ubuntu下hadoop-2.2.0搭建
环境:vmware10、ubuntu12.04、jdk1.7.0_51、Hadoop2.2.0
安装vmware10;在虚拟机上安装ubuntu12.04;
1.安装Java环境:
在oracle官网下载jdk,桌面新建tools文件夹并放入里面;这里笔者用的是jdk1.7.0_51;
解压:
hp@hp-ubuntu:~/Desktop/tools$ tar -zxvf jdk-7u51-linux-i586.tar.gz
(注:红色为要打的指令。)
把jdk1.7.0_51移动到 /usr下:
hp@hp-ubuntu:~/Desktop/tools$mv jdk1.7.0_51 /usr
检查:

| export JAVA_HOME=/usr/jdk1.7.0_51 export JRE_HOME=/usr/jdk1.7.0_51/jre export CLASSPATH=.:$JAVA_HOME/lib/dt.jar:$JAVA_HOME/lib/tools.jar:$JAVA_HOME/lib:$JRE_HOME/lib:$CLASSPATH export PATH=$JAVA_HOME/bin:$PATH:/usr/local/hadoop/bin export HADOOP_HOME=/usr/local/hadoop
|
修改环境变量:
hp@hp-ubuntu:/etc$vim /etc/profile
把表格里的内容复制到文档最后面:
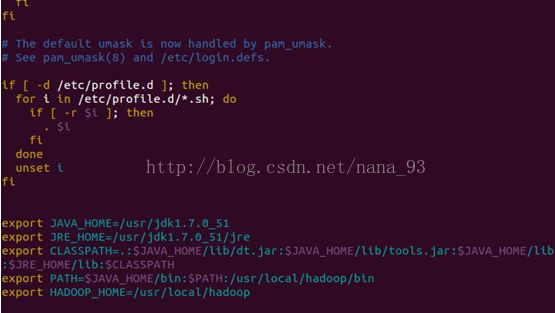
(注:里面的HADOOP等内容是以后Hadoop的环境变量,可以提早在这里一并设置的。)
是环境变量有效:source /etc/profile
检查环境变量是否成功:

生成SSH证书,配置SSH加密key:
sudo apt-get install openssh-server
ssh-keygen -t rsa -P ""
| Generating public/private rsa key pair. |
cat $HOME/.ssh/id_rsa.pub >>$HOME/.ssh/authorized_keys
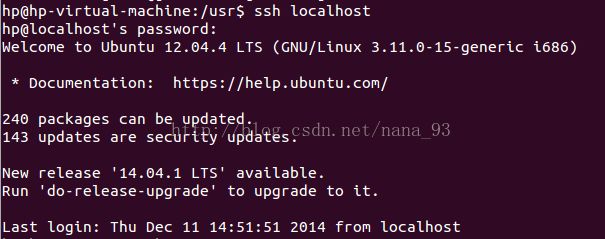
测试配置:
ssh localhost
| The authenticity of host 'localhost (::1)' can't be established. |
2.安装Hadoop环境:
从apache官网下载Hadoop2.2.0放入tools文件夹
(http://mirror.esocc.com/apache/hadoop/common/hadoop-2.2.0/)
解压Hadoop同上jdk,放入/usr/local并且重命名为hadoop
得到:

由于前面配置java环境的时候已经把Hadoop环境也配置好了,所以可以直接检查环境是否生效了:
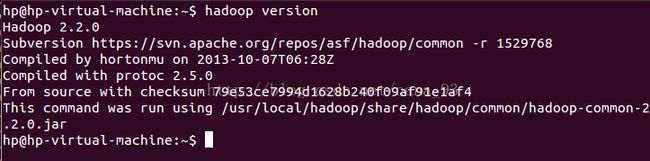
至此,环境已经配置好,接下来就要配置Hadoop的文件了。
3.配置Hadoop:
hp@hp-ubuntu:/usr/local$cd /usr/local/hadoop/etc/hadoop/
修改core-site.xml
| <configuration> <property> <name>fs.defaultFS</name> <value>hdfs://localhost:9000</value> </property> <property> <name>hadoop.tmp.dir</name> <value>/usr/local/hadoop/tmp</value>
</property> </configuration> |
修改hdfs-site.xml:
| <configuration> <property> <name>dfs.replication</name> <value>2</value> </property> <property> <name>dfs.namenode.name.dir</name> <value>/usr/local/hadoop/dfs/name</value> <final>true</final> </property> <property> <name>dfs.datanode.data.dir</name> <value>/usr/local/hadoop/dfs/data</value> <final>true</final> </property> <property> <name>dfs.permissions</name> <final>false</final> </property> </configuration> |
创建并且修改mapred-site.xml
| <configuration> <property> <name>mapred.job.tracker</name> <value>localhost:9001</value> </property> <property> <name>mapreduce.cluster.temp.dir</name> <value></value> <description>No description</description> <final>true</final> </property> <property> <name>mapreduce.framework.name</name> <value>yarn</value> </property> <property> <name>mapred.system.dir</name> <value>/usr/local/hadoop/mapred/system</value> <final>true</final> </property> <property> <name>mapred.local.dir</name> <value>/usr/local/hadoop/mapred/local</value> <final>true</final>
</property> <property> <name>mapred.child.java.opts</name> <value>-Xmx1024m</value> </property> </configuration> |
修改yarn-site.xml:
| <configuration>
<!-- Site specific YARN configuration properties --> <property> <name>yarn.nodemanager.aux-services</name> <value>mapreduce_shuffle</value> </property> <property> <description>The hostname of the RM.</description> <name>yarn.resourcemanager.hostname</name> <value>localhost</value> </property> <property> <name>yarn.scheduler.fair.sizebasedweight</name> <value>false</value> </property> <property> <name>yarn.nodemanager.aux-services.mapreduce_shuffle.class</name> <value>org.apache.hadoop.mapred.ShuffleHandler</value> </property> <!-- <property> <name>yarn.resourcemanager.address</name> <value>127.0.0.1:8032</value> </property> <property> <name>yarn.resourcemanager.scheduler.address</name> <value>127.0.0.1:8030</value> </property> <property> <name>yarn.resourcemanager.resource-tracker.address</name> <value>127.0.0.1:8031</value> </property>--> </configuration> |
修改 hadoop-env.sh
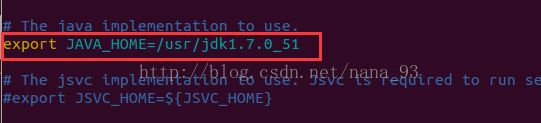
在初次安装和使用hadoop之前,需要格式化分布式文件系统HDFS,使用如下命令格式化文件系统
hadoop namenode -format
启动服务:
命令:sbin/start-all.sh
![]()
停止服务:sbin/stop-all.sh
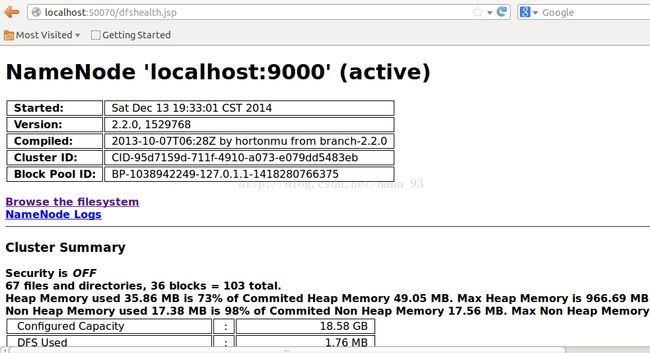
查看服务:

打开浏览器,输入两个网址查看:
http://localhost:50070/dfshealth.jsp
http://localhost:8088/cluster

hp@hp-ubuntu:/usr/local/hadoop# mkdir test/
hp@hp-ubuntu:/usr/local/hadoop#gedit test/test
输入并保存测试数据。
把测试数据放入Hadoop中:
hp@hp-ubuntu:/usr/local/hadoop# hadoop fs -mkdir/test-in
hp@hp-ubuntu:/usr/local/hadoop# hadoop dfs-copyFromLocal test/test /test-in

存在数据。
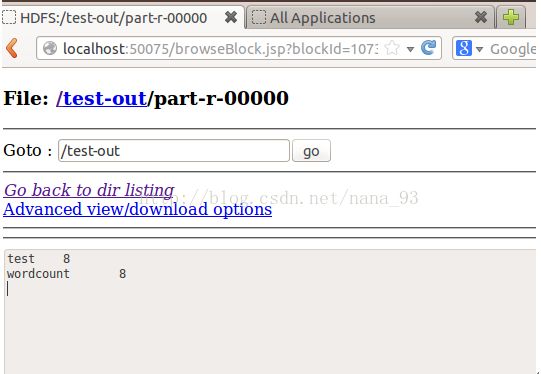
运行wordcount:
hp@hp-ubuntu:/usr/local/hadoop# hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-examples-2.2.0.jar wordcount /test-in/test-out
| 14/05/14 00:08:47 INFO client.RMProxy: Connecting to ResourceManager at localhost/127.0.0.1:8032 14/05/14 00:08:48 INFO input.FileInputFormat: Total input paths to process : 1 14/05/14 00:08:48 INFO mapreduce.JobSubmitter: number of splits:1 14/05/14 00:08:48 INFO Configuration.deprecation: user.name is deprecated. Instead, use mapreduce.job.user.name 14/05/14 00:08:48 INFO Configuration.deprecation: mapred.jar is deprecated. Instead, use mapreduce.job.jar 14/05/14 00:08:48 INFO Configuration.deprecation: mapred.output.value.class is deprecated. Instead, use mapreduce.job.output.value.class 14/05/14 00:08:48 INFO Configuration.deprecation: mapreduce.combine.class is deprecated. Instead, use mapreduce.job.combine.class 14/05/14 00:08:48 INFO Configuration.deprecation: mapreduce.map.class is deprecated. Instead, use mapreduce.job.map.class 14/05/14 00:08:48 INFO Configuration.deprecation: mapred.job.name is deprecated. Instead, use mapreduce.job.name 14/05/14 00:08:48 INFO Configuration.deprecation: mapreduce.reduce.class is deprecated. Instead, use mapreduce.job.reduce.class 14/05/14 00:08:48 INFO Configuration.deprecation: mapred.input.dir is deprecated. Instead, use mapreduce.input.fileinputformat.inputdir 14/05/14 00:08:48 INFO Configuration.deprecation: mapred.output.dir is deprecated. Instead, use mapreduce.output.fileoutputformat.outputdir 14/05/14 00:08:48 INFO Configuration.deprecation: mapred.map.tasks is deprecated. Instead, use mapreduce.job.maps 14/05/14 00:08:48 INFO Configuration.deprecation: mapred.output.key.class is deprecated. Instead, use mapreduce.job.output.key.class 14/05/14 00:08:48 INFO Configuration.deprecation: mapred.working.dir is deprecated. Instead, use mapreduce.job.working.dir 14/05/14 00:08:49 INFO mapreduce.JobSubmitter: Submitting tokens for job: job_1399995699584_0001 14/05/14 00:08:50 INFO impl.YarnClientImpl: Submitted application application_1399995699584_0001 to ResourceManager at localhost/127.0.0.1:8032 14/05/14 00:08:50 INFO mapreduce.Job: The url to track the job: http://localhost:8088/proxy/application_1399995699584_0001/ 14/05/14 00:08:50 INFO mapreduce.Job: Running job: job_1399995699584_0001 14/05/14 00:09:06 INFO mapreduce.Job: Job job_1399995699584_0001 running in uber mode : false 14/05/14 00:09:06 INFO mapreduce.Job: map 0% reduce 0% 14/05/14 00:09:17 INFO mapreduce.Job: map 100% reduce 0% 14/05/14 00:09:28 INFO mapreduce.Job: map 100% reduce 100% 14/05/14 00:09:28 INFO mapreduce.Job: Job job_1399995699584_0001 completed successfully 14/05/14 00:09:28 INFO mapreduce.Job: Counters: 43 File System Counters FILE: Number of bytes read=33 FILE: Number of bytes written=158013 FILE: Number of read operations=0 FILE: Number of large read operations=0 FILE: Number of write operations=0 HDFS: Number of bytes read=220 HDFS: Number of bytes written=19 HDFS: Number of read operations=6 HDFS: Number of large read operations=0 HDFS: Number of write operations=2 Job Counters Launched map tasks=1 Launched reduce tasks=1 Data-local map tasks=1 Total time spent by all maps in occupied slots (ms)=9675 Total time spent by all reduces in occupied slots (ms)=7727 Map-Reduce Framework Map input records=9 Map output records=16 Map output bytes=184 Map output materialized bytes=33 Input split bytes=99 Combine input records=16 Combine output records=2 Reduce input groups=2 Reduce shuffle bytes=33 Reduce input records=2 Reduce output records=2 Spilled Records=4 Shuffled Maps =1 Failed Shuffles=0 Merged Map outputs=1 GC time elapsed (ms)=113 CPU time spent (ms)=4690 Physical memory (bytes) snapshot=316952576 Virtual memory (bytes) snapshot=2602323968 Total committed heap usage (bytes)=293076992 Shuffle Errors BAD_ID=0 CONNECTION=0 IO_ERROR=0 WRONG_LENGTH=0 WRONG_MAP=0 WRONG_REDUCE=0 File Input Format Counters Bytes Read=121 File Output Format Counters Bytes Written=19 |
查看输出: