java 异常处理机制
java异常处理机制
java的异常处理机制可以让程序具有极好的容错性吗,让程序更加健壮。实现将业务功能处理代码和异常处理代码分离,提供更好的可读性。java把所有的非正常情况分为两种,一种是Error,一种是Excepiton。前者指的是虚拟机错误相关的问题,如系统崩溃、虚拟机错误(内存溢出)、动态链接失败等,这种错误是不可恢复的不可捕获的,会导致程序直接退出。后者指的是异常,就是我们通常所说的程序异常,是程序的结果或逻辑不研究导致的。下图展示了java的常见异常类的继承关系。

使用try{}catch(){}finally{}捕获异常
try块用于将可能出现的业务代码放在try块中。catch用于捕获异常,并根据需要在catch块中采取修复补救措施(比如休眠一会,在重新获取数据库连接)。finally块中的代码通常是释放资源的代码(比如释放数据库、网络连接、文件资源),不管是否抛出异常finally块中代码都会被执行。try块后面可以有多个catch块或一个finally块。异常捕获代码如下 :
public static Date exception1(){
try{
Date d = new Date();
d.after(new Date());
return d;
}catch(NullPointerException npe){
System.out.println("捕获NullPointerException."); //1
npe.printStackTrace(); //输出异常栈信息
}catch(Exception e){
System.out.println("未知异常.");
e.printStackTrace();
}finally{
System.out.println("关闭资源.记住哟,我总是被执行的,不管是否抛出异常。");//2
}
System.out.println("finally之后代码...");//3
return null;
}
上面的代码输出的结果是 1、2处信息。我们从上面的代码可以看出在使用catch捕获异常是,需要捕获多个异常信息,子类异常放在前面,父类异常放在后,也就是先捕获小异常,在捕获大异常,一定要记住哟。如果上面代码将Exception异常的捕获放在NullPointerException之前,在编译时就会提示错误,通不过编译。在说一下上述代码的执行流程,try块总的代码Date类型的d应用为null,这是在调用相应方法时,会产生NullPointerException异常,异常被被提交给Java运行时环境,这个过程被称为抛出异常。JRE收到NullPointerException异常对象时,会寻找能处理该异常的catch块,进入该catch块并将异常对象传入,这个过程被称为异常捕获。如果异常没有找到对应的catch块,那么程序就会终止,退出运行。
上面的代码运行返回的是null,假设现在d不是null,是d=new Date(),那么fianlly块还会执行吗,也就是return语句在finally前面了,finally块的代码还会执行吗?
d=new Date()时,输出的结果是 2处信息。说明finally块中的代码是执行的。在return d,将要返回d对象时,会执行finally块中代码。还有一点需要注意,尽量不要在finally使用return或throw抛出一个异常,这样会覆盖之前的return和throws抛出的异常。看下面代码:
public static int finallyTest(){
try{
return 1;
}finally{
return 2; //不建议在finally中使用return 和 throw使程序终止。return 和 throw会使try或catch快中的语句失效
}
//return 3;//此处代码不可达 ,因为return 1和return 2总会执行一个。
}
异常信息的访问
所有的异常对象都包含以下几个方法:
getMessage():返回该异常的详细描述字符串。
printStackTrace():将该异常的跟踪栈信息输出到默认平台上。
printStackTrace(PringStream s):将该异常的跟踪栈信息输出到指定的平台上。
getStackTrace():返回该异常的跟踪栈信息。
checked异常和Runtime异常
java的异常分为两大类:check异常和Runtime异常,我个人理解是也可以叫做编译时异常和运行时异常。所有的RuntimeException异常类本身以及其子异常类都被称为Runtime异常(如NullPointerException、ClassCastException异常)。除了Runtime异常类及其子类异常被称为Runtime异常(如IOExcepiton、SQLException)。
只有java语言提供了checked异常,其他语言并没有提供checked异常。java认为checked异常是可以被修复,可以被处理的的异常类型,所有java程序必须显示的处理checked异常,如果没有处理checked异常将通不过编译(这也就是我个人为什么会将checked异常理解成编译异常),这也体现了java语言的严谨。java程序处理checked异常有两种方法:
- 使用try{}catch(){}捕获异常。
- 使用throws声明抛出异常,表示该方法不知道怎么处理当前的checked异常,抛给该方法的调用者来处理。
public static void checkedException(){
//此行代码在编译时将提示"Unhandled exception type IOException"错误
throw new IOException();
}
public static void runtimeException(){
//此行代码顺利通过编译
throw new NullPointerException();
}从上面的代码中我们可以看到,Runtime异常更加灵活,无需显示来处理,但是需要的时候也可以使用try{}catch{}捕获。checked异常我们在程序中不能视而不见,置之不理,我们必须在方法签名后边throw出异常或使用使用try{]catch(){}捕获异常,虽然这体现了java语言严谨的设计哲学,也可以让我们写出的程序更健壮。checked异常的问题是,我们大多数方法总是不知道如何处理异常,总是throw出异常或者使用它try{]catch{}在catch中指仅仅是打印出异常,并没有处理和修复这种异常,而这种情况又是如此普遍,不想Runtime异常我们可以不管不问,所有checked异常降低了我们的开发效率和代码执行率。checked异常的优劣,在java领域也是一个备受争议的话题。
catch和throw同时使用
前面介绍过对异常的处理有throw异常和使用try{}catch(){}捕获异常。在实际开发过程中往往需要更复杂的处理方式——当一个异常出现的时候,单靠一个方法是不能完全处理该异常的,需要几个方法协作来处理异常。也就说当前方法捕获并对异常部分进行处理,有些异常部分还需要当前方法的调用者来处理,所以应再次抛出该异常,让当前方法的调用者也能捕获异常。这是就可以同时使用catch和throw,捕获并且抛出异常。我们来看一个代码示例:
public class Test10_4_3 {
private static final double initPrice = 30.0;
public static void main(String [] args){
try {
bid("10");
} catch (AuctionExcepiton e) {
// TODO Auto-generated catch block
e.printStackTrace();
}
}
public static void bid(String bidPrice) throws AuctionExcepiton{
double d = 0.0;
try{
d = Double.valueOf(bidPrice);
}catch(ClassCastException cce){
cce.printStackTrace();
//假设catch中以下代码是对异常进行修复或是将异常信息写日志进行记录
System.out.println(cce.getMessage());
//再次抛出异常.根据需要我们也可直接抛出cce异常,捕获的目的只是为了记录日志。
throw new AuctionExcepiton("竞拍价格必须是一个数值,二不是一个字符串(String)\""+bidPrice+"\"");
}catch(Exception e){
e.printStackTrace();
System.out.println(e.getMessage());
}
if(d < initPrice){
throw new AuctionExcepiton("起拍价不能低于"+initPrice+"RMB。");
}
}
}
//一个自定义的异常类
class AuctionExcepiton extends Exception{
public AuctionExcepiton(){}
public AuctionExcepiton(String msg){ super(msg); }
}
异常链
我们一般都将Web项目分为三层(表现层、业务逻辑层、数据持久层),当数据持久层产生SQLException异常是,程序不应将底层产生的SQLException异常出到用户界面,有连个原因:
1,对用户来说看见这样的底层异常对他们使用来说并没有什么帮助。2,对恶意用户而言,将SQLException暴露出来是不安全的。
把底层的异常暴露给用户是不负责任的,通常的做法是:程序先捕获异常,将这种原始的异常记录在程序日志中,然后在抛出一个新业务异常,新的业务异常保函了对用户的提示信息。我们在抛出新的业务异常时一般会将原始的异常作为参数传递给新的业务异常的构造器(例如: new QueryUserException(e),e代表捕获的原始异常),这样我们就可以知道新的业务异常产生的根源异常,形成了一个异常链。
java的异常跟踪栈
异常对象printStackTrace()用于打印异常的跟踪栈信息,我们根据printStackTrace()可以找到异常的源头,也可以看出抛出异常的方法的调用关系。我们通过一个例子来看一下printStrackTrace的例子。
package com.zxy.fkJava;
import java.io.FileInputStream;
import java.io.FileNotFoundException;
public class Test10_5 {
public static void main(String [] args) throws SelfException{
new Test10_5().firstMethod();
}
public void firstMethod() throws SelfException{
secondMethod();
}
public void secondMethod() throws SelfException{
thirdMethod();
}
public void thirdMethod() throws SelfException{
try {
FileInputStream fis = new FileInputStream("");
} catch (FileNotFoundException e) {
//e.printStackTrace();
//throw new SelfException(e); //1
throw new SelfException("自定义异常."); //2
}
}
}
class SelfException extends Exception{
public SelfException(){}
public SelfException(String msg){ super(msg); }
public SelfException(Throwable t){ super(t); }
public SelfException(String msg,Throwable t){ super(msg, t); }
}
控制输入结果如下:
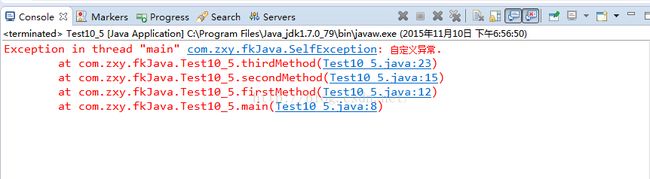
上面程序中main()方法调用firstMethod(),firstMethod()调用secondMethod(),secondMethod()调用thirdMethod(),thirdMethod()方法抛出了一个SelfException异常。我们从控制台异常站信息的打印记过来,com.zxy.fkJavaSelfException是异常的根源,然后依次传递到firstMethod()、secondMethod()、thirdMethod()、main()方法。如果异常没有被捕获或捕获后又抛出,那么异常就会从发生异常的方法逐渐向外传播,直到传递到JVM中,程序终止,JVM打印异常栈信息。我们从控制台打印的异常栈中可以看出:从上到下看是异常传播的顺序,从下向上看是方法调用的顺序。
如果是一个复杂的程序,还会打印出更多的异常栈信息。上面代码中如果把1处注释,把2处注释去掉,控制台打印的异常栈就会多出Caused by异常栈信息(FileNotFoundException e)。
异常处理规则
成功的处理异常应该实现如下4个目标:
- 是程序代码混乱最小
- 捕获并保留诊断信息
- 通知更合适的人员
- 采用合适的方式结束异常,不让程序因为异常停止运行
不要过度的使用异常
java异常机制确实方便,但滥用异常机制也会带来一些负面影响。过度的使用异常主要体现在两个方面:
- 把错误和异常混淆在一起,不在编写任何的错误处理代码,而是用简单的抛出异常来代替所有的错误处理。
- 使用异常来代替逻辑控制。
以上两点都是我们在编程中需要注意的,不要这么去做。
不要使用过于庞大的tyr块
很多初学者异常处理机制的人喜欢在try块中放置大量的代码,看上去很简单,但是这种简单只是一种假象,也仅仅是在写程序上比较简单。这样做造成了两个问题:
- try块中的代码多了,就大大的增加了try中出现异常的可能性,从而导致分析异常原因的难度也大大的增加了。比如一个有100行代码的try块发生异常,你需要梳理、分析这一百行代码。把这100行代码分两个try中,么个try10行,这样则分析时就缩小的分析代码的范围。
- try中的出现异常的可能性增多了,你需要对每种可能性提供catch,就意味着你的catch也跟着多了,catch逻辑也复杂了,反而增加了变成难度。
避免使用catch all( catch(Throwable t){ } )
我们不看否则,我们有时候编程,图一个省力,省时间,就索性的catch all了。这样做不能捕获具体异常,针对具体的异常进行处理。
不要忽略捕获到的异常
我们既然已经捕获到异常,就不要仅仅是在catch块中输出异常,应该在catch块中试着修复异常。记住一定不要在能在catch块中不放代码,编程空catch块,这是极其可怕的,程序不安预期运行,你就是找不到异常和错误。建议对catch的异常采取适当的措施,如下:
处理异常。对异常进行合适的修复,然后绕过异常发生地继续执行。对于checked异常,程序应该尽量修复。
重新抛出异常。将异常包装成当前层的异常,然后重新抛给上层调用者。
在合适的层处理异常。如果当前方法不知道如何处理异常,就不要在当前方法处理,直接抛出该异常,让调用者来处理。