K邻近算法(k-NearestNeighbor)简称KNN,是分类算法中的一种。KNN通过计算新数据与历史样本数据中不同类别数据点间的距离对新数据进行分类。简单来说就是通过与新数据点最邻近的K个数据点来对新数据进行分类和预测。
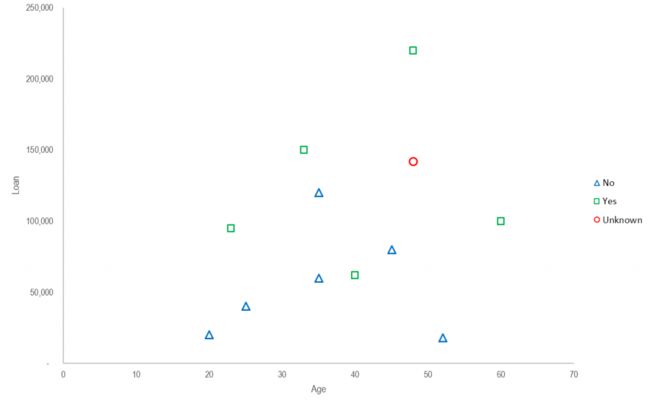
我们以一个实例来说明KNN算法的原理及实现过程。下图是一组贷款用户还款情况的样本数据,其中包含了贷款用户的年龄,贷款金额和是否还款。我们将基于这些历史的贷款样本数据,通过KNN算法对新的贷款用户进行还款预测。

将贷款用户的样本数据按还款情况进行分类,并将两类数据生成散点图。在散点图中,X轴为贷款用户年龄,Y轴为贷款金额。绿色的方块表示已经还款的用户,蓝色的三角表示未还款的用户,红色的圆圈代表新产生的数据(48岁用户贷款142000元)。我们将依据这些已有明确分类的数据点对新产生的数据进行分类和预测。
寻找距离最近的邻居
KNN中对新数据点进行分类的方法是计算它与其他所有数据点间的距离,并以距离最近的点所在的分类作为新数据点的类别。计算距离的方法很多种,欧式距离,曼哈顿距离和闵可夫斯基距离这里我们使用的是欧氏距离。
欧几里德距离评价
欧几里德距离评价在之前的协同过滤中我们已经介绍并使用过。以下是具体的计算公式。通过分别计算新增数据与历史数据在X和Y两个维度上的差值之和来获得距离值。

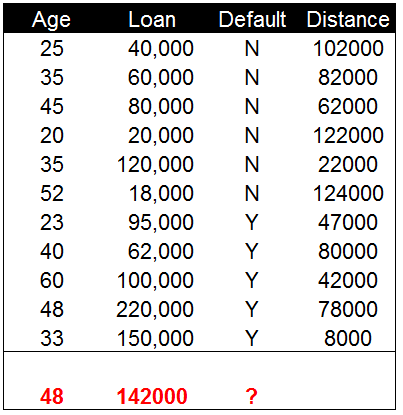
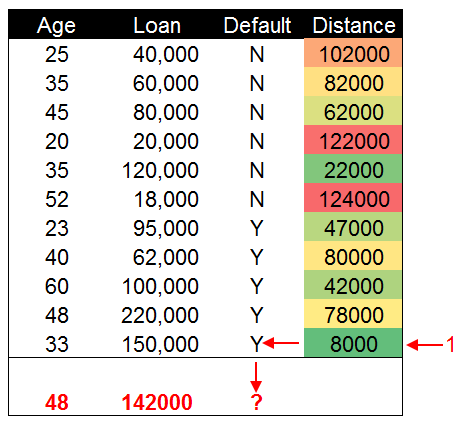
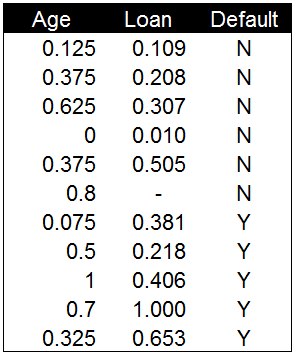
下表是我们通过计算欧式距离获得的距离值,通过这些数据点与新增数据间的距离来对新增数据进行分类。
对数据进行分类
数据分类的方法很简单,将计算获得的距离值进行排序。距离最近的数据点所在的类别就是新增数据的分类。在这个示例中,33岁贷款150000元的数据点与新增数据点距离最近。因此我们认为新增数据点与他属于同一个类别。为会还款的用户分类。
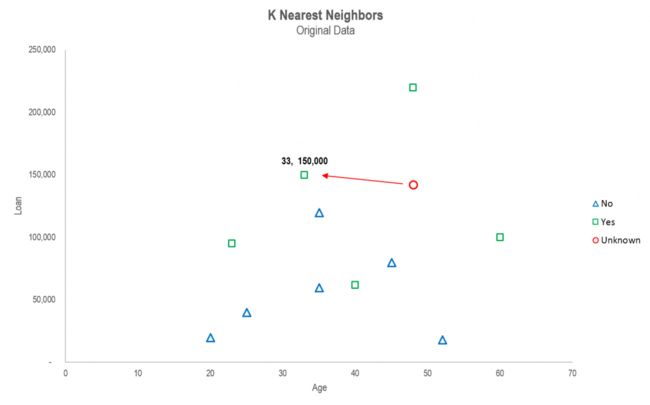
将距离值的计算结果还原到散点图中可以看到,绿色方框与红色圆圈的数据点距离最近,因此新增数据被分类到已还款的类别中。
这里有一个问题。我们判断的两个维度是年龄和借款金额,这里两个维度的数值测量尺度存在较大的差异。贷款金额以万元为单位,而年龄则以年为单位,贷款金额的数值明显要比年龄大很多。这会对计算距离值产生影响,造成距离值的偏差。因此,为了更准确的计算距离值,我们需要先对两类不同测量尺度的数据进行标准化。将数据等比例缩放到0-1区间中,然后再计算他们的距离值。
原始数据0-1标准化
我们使用0-1标准化方法对贷款金额和年龄两个维度的数据进行标准化处理。以下是0-1标准化的计算公式。其中Max为最大值,Min为最小值,X为要进行标准化的数据。

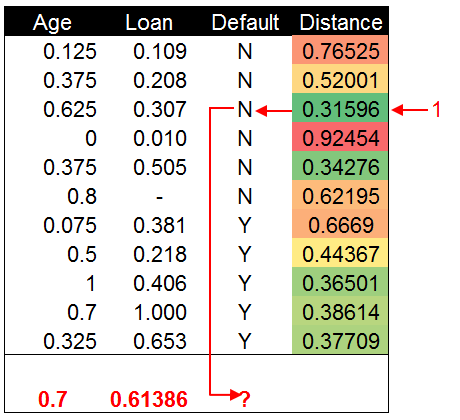
通过0-1标准化后,年龄和贷款金额两组数据都进行了等比例缩放,不再像标准化之前相差悬殊,变成了0-1区间无量纲的纯数值。我们对标准化后的数据再次计算欧式距离。
0-1标准化后的数据在对距离进行排序后我们发现,结果与之前不一致了。标准化前新数据的分类为Y,也就是还款分类。而标准化后新数据被分到了N未还款的分类。
选择并调整K值
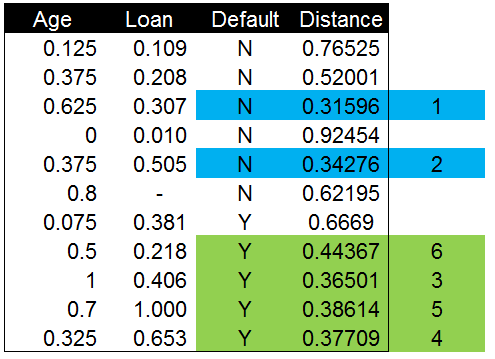
无论是对原始数据的距离计算和分类还是标准化后的分类。我们都是以距离最近的数据点分类来表示的新数据类别。只用一个数据点(K值)进行分类的准确性并不高,并且可能会被数据中的噪声影响而产生错误。一般情况下选择多个K值比只选择一个K值要更加准确,并且可以避免数据中噪声的干扰。最优的K值一般应该在3-10个之间。
这里我们选择了K=6,6个数据点中4个为Y,2个为N。代表还款的Y出现的概率(0.67)要更高一些,所以新的数据点应该被分类为Y。当新数据的结果发生时,我们会将结果与现在的分类和预测进行对比,以调整和优化K值的选择。
—【所有文章及图片版权归 蓝鲸(王彦平)所有。欢迎转载,但请注明转自“蓝鲸网站分析博客”。】—