HIVE Queryes 查询
SELECT … FROM Clauses
hive> SELECT name, salary FROM employees;
表别名
hive> SELECT name, salary FROM employees; hive> SELECT e.name, e.salary FROM employees e;
Specify Columns with Regular Expressions
hive> SELECT symbol, `price.*` FROM stocks; AAPL 195.69 197.88 194.0 194.12 194.12 AAPL 192.63 196.0 190.85 195.46 195.46 AAPL 196.73 198.37 191.57 192.05 192.05 AAPL 195.17 200.2 194.42 199.23 199.23 AAPL 195.91 196.32 193.38 195.86 195.86
Computing with Column Values
hive> SELECT upper(name), salary, deductions["Federal Taxes"],
> round(salary * (1 - deductions["Federal Taxes"])) FROM employees;
JOHN DOE 100000.0 0.2 80000
MARY SMITH 80000.0 0.2 64000
TODD JONES 70000.0 0.15 59500
BILL KING 60000.0 0.15 51000
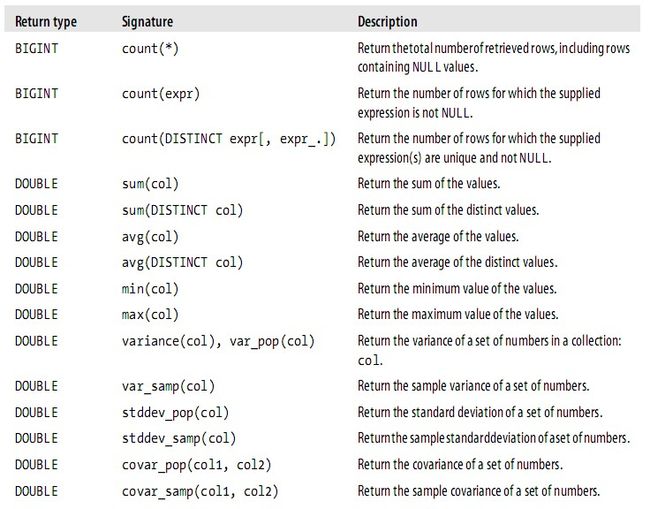
Arithmetic Operators --算数运算
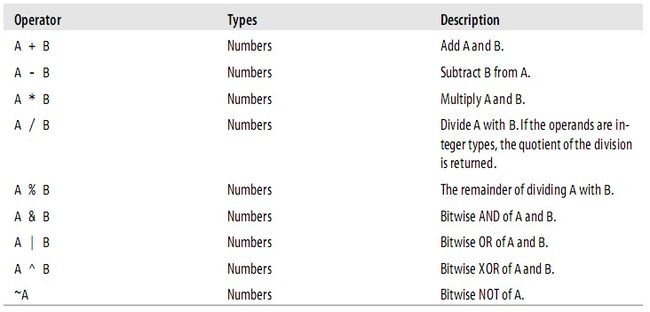
Mathematical functions
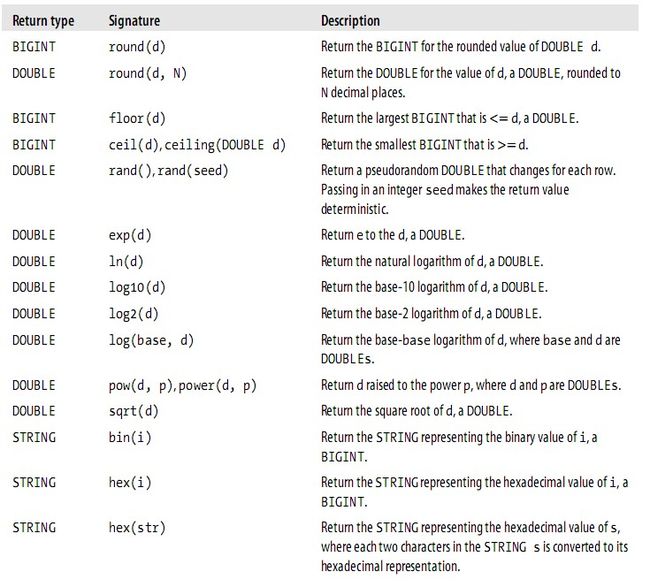


Aggregate functions -- 集合函数

hive> SET hive.map.aggr=true; hive> SELECT count(*), avg(salary) FROM employees;
Table generating functions
hive> SELECT explode(subordinates) AS sub FROM employees; Mary Smith Todd Jones Bill King

Other built-in functions


LIMIT Clause --限制行数
hive> SELECT upper(name), salary, deductions["Federal Taxes"],
> round(salary * (1 - deductions["Federal Taxes"])) FROM employees
> LIMIT 2;
JOHN DOE 100000.0 0.2 80000
MARY SMITH 80000.0 0.2 64000
Column Aliases --列别名
hive> SELECT upper(name), salary, deductions["Federal Taxes"] as fed_taxes,
> round(salary * (1 - deductions["Federal Taxes"])) as salary_minus_fed_taxes
> FROM employees LIMIT 2;
JOHN DOE 100000.0 0.2 80000
MARY SMITH 80000.0 0.2 64000
Nested SELECT Statements --子查询
hive> FROM (
> SELECT upper(name), salary, deductions["Federal Taxes"] as fed_taxes,
> round(salary * (1 - deductions["Federal Taxes"])) as salary_minus_fed_taxes
> FROM employees
> ) e
> SELECT e.name, e.salary_minus_fed_taxes
> WHERE e.salary_minus_fed_taxes > 70000;
JOHN DOE 100000.0 0.2 80000
CASE … WHEN … THEN Statements --case 关键字
hive> SELECT name, salary,
> CASE
> WHEN salary < 50000.0 THEN 'low'
> WHEN salary >= 50000.0 AND salary < 70000.0 THEN 'middle'
> WHEN salary >= 70000.0 AND salary < 100000.0 THEN 'high'
> ELSE 'very high'
> END AS bracket FROM employees;
John Doe 100000.0 very high
Mary Smith 80000.0 high
Todd Jones 70000.0 high
Bill King 60000.0 middle
Boss Man 200000.0 very high
Fred Finance 150000.0 very high
Stacy Accountant 60000.0 middle
WHERE Clauses -- 筛选
SELECT * FROM employees WHERE country = 'US' AND state = 'CA';
hive> SELECT name, salary, deductions["Federal Taxes"],
> salary * (1 - deductions["Federal Taxes"])
> FROM employees
> WHERE round(salary * (1 - deductions["Federal Taxes"])) > 70000;
John Doe 100000.0 0.2 80000.0
hive> SELECT name, salary, deductions["Federal Taxes"],
> salary * (1 - deductions["Federal Taxes"]) as salary_minus_fed_taxes
> FROM employees
> WHERE round(salary_minus_fed_taxes) > 70000;
FAILED: Error in semantic analysis: Line 4:13 Invalid table alias or
column reference 'salary_minus_fed_taxes': (possible column names are:
name, salary, subordinates, deductions, address)
hive> SELECT e.* FROM
> (SELECT name, salary, deductions["Federal Taxes"] as ded,
> salary * (1 - deductions["Federal Taxes"]) as salary_minus_fed_taxes
> FROM employees) e
> WHERE round(e.salary_minus_fed_taxes) > 70000;
John Doe 100000.0 0.2 80000.0
Boss Man 200000.0 0.3 140000.0
Fred Finance 150000.0 0.3 105000.0
Predicate Operators
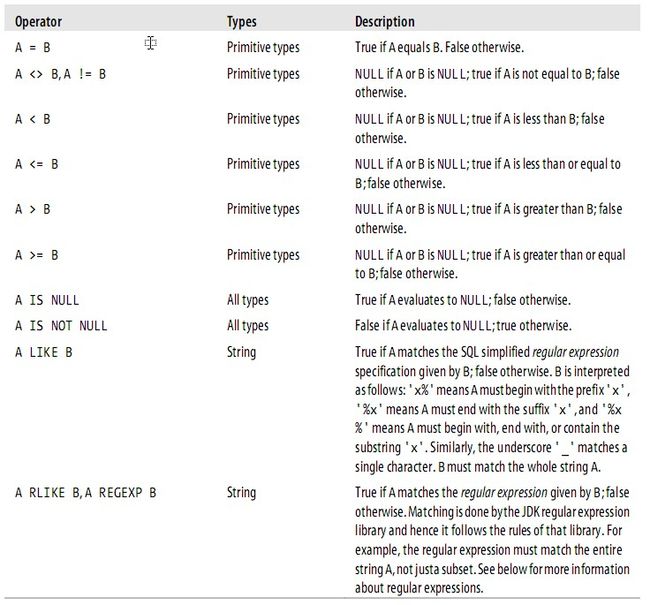
LIKE and RLIKE
hive> SELECT name, address.street FROM employees WHERE address.street LIKE '%Ave.'; John Doe 1 Michigan Ave. Todd Jones 200 Chicago Ave. hive> SELECT name, address.city FROM employees WHERE address.city LIKE 'O%'; Todd Jones Oak Park Bill King Obscuria hive> SELECT name, address.street FROM employees WHERE address.street LIKE '%Chi%'; Todd Jones 200 Chicago Ave.
hive> SELECT name, address.street
> FROM employees WHERE address.street RLIKE '.*(Chicago|Ontario).*';
Mary Smith 100 Ontario St.
Todd Jones 200 Chicago Ave.
SELECT name, address FROM employees WHERE address.street LIKE '%Chicago%' OR address.street LIKE '%Ontario%';
GROUP BY Clauses
hive> SELECT year(ymd), avg(price_close) FROM stocks
> WHERE exchange = 'NASDAQ' AND symbol = 'AAPL'
> GROUP BY year(ymd);
1984 25.578625440597534
1985 20.193676221040867
1986 32.46102808021274
1987 53.88968399108163
1988 41.540079275138766
1989 41.65976212516664
1990 37.56268799823263
1991 52.49553383386182
1992 54.80338610251119
1993 41.02671956450572
1994 34.0813495847914
HAVING Clauses
hive> SELECT year(ymd), avg(price_close) FROM stocks
> WHERE exchange = 'NASDAQ' AND symbol = 'AAPL'
> GROUP BY year(ymd)
> HAVING avg(price_close) > 50.0;
1987 53.88968399108163
1991 52.49553383386182
1992 54.80338610251119
1999 57.77071460844979
2000 71.74892876261757
2005 52.401745992993554
Inner JOIN
hive> SELECT a.ymd, a.price_close, b.price_close
> FROM stocks a JOIN stocks b ON a.ymd = b.ymd
> WHERE a.symbol = 'AAPL' AND b.symbol = 'IBM';
2010-01-04 214.01 132.45
2010-01-05 214.38 130.85
2010-01-06 210.97 130.0
2010-01-07 210.58 129.55
2010-01-08 211.98 130.85
2010-01-11 210.11 129.48
Example 6-1. Query that will not work in Hive
SELECT a.ymd, a.price_close, b.price_close FROM stocks a JOIN stocks b ON a.ymd <= b.ymd WHERE a.symbol = 'AAPL' AND b.symbol = 'IBM';
LEFT OUTER JOIN
hive> SELECT s.ymd, s.symbol, s.price_close, d.dividend
> FROM stocks s LEFT OUTER JOIN dividends d ON s.ymd = d.ymd AND s.symbol = d.symbol
> WHERE s.symbol = 'AAPL';
...
1987-05-01 AAPL 80.0 NULL
1987-05-04 AAPL 79.75 NULL
1987-05-05 AAPL 80.25 NULL
1987-05-06 AAPL 80.0 NULL
1987-05-07 AAPL 80.25 NULL
1987-05-08 AAPL 79.0 NULL
1987-05-11 AAPL 77.0 0.015
1987-05-12 AAPL 75.5 NULL
1987-05-13 AAPL 78.5 NULL
1987-05-14 AAPL 79.25 NULL
1987-05-15 AAPL 78.25 NULL
1987-05-18 AAPL 75.75 NULL
1987-05-19 AAPL 73.25 NULL
1987-05-20 AAPL 74.5 NULL
...
OUTER JOIN Gotcha
hive> SELECT s.ymd, s.symbol, s.price_close, d.dividend
> FROM stocks s LEFT OUTER JOIN dividends d ON s.ymd = d.ymd AND s.symbol = d.symbol
> WHERE s.symbol = 'AAPL'
> AND s.exchange = 'NASDAQ' AND d.exchange = 'NASDAQ';
1987-05-11 AAPL 77.0 0.015
1987-08-10 AAPL 48.25 0.015
1987-11-17 AAPL 35.0 0.02
1988-02-12 AAPL 41.0 0.02
1988-05-16 AAPL 41.25 0.02
...
hive> SELECT s.ymd, s.symbol, s.price_close, d.dividend FROM
> (SELECT * FROM stocks WHERE symbol = 'AAPL' AND exchange = 'NASDAQ') s
> LEFT OUTER JOIN
> (SELECT * FROM dividends WHERE symbol = 'AAPL' AND exchange = 'NASDAQ') d
> ON s.ymd = d.ymd;
...
1988-02-10 AAPL 41.0 NULL
1988-02-11 AAPL 40.63 NULL
1988-02-12 AAPL 41.0 0.02
1988-02-16 AAPL 41.25 NULL
1988-02-17 AAPL 41.88 NULL
RIGHT OUTER JOIN
hive> SELECT s.ymd, s.symbol, s.price_close, d.dividend
> FROM dividends d RIGHT OUTER JOIN stocks s ON d.ymd = s.ymd AND d.symbol = s.symbol
> WHERE s.symbol = 'AAPL';
...
1987-05-07 AAPL 80.25 NULL
1987-05-08 AAPL 79.0 NULL
1987-05-11 AAPL 77.0 0.015
1987-05-12 AAPL 75.5 NULL
1987-05-13 AAPL 78.5 NULL
FULL OUTER JOIN
hive> SELECT s.ymd, s.symbol, s.price_close, d.dividend
> FROM dividends d FULL OUTER JOIN stocks s ON d.ymd = s.ymd AND d.symbol = s.symbol
> WHERE s.symbol = 'AAPL';
...
1987-05-07 AAPL 80.25 NULL
1987-05-08 AAPL 79.0 NULL
1987-05-11 AAPL 77.0 0.015
1987-05-12 AAPL 75.5 NULL
1987-05-13 AAPL 78.5 NULL
...
LEFT SEMI-JOIN
Example 6-2. Query that will not work in Hive
SELECT s.ymd, s.symbol, s.price_close FROM stocks s WHERE s.ymd, s.symbol IN (SELECT d.ymd, d.symbol FROM dividends d);
Instead, you use the following LEFT SEMI JOIN syntax:
hive> SELECT s.ymd, s.symbol, s.price_close
> FROM stocks s LEFT SEMI JOIN dividends d ON s.ymd = d.ymd AND s.symbol = d.symbol;
...
1962-11-05 IBM 361.5
1962-08-07 IBM 373.25
1962-05-08 IBM 459.5
1962-02-06 IBM 551.5
ORDER BY and SORT BY
Here is an example using ORDER BY:
SELECT s.ymd, s.symbol, s.price_close FROM stocks s ORDER BY s.ymd ASC, s.symbol DESC;
Here is the same example using SORT BY instead:
SELECT s.ymd, s.symbol, s.price_cl FROM stocks s SORT BY s.ymd ASC, s.symbol DESC;
Casting
SELECT name, salary FROM employees WHERE cast(salary AS FLOAT) < 100000.0;
Queries that Sample Data -- 抽样
hive> SELECT * from numbers TABLESAMPLE(BUCKET 3 OUT OF 10 ON rand()) s; 2 4 hive> SELECT * from numbers TABLESAMPLE(BUCKET 3 OUT OF 10 ON rand()) s; 7 10 hive> SELECT * from numbers TABLESAMPLE(BUCKET 3 OUT OF 10 ON rand()) s;
hive> SELECT * from numbers TABLESAMPLE(BUCKET 3 OUT OF 10 ON number) s; 2 hive> SELECT * from numbers TABLESAMPLE(BUCKET 5 OUT OF 10 ON number) s; 4 hive> SELECT * from numbers TABLESAMPLE(BUCKET 3 OUT OF 10 ON number) s; 2
hive> SELECT * from numbers TABLESAMPLE(BUCKET 1 OUT OF 2 ON number) s; 2 4 6 8 10 hive> SELECT * from numbers TABLESAMPLE(BUCKET 2 OUT OF 2 ON number) s; 1 3 5 7 9
UNION ALL
SELECT log.ymd, log.level, log.message
FROM (
SELECT l1.ymd, l1.level,
l1.message, 'Log1' AS source
FROM log1 l1
UNION ALL
SELECT l2.ymd, l2.level,
l2.message, 'Log2' AS source
FROM log1 l2
) log
SORT BY log.ymd ASC;
FROM ( FROM src SELECT src.key, src.value WHERE src.key < 100 UNION ALL FROM src SELECT src.* WHERE src.key > 110 ) unioninput INSERT OVERWRITE DIRECTORY '/tmp/union.out' SELECT unioninput.*