(薯片,鸡蛋,啤酒)

插入第三条记录(面包,牛奶,啤酒)
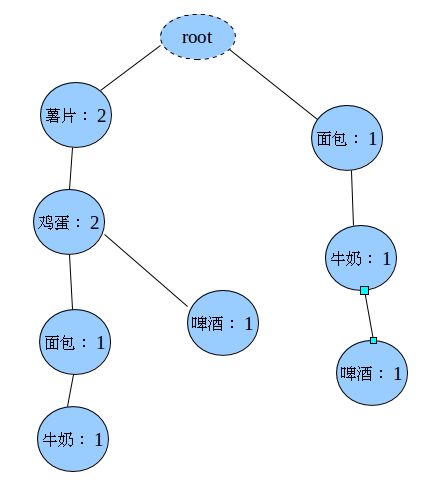
估计你也知道怎么插了,最终生成的FP-Tree是:

上图中左边的那一叫做表头项,树中相同名称的节点要链接起来,链表的第一个元素就是表头项里的元素。
如果FP-Tree为空(只含一个虚的root节点),则FP-Growth函数返回。
此时输出表头项的每一项+postModel,支持度为表头项中对应项的计数。
第四步:从FP-Tree中找出频繁项。
遍历表头项中的每一项(我们拿“牛奶:6”为例),对于各项都执行以下(1)到(5)的操作:
(1)从FP-Tree中找到所有的“牛奶”节点,向上遍历它的祖先节点,得到4条路径:
薯片:7,鸡蛋:6,牛奶:1 薯片:7,鸡蛋:6,面包:4,牛奶:3 薯片:7,面包:1,牛奶:1 面包:1,牛奶:1
对于每一条路径上的节点,其count都设置为牛奶的count
薯片:1,鸡蛋:1,牛奶:1 薯片:3,鸡蛋:3,面包:3,牛奶:3 薯片:1,面包:1,牛奶:1 面包:1,牛奶:1
因为每一项末尾都是牛奶,可以把牛奶去掉,得到条件模式基(Conditional Pattern Base,CPB),此时的后缀模式是:(牛奶)。
薯片:1,鸡蛋:1 薯片:3,鸡蛋:3,面包:3 薯片:1,面包:1 面包:1
(2)我们把上面的结果当作原始的事务数据库,返回到第3步,递归迭代运行。
没讲清楚,你可以参考这篇博客,直接看核心代码吧:
public void FPGrowth(List<List<String>> transRecords, List<String> postPattern,Context context) throws IOException, InterruptedException { // 构建项头表,同时也是频繁1项集 ArrayList<TreeNode> HeaderTable = buildHeaderTable(transRecords); // 构建FP-Tree TreeNode treeRoot = buildFPTree(transRecords, HeaderTable); // 如果FP-Tree为空则返回 if (treeRoot.getChildren()==null || treeRoot.getChildren().size() == 0) return; //输出项头表的每一项+postPattern if(postPattern!=null){ for (TreeNode header : HeaderTable) { String outStr=header.getName(); int count=header.getCount(); for (String ele : postPattern) outStr+="\t" + ele; context.write(new IntWritable(count), new Text(outStr)); } } // 找到项头表的每一项的条件模式基,进入递归迭代 for (TreeNode header : HeaderTable) { // 后缀模式增加一项 List<String> newPostPattern = new LinkedList<String>(); newPostPattern.add(header.getName()); if (postPattern != null) newPostPattern.addAll(postPattern); // 寻找header的条件模式基CPB,放入newTransRecords中 List<List<String>> newTransRecords = new LinkedList<List<String>>(); TreeNode backnode = header.getNextHomonym(); while (backnode != null) { int counter = backnode.getCount(); List<String> prenodes = new ArrayList<String>(); TreeNode parent = backnode; // 遍历backnode的祖先节点,放到prenodes中 while ((parent = parent.getParent()).getName() != null) { prenodes.add(parent.getName()); } while (counter-- > 0) { newTransRecords.add(prenodes); } backnode = backnode.getNextHomonym(); } // 递归迭代 FPGrowth(newTransRecords, newPostPattern,context); } }
对于FP-Tree已经是单枝的情况,就没有必要再递归调用FPGrowth了,直接输出整条路径上所有节点的各种组合+postModel就可了。例如当FP-Tree为:
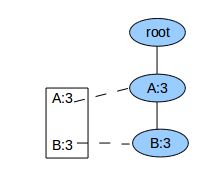
我们直接输出:
3 A+postModel
3 B+postModel
3 A+B+postModel
就可以了。
如何按照上面代码里的做法,是先输出:
3 A+postModel
3 B+postModel
然后把B插入到postModel的头部,重新建立一个FP-Tree,这时Tree中只含A,于是输出
3 A+(B+postModel)
两种方法结果是一样的,但毕竟重新建立FP-Tree计算量大些。
Java实现
FP树节点定义
package
fptree;
import
java.util.ArrayList;
import
java.util.List;
public
class
TreeNode
implements
Comparable<TreeNode> {
private
String name;
// 节点名称
private
int
count;
// 计数
private
TreeNode parent;
// 父节点
private
List<TreeNode> children;
// 子节点
private
TreeNode nextHomonym;
// 下一个同名节点
public
TreeNode() {
}
public
TreeNode(String name) {
this
.name = name;
}
public
String getName() {
return
name;
}
public
void
setName(String name) {
this
.name = name;
}
public
int
getCount() {
return
count;
}
public
void
setCount(
int
count) {
this
.count = count;
}
public
TreeNode getParent() {
return
parent;
}
public
void
setParent(TreeNode parent) {
this
.parent = parent;
}
public
List<TreeNode> getChildren() {
return
children;
}
public
void
addChild(TreeNode child) {
if
(
this
.getChildren() ==
null
) {
List<TreeNode> list =
new
ArrayList<TreeNode>();
list.add(child);
this
.setChildren(list);
}
else
{
this
.getChildren().add(child);
}
}
public
TreeNode findChild(String name) {
List<TreeNode> children =
this
.getChildren();
if
(children !=
null
) {
for
(TreeNode child : children) {
if
(child.getName().equals(name)) {
return
child;
}
}
}
return
null
;
}
public
void
setChildren(List<TreeNode> children) {
this
.children = children;
}
public
void
printChildrenName() {
List<TreeNode> children =
this
.getChildren();
if
(children !=
null
) {
for
(TreeNode child : children) {
System.out.print(child.getName() +
" "
);
}
}
else
{
System.out.print(
"null"
);
}
}
public
TreeNode getNextHomonym() {
return
nextHomonym;
}
public
void
setNextHomonym(TreeNode nextHomonym) {
this
.nextHomonym = nextHomonym;
}
public
void
countIncrement(
int
n) {
this
.count += n;
}
@Override
public
int
compareTo(TreeNode arg0) {
// TODO Auto-generated method stub
int
count0 = arg0.getCount();
// 跟默认的比较大小相反,导致调用Arrays.sort()时是按降序排列
return
count0 -
this
.count;
}
}
|
挖掘频繁模式
package
fptree;
import
java.io.BufferedReader;
import
java.io.FileReader;
import
java.io.IOException;
import
java.util.ArrayList;
import
java.util.Collections;
import
java.util.Comparator;
import
java.util.HashMap;
import
java.util.LinkedList;
import
java.util.List;
import
java.util.Map;
import
java.util.Map.Entry;
import
java.util.Set;
public
class
FPTree {
private
int
minSuport;
public
int
getMinSuport() {
return
minSuport;
}
public
void
setMinSuport(
int
minSuport) {
this
.minSuport = minSuport;
}
// 从若干个文件中读入Transaction Record
public
List<List<String>> readTransRocords(String... filenames) {
List<List<String>> transaction =
null
;
if
(filenames.length >
0
) {
transaction =
new
LinkedList<List<String>>();
for
(String filename : filenames) {
try
{
FileReader fr =
new
FileReader(filename);
BufferedReader br =
new
BufferedReader(fr);
try
{
String line;
List<String> record;
while
((line = br.readLine()) !=
null
) {
if
(line.trim().length()>
0
){
String str[] = line.split(
","
);
record =
new
LinkedList<String>();
for
(String w : str)
record.add(w);
transaction.add(record);
}
}
}
finally
{
br.close();
}
}
catch
(IOException ex) {
System.out.println(
"Read transaction records failed."
+ ex.getMessage());
System.exit(
1
);
}
}
}
return
transaction;
}
// FP-Growth算法
public
void
FPGrowth(List<List<String>> transRecords,
List<String> postPattern) {
// 构建项头表,同时也是频繁1项集
ArrayList<TreeNode> HeaderTable = buildHeaderTable(transRecords);
// 构建FP-Tree
TreeNode treeRoot = buildFPTree(transRecords, HeaderTable);
// 如果FP-Tree为空则返回
if
(treeRoot.getChildren()==
null
|| treeRoot.getChildren().size() ==
0
)
return
;
//输出项头表的每一项+postPattern
if
(postPattern!=
null
){
for
(TreeNode header : HeaderTable) {
System.out.print(header.getCount() +
"\t"
+ header.getName());
for
(String ele : postPattern)
System.out.print(
"\t"
+ ele);
System.out.println();
}
}
// 找到项头表的每一项的条件模式基,进入递归迭代
for
(TreeNode header : HeaderTable) {
// 后缀模式增加一项
List<String> newPostPattern =
new
LinkedList<String>();
newPostPattern.add(header.getName());
if
(postPattern !=
null
)
newPostPattern.addAll(postPattern);
// 寻找header的条件模式基CPB,放入newTransRecords中
List<List<String>> newTransRecords =
new
LinkedList<List<String>>();
TreeNode backnode = header.getNextHomonym();
while
(backnode !=
null
) {
int
counter = backnode.getCount();
List<String> prenodes =
new
ArrayList<String>();
TreeNode parent = backnode;
// 遍历backnode的祖先节点,放到prenodes中
while
((parent = parent.getParent()).getName() !=
null
) {
prenodes.add(parent.getName());
}
while
(counter-- >
0
) {
newTransRecords.add(prenodes);
}
backnode = backnode.getNextHomonym();
}
// 递归迭代
FPGrowth(newTransRecords, newPostPattern);
}
}
// 构建项头表,同时也是频繁1项集
public
ArrayList<TreeNode> buildHeaderTable(List<List<String>> transRecords) {
ArrayList<TreeNode> F1 =
null
;
if
(transRecords.size() >
0
) {
F1 =
new
ArrayList<TreeNode>();
Map<String, TreeNode> map =
new
HashMap<String, TreeNode>();
// 计算事务数据库中各项的支持度
for
(List<String> record : transRecords) {
for
(String item : record) {
if
(!map.keySet().contains(item)) {
TreeNode node =
new
TreeNode(item);
node.setCount(
1
);
map.put(item, node);
}
else
{
map.get(item).countIncrement(
1
);
}
}
}
// 把支持度大于(或等于)minSup的项加入到F1中
Set<String> names = map.keySet();
for
(String name : names) {
TreeNode tnode = map.get(name);
if
(tnode.getCount() >= minSuport) {
F1.add(tnode);
}
}
Collections.sort(F1);
return
F1;
}
else
{
return
null
;
}
}
// 构建FP-Tree
public
TreeNode buildFPTree(List<List<String>> transRecords,
ArrayList<TreeNode> F1) {
TreeNode root =
new
TreeNode();
// 创建树的根节点
for
(List<String> transRecord : transRecords) {
LinkedList<String> record = sortByF1(transRecord, F1);
TreeNode subTreeRoot = root;
TreeNode tmpRoot =
null
;
if
(root.getChildren() !=
null
) {
while
(!record.isEmpty()
&& (tmpRoot = subTreeRoot.findChild(record.peek())) !=
null
) {
tmpRoot.countIncrement(
1
);
subTreeRoot = tmpRoot;
record.poll();
}
}
addNodes(subTreeRoot, record, F1);
}
return
root;
}
// 把交易记录按项的频繁程序降序排列
public
LinkedList<String> sortByF1(List<String> transRecord,
ArrayList<TreeNode> F1) {
Map<String, Integer> map =
new
HashMap<String, Integer>();
for
(String item : transRecord) {
// 由于F1已经是按降序排列的,
for
(
int
i =
0
; i < F1.size(); i++) {
TreeNode tnode = F1.get(i);
if
(tnode.getName().equals(item)) {
map.put(item, i);
}
}
}
ArrayList<Entry<String, Integer>> al =
new
ArrayList<Entry<String, Integer>>(
map.entrySet());
Collections.sort(al,
new
Comparator<Map.Entry<String, Integer>>() {
@Override
public
int
compare(Entry<String, Integer> arg0,
Entry<String, Integer> arg1) {
// 降序排列
return
arg0.getValue() - arg1.getValue();
}
});
LinkedList<String> rest =
new
LinkedList<String>();
for
(Entry<String, Integer> entry : al) {
rest.add(entry.getKey());
}
return
rest;
}
// 把record作为ancestor的后代插入树中
public
void
addNodes(TreeNode ancestor, LinkedList<String> record,
ArrayList<TreeNode> F1) {
if
(record.size() >
0
) {
while
(record.size() >
0
) {
String item = record.poll();
TreeNode leafnode =
new
TreeNode(item);
leafnode.setCount(
1
);
leafnode.setParent(ancestor);
ancestor.addChild(leafnode);
for
(TreeNode f1 : F1) {
if
(f1.getName().equals(item)) {
while
(f1.getNextHomonym() !=
null
) {
f1 = f1.getNextHomonym();
}
f1.setNextHomonym(leafnode);
break
;
}
}
addNodes(leafnode, record, F1);
}
}
}
public
static
void
main(String[] args) {
FPTree fptree =
new
FPTree();
fptree.setMinSuport(
3
);
List<List<String>> transRecords = fptree
.readTransRocords(
"/home/orisun/test/market"
);
fptree.FPGrowth(transRecords,
null
);
}
}
|
输入文件
牛奶,鸡蛋,面包,薯片 鸡蛋,爆米花,薯片,啤酒 鸡蛋,面包,薯片 牛奶,鸡蛋,面包,爆米花,薯片,啤酒 牛奶,面包,啤酒 鸡蛋,面包,啤酒 牛奶,面包,薯片 牛奶,鸡蛋,面包,黄油,薯片 牛奶,鸡蛋,黄油,薯片
输出
6 薯片 鸡蛋 5 薯片 面包 5 鸡蛋 面包 4 薯片 鸡蛋 面包 5 薯片 牛奶 5 面包 牛奶 4 鸡蛋 牛奶 4 薯片 面包 牛奶 4 薯片 鸡蛋 牛奶 3 面包 鸡蛋 牛奶 3 薯片 面包 鸡蛋 牛奶 3 鸡蛋 啤酒 3 面包 啤酒
用Hadoop来实现
在上面的代码我们把整个事务数据库放在一个List<List<String>>里面传给FPGrowth,在实际中这是不可取的,因为内存不可能容下整个事务数据库,我们可能需要从关系关系数据库中一条一条地读入来建立FP-Tree。但无论如何 FP-Tree是肯定需要放在内存中的,但内存如果容不下怎么办?另外FPGrowth仍然是非常耗时的,你想提高速度怎么办?解决办法:分而治之,并行计算。
按照论文《FP-Growth 算法MapReduce 化研究》中介绍的方法,我们来看看语料中哪些词总是经常出现,一句话作为一个事务,这句话中的词作为项。
MR_FPTree.java
1 import imdm.bean.TreeNode; 2 import ioformat.EncryptFieInputFormat; 3 4 import java.io.IOException; 5 import java.text.SimpleDateFormat; 6 import java.util.ArrayList; 7 import java.util.Calendar; 8 import java.util.Collections; 9 import java.util.Comparator; 10 import java.util.LinkedHashMap; 11 import java.util.LinkedList; 12 import java.util.List; 13 14 import org.apache.hadoop.conf.Configuration; 15 import org.apache.hadoop.fs.FSDataInputStream; 16 import org.apache.hadoop.fs.FileSystem; 17 import org.apache.hadoop.fs.Path; 18 import org.apache.hadoop.io.IntWritable; 19 import org.apache.hadoop.io.LongWritable; 20 import org.apache.hadoop.io.Text; 21 import org.apache.hadoop.mapreduce.Job; 22 import org.apache.hadoop.mapreduce.Mapper; 23 import org.apache.hadoop.mapreduce.Reducer; 24 import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat; 25 import org.apache.hadoop.util.GenericOptionsParser; 26 import org.apache.hadoop.util.LineReader; 27 import org.wltea.analyzer.dic.Dictionary; 28 29 import text.outservice.WordSegService; 30 31 public class MR_FPTree { 32 33 private static final int minSuport = 30; // 最小支持度 34 35 public static class GroupMapper extends 36 Mapper<LongWritable, Text, Text, Text> { 37 38 LinkedHashMap<String, Integer> freq = new LinkedHashMap<String, Integer>(); // 频繁1项集 39 40 org.wltea.analyzer.cfg.Configuration cfg = null; 41 Dictionary ikdict = null; 42 43 /** 44 * 读取频繁1项集 45 */ 46 @Override 47 public void setup(Context context) throws IOException { 48 // 初始化IK分词器 49 cfg = org.wltea.analyzer.cfg.DefaultConfig.getInstance(); 50 ikdict = Dictionary.initial(cfg); 51 // 从HDFS文件读入频繁1项集,即读取IMWordCount的输出文件,要求已经按词频降序排好 52 Configuration conf = context.getConfiguration(); 53 FileSystem fs = FileSystem.get(conf); 54 Calendar cad = Calendar.getInstance(); 55 cad.add(Calendar.DAY_OF_MONTH, -1); // 昨天 56 SimpleDateFormat sdf = new SimpleDateFormat("yyyyMMdd"); 57 String yes_day = sdf.format(cad.getTime()); 58 Path freqFile = new Path("/dsap/resultdata/content/WordCount/" 59 + yes_day + "/part-r-00000"); 60 61 FSDataInputStream fileIn = fs.open(freqFile); 62 LineReader in = new LineReader(fileIn, conf); 63 Text line = new Text(); 64 while (in.readLine(line) > 0) { 65 String[] arr = line.toString().split("\\s+"); 66 if (arr.length == 2) { 67 int count = Integer.parseInt(arr[1]); 68 // 只读取词频大于最小支持度的 69 if (count > minSuport) { 70 String word = arr[0]; 71 freq.put(word, count); 72 } 73 } 74 } 75 in.close(); 76 77 } 78 79 @Override 80 public void map(LongWritable key, Text value, Context context) 81 throws IOException, InterruptedException { 82 String[] arr = value.toString().split("\\s+"); 83 if (arr.length == 4) { 84 String content = arr[3]; 85 List<String> result = WordSegService.wordSeg(content); 86 List<String> list = new LinkedList<String>(); 87 for (String ele : result) { 88 // 如果在频繁1项集中 89 if (freq.containsKey(ele)) { 90 list.add(ele.toLowerCase()); // 如果包含英文字母,则统一转换为小写 91 } 92 } 93 94 // 对事务项中的每一项按频繁1项集排序 95 Collections.sort(list, new Comparator<String>() { 96 @Override 97 public int compare(String s1, String s2) { 98 return freq.get(s2) - freq.get(s1); 99 } 100 }); 101 102 /** 103 * 比如对于事务(中国,人民,人民,广场),输出(中国,人民)、(中国,人民,广场) 104 */ 105 List<String> newlist = new ArrayList<String>(); 106 newlist.add(list.get(0)); 107 for (int i = 1; i < list.size(); i++) { 108 // 去除list中的重复项 109 if (!list.get(i).equals(list.get(i - 1))) { 110 newlist.add(list.get(i)); 111 } 112 } 113 for (int i = 1; i < newlist.size(); i++) { 114 StringBuilder sb = new StringBuilder(); 115 for (int j = 0; j <= i; j++) { 116 sb.append(newlist.get(j) + "\t"); 117 } 118 context.write(new Text(newlist.get(i)), 119 new Text(sb.toString())); 120 } 121 } 122 } 123 } 124 125 public static class FPReducer extends 126 Reducer<Text, Text, Text, IntWritable> { 127 public void reduce(Text key, Iterable<Text> values, Context context) 128 throws IOException, InterruptedException { 129 List<List<String>> trans = new LinkedList<List<String>>(); // 事务数据库 130 while (values.iterator().hasNext()) { 131 String[] arr = values.iterator().next().toString() 132 .split("\\s+"); 133 LinkedList<String> list = new LinkedList<String>(); 134 for (String ele : arr) 135 list.add(ele); 136 trans.add(list); 137 } 138 List<TreeNode> leafNodes = new LinkedList<TreeNode>(); // 收集FPTree中的叶节点 139 buildFPTree(trans, leafNodes); 140 for (TreeNode leaf : leafNodes) { 141 TreeNode tmpNode = leaf; 142 List<String> associateRrule = new ArrayList<String>(); 143 int frequency = 0; 144 while (tmpNode.getParent() != null) { 145 associateRrule.add(tmpNode.getName()); 146 frequency = tmpNode.getCount(); 147 tmpNode = tmpNode.getParent(); 148 } 149 // Collections.sort(associateRrule); //从根节点到叶节点已经按F1排好序了,不需要再排序了 150 StringBuilder sb = new StringBuilder(); 151 for (String ele : associateRrule) { 152 sb.append(ele + "|"); 153 } 154 // 因为一句话可能包含重复的词,所以即使这些词都是从F1中取出来的,到最后其支持度也可能小于最小支持度 155 if (frequency > minSuport) { 156 context.write(new Text(sb.substring(0, sb.length() - 1) 157 .toString()), new IntWritable(frequency)); 158 } 159 } 160 } 161 162 // 构建FP-Tree 163 public TreeNode buildFPTree(List<List<String>> records, 164 List<TreeNode> leafNodes) { 165 TreeNode root = new TreeNode(); // 创建树的根节点 166 for (List<String> record : records) { // 遍历每一项事务 167 // root.printChildrenName(); 168 insertTransToTree(root, record, leafNodes); 169 } 170 return root; 171 } 172 173 // 把record作为ancestor的后代插入树中 174 public void insertTransToTree(TreeNode root, List<String> record, 175 List<TreeNode> leafNodes) { 176 if (record.size() > 0) { 177 String ele = record.get(0); 178 record.remove(0); 179 if (root.findChild(ele) != null) { 180 root.countIncrement(1); 181 root = root.findChild(ele); 182 insertTransToTree(root, record, leafNodes); 183 } else { 184 TreeNode node = new TreeNode(ele); 185 root.addChild(node); 186 node.setCount(1); 187 node.setParent(root); 188 if (record.size() == 0) { 189 leafNodes.add(node); // 把叶节点都放在一个链表中 190 } 191 insertTransToTree(node, record, leafNodes); 192 } 193 } 194 } 195 } 196 197 public static void main(String[] args) throws IOException, 198 InterruptedException, ClassNotFoundException { 199 Configuration conf = new Configuration(); 200 String[] argv = new GenericOptionsParser(conf, args).getRemainingArgs(); 201 if (argv.length < 2) { 202 System.err 203 .println("Usage: MR_FPTree EcryptedChartContent AssociateRules"); 204 System.exit(1); 205 } 206 207 FileSystem fs = FileSystem.get(conf); 208 Path inpath = new Path(argv[0]); 209 Path outpath = new Path(argv[1]); 210 fs.delete(outpath, true); 211 212 Job FPTreejob = new Job(conf, "MR_FPTree"); 213 FPTreejob.setJarByClass(MR_FPTree.class); 214 215 FPTreejob.setInputFormatClass(EncryptFieInputFormat.class); 216 EncryptFieInputFormat.addInputPath(FPTreejob, inpath); 217 FileOutputFormat.setOutputPath(FPTreejob, outpath); 218 219 FPTreejob.setMapperClass(GroupMapper.class); 220 FPTreejob.setMapOutputKeyClass(Text.class); 221 FPTreejob.setMapOutputValueClass(Text.class); 222 223 FPTreejob.setReducerClass(FPReducer.class); 224 FPTreejob.setOutputKeyClass(Text.class); 225 FPTreejob.setOutputKeyClass(IntWritable.class); 226 227 FPTreejob.waitForCompletion(true); 228 } 229 }
结束语
在实践中,关联规则挖掘可能并不像人们期望的那么有用。一方面是因为支持度置信度框架会产生过多的规则,并不是每一个规则都是有用的。另一方面大部分的关联规则并不像“啤酒与尿布”这种经典故事这么普遍。关联规则分析是需要技巧的,有时需要用更严格的统计学知识来控制规则的增殖。