赖勇浩:应对多核编程革命
多核革命
2001
年,
IBM
推出了基于双核的
Power4
处理器;随后
Sun
和
HP
都先后推出了基于双核架构的
UltraSPARC IV
以及
PA-RISC8800
处理器。但这些面向高端应用的
RISC
处理器曲高和寡,并没有能够引起广大群众的关注。直到
2005
年第二季度,
Intel
发布了基于
X86
的桌面双核处理器,从此多核才走进平常百姓家。
在今天多核处理器已占据了越来越多的市场份额,作为一线的编程人员,我们必须直面多核革命带来的冲击。多核编程,既是机遇也是挑战,如何在这个行业大变革中把握方向、与时俱进,成为摆在我们面前的迫切课题。因为从单核到多核并不像处理器时钟频率的提升那样对程序员而言是透明的,
如果我们的编写的程序没有针对多核的特点来设计,那就不能完全获得多核带来的性能提升。
在这个新旧交替的战国时代,我们有什么选择、能否借鉴以前的开发经验?
是的,人类最为伟大的技能就是能够借鉴之前的经验。我们应该借鉴前人的经验,积极学习并行编程技能同时在实际工作中小心求证、谨慎行动。多核,特别是双核,与双路
SMP
(对称多处理器)架构非常相似:
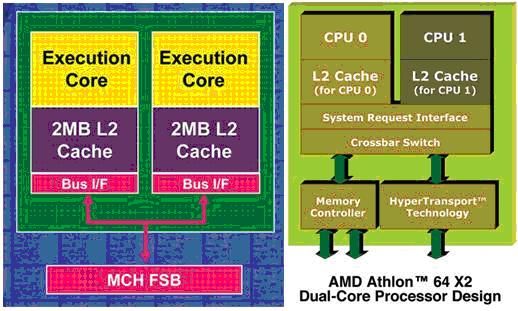
图
1
Intel
和
AMD
的双核
CPU
结构示意图
从图
1
可以看到尽管
Intel
与
AMD
的双核技术有所不同,但仍然可以发现所谓双核处理器就是将两个运算核心集成在一个处理器上。这跟在一块主板上集成两颗处理器的双路
SMP
系统相当相似,不同之处仅在于双核系统两个计算核心之间相互交换数据并不需要通过前端系统总线(
FSB
),而双路系统的两个处理器是通过
FSB
来交换数据的,这也是我们编写程序时需要注意的一个小细节。
就像针对
SMP
编程一样,针对多核处理器编程也必须使用多线程或者多进程的形式来编写应用程序才能够得到多核带来的性能提升。可见
我们在
SMP
并行编程上积累的经验大多都可以应用到多核编程上来。
编程的变革
多核时代的到来,给我们的编程思维带来了巨大的冲击。为了能够充分地利用多核性能,我们必须学会以分块的思维设计程序、以多进程或多线程的形式来编写程序。
到底应该使用多进程还是多线程的形式来编写程序是最让程序员感到困惑的问题之一,
我觉得需要根据具体的应用来决定;但通常情况下使用多线程进行多核编程比使用多进程有更大的优势:
A)
线程的创建和切换开销比进程更小。
B)
线程间通信的方式多而且简单也更有效率。
C)
多线程有汗牛充栋的基础库支持。
D)
多线程的程序比多进程的程序更容易理解和修改。
除了编程形式,
我们使用多线程编程的动机也发生了改变。
在以往,对于
Windows
程序员来说,使用多线程的主要原因之一是为了提高用户体验:如在长时间的计算中提高
UI
、
I/O
或者网络的响应速度。而在多核时代我们编写应用程序为了充分利用多个计算核心,缩短计算时间或者在相同的时间段内计算更多任务。如在游戏编程时通过多线程的方式把碰撞检测的计算分散到多个
CPU
内核可以大大缩减计算时间;也可以利用多核做更细致的检测计算,从而能够模拟更加真实的碰撞。
在多核时代,
我们对编程语言的选择也要更加谨慎。这一小节的内容虽然是个人见解但的确值得系统开发、游戏开发甚至
Web
开发程序员一起探讨。
无论开发何种项目,相对于
C/C++/Fortran
等编译型语言,
C#/java/Python
等脚本语言也许是更好的选择。
原因在于脚本语言比较高级,一般都提供了对多线程的原生支持;如
C#
的
System.Threading.Thread
、
java
的
java.lang.Thread
及
Python
的
Threading.Thread
。相形之下,编译型语言往往都是通过平台相关的库来提供多线程支持,如
Win32 SDK
、
POSIX threads
等。没有统一的标准,造成使用
C/C++
编写多线程程序需要考虑更多的细节,提高了项目成本。从现在来看,
C/C++
的用户虽然不少,但在多核时代脚本语言会更受欢迎,因为船小好调头啊,脚本语言一般都没有
ISO
标准,说改就可以改,很快就会出现针对多核的解释器和编译器了。不过
PHP/Ruby/Lua
等脚本语言就会比较难得到多核程序员们的宠爱了——因为它们并没有提供内核级线程支持,它们的多线程是用户级的甚至不支持线程,用它们编写的多线程程序仍然无法完全利用多核优势。
表
1
各种语言对多线程支持的比较
|
|
C/C++
等编译型语言
|
C#/java/Python
等脚本
|
PHP/Ruby/Lua
等脚本
|
|
语言支持多线程
|
否
|
是
|
否
|
|
库支持多线程
|
是
|
是
|
否
|
|
支持内核级线程
|
是
|
是
|
否
|
|
支持用户级线程
|
可模拟
|
可模拟
|
是
|
|
线程编程复杂度
|
一般
/
易
|
易
|
N/A
|
|
推荐度
|
★★★☆
|
★★★★
|
★☆
|
虽然
C/C++
在多线程编程方面因为没有从语言级提供支持而失去了部分优势;但因为当前的主流操作系统都以
C
语言接口的方式提供创建线程的
API
,而
C/C++
又有相当丰富的程序库,也就一定程度上弥补了语言上的不足。
使用
C/C++
编写多线程程序不仅可以使用
Win32 SDK
,还可以使用
POSIX threads
、
MFC
和
boost.thread
等。
虽然这些库都提供了一定程度的封装,减轻了程序员进行多线程负担,但对于目标定位于提升计算密集型程序的性能的多核程序员来说,这些方式仍然太为复杂。因为使用这些库几乎要增加一倍的关键代码,相应地调试和测试的成本也大大增加。
更好的选择应该是使用
OpenMP
这种通过编译器加强来支持多线程的基础库。
OpenMP
通过使用
#pragma
编译器指令来指定并行代码段,对程序的改动相当少;而且可以指定编译为串行版本以方便调试,更可以和不支持
OpenMP
的编译器共存。
可见即便脚本语言在语言层次上提供了对多线程编程的原生支持,但却并没有比
C/C++
领先多远。根本原因在于脚本语言的基础——
数据结构与算法的基础库
与
CRT/STL
等
C/C++
基础库然一样
是以串行形式来设计开发的
。针对多核编程去修改基础库这一几乎所有编程语言都需要面对的燃眉之急是拉开两大阵营领先优势的生死之战,而所有权集中于某一公司或者组织的
C#/java/Python
这类脚本语言船小好调头,估计将赢得这场关键之役。这就是我在上文推荐选择使用脚本来编写程序的原因之一。
多核程序设计
随着时间推进,我们终将需要面对多核系统来设计程序。多核编程我个人认为基本上等同于共享内存的并行编程,多核程序设计可以借鉴以往并行编程的经验——如分块的设计思维、并行设计方法论和多样的并行支持方式。
首先我们来谈谈分块的设计思维。
因为线程是操作系统分配
CPU
资源的最小单位,所以如果想要设计多核并行的程序,那么我们就要形成将程序分块的设计思维。还记得初中课本上华罗庚先生的《统筹方法》吗?现在我们可以借助华老的这篇文章来谈谈怎么样去分块:
比如,想泡壶茶喝。当时的情况是:开水没有;水壶要洗,茶壶茶杯要洗;火生了,茶叶也有了。怎么办?
办法甲:洗好水壶,灌上凉水,放在火上;在等待水开的时间里,洗茶壶、洗茶杯、拿茶叶;等水开了,泡茶喝。
办法乙:先做好一些准备工作,洗水壶,洗茶壶茶杯,拿茶叶;一切就绪,灌水烧水;坐待水开了泡茶喝。
办法丙:洗净水壶,灌上凉水,放在火上,坐待水开;水开了之后,急急忙忙找茶叶,洗茶壶茶杯,泡茶喝。
哪一种办法省时间?我们能一眼看出第一种办法好,后两种办法都窝了工。
假定华老有两个机器人给他泡茶喝,那最好的方法显然是按照“办法甲”分工:机器人
A
去烧水,机器人
B
洗茶具;等水开了,泡茶喝。看,不经意间,我们就应用了
分块的思维——把不相关的事务分开给不同的处理器执行。
再举个我们工作中经常遇到的例子:有数据类型为
T
的序列
A
,求序列中值与
K
相等的元素个数。实现这个功能的
C++
函数如下:
代码
1
统计序列中值为
K
的元素个数
|
template <class T>
size_t Count(const T& K, const T* pA, int num)
{
size_t cnt = 0;
for(int i = 0; i < num; ++i)
if(pA[i] == K) ++cnt;
return cnt;
}
|
从代码
1
统计序列中值为
K
的元素个数中显而易见
Count(k, p, n) = Count(k, p, n/2) + Count(k, p+n/2, n-n/2)
,即序列中值等于
K
的元素个数为前半段中值为
K
的元素个数加上后半段中值等于
K
的元素个数。如果我们开启两条线程,一条统计前半段(执行
Count(k, p, n/2)
),另一条统计后半段(执行
Count(k, p+n/2, n-n/2)
),那么在双核系统上我们将可以节省一半的运行时间(忽略生成线程的开销等)。
以上分块的思维都是简单直接的,
如果是复杂的任务,就不可能容易地找出分块的方案了,所以需要并行设计的方法论来指导我们。
经过几十年的并行程序研究,前人已经总结出若干行之有效的并行设计方法,在这里介绍一个经典的方法:数据相关图。仍然以《统筹方法》中经典的泡茶为例,我们可以画出以下数据相关图:
图
2
《统筹方法》中办法甲的数据相关图
从图
2
《统筹方法》中办法甲的数据相关图中可以看出数据相关图是一个有向图,其中每个顶点代表一个要完成的任务;箭头表示箭头指向的任务依赖于引出箭头的任务,如果数据相关图中没有从一个任务到另一个任务的路径,那么这两个任务不相关,可以并行处理。如果华老自己动手泡茶喝,那图
2
《统筹方法》中办法甲的数据相关图中红色虚框的部分是可以并行的;而如果华老有两个机器人帮他泡茶,而且有不少于
2
个水龙头供机器人使用,那绿色虚框的部分都可以并行而且能取得更高的效率。
可见能够合理利用的资源越多,并行的加速比率就越高
。
在数据相关图中,如果有不相关的任务对数据集的不同元素进行相同的操作,我们称这种数据相关表现了
数据并行性
。如在科学计算中经常会对某一
N
维向量乘以一个实数值:
for( int i = 0; i < N; ++i)
v[i] *= r;
如果有
N
个处理器,那么这
N
次带有数据并行性的迭代可以同时执行。除了数据并行性,如果有不相关的任务对数据集的不同元素进行不同的操作,则表现了
功能并行性
。还有形状为简单路径或链的数据相关图意味着在处理单个问题上不存在并行性,但如果需要处理多个问题,且每个问题可以分为几个阶段,那么就能支持与阶段数相同的并行性,这种情况称之为
流水线
。关于功能并行性和流水线,由于篇幅关系,这里不能详述,有兴趣的读者可以查阅并行编程相关书籍。
既有了分块的思维,又有并行程序设计的方法论作为指引,
现在我们就缺怎么去开发并行程序了。当前比较流行的思想有以下三种:
一、
扩展编译器。
开发并行化编译器,使其能够发现和表达现有串行语言程序中的并行性,例如
Intel C++ Compiler
就有自动并行循环和向量化数据操作的功能。这种把并行化的工作留给编译器的方法虽然降低了编写并行程序的成本,但因为循环和分枝等控制语句的复杂组合,编译器不能识别相当多的可并行代码而错误地编译成了串行版本。
二、
扩展串行编程语言。
这是当前最为流行的方式,通过增加函数调用或者编译指令来表示低层语言以获取并行程序。用户能够创建和结束并行进程或线程,并提供同步与通信的功能函数等。这方面较为杰出的库有
MPI
和
OpenMP
等;在解释型脚本阵营,
ParallelPython
也吸引了不少粉丝。
三、
创造一个并行语言。
虽然这是一个疯狂的想法,但事实上近几十年来一直有人在做这样的事情,如
HPF
(
High Performance Fortran
)是
Fortran90
的扩展,用多种方式支持数据并行程序。
在以后的多核编程之旅中,我们将会发现上面所述只是沧海一粟,并行计算领域有着更多的知识值得我们学习,也有更广阔的空间给我们实现自己的想法。
新瓶旧酒
虽然多核
CPU
正在成为主流,但毕竟时间不长,现在大部分应用程序都是在单核时代开发的,那么这些旧程序如何才能在新的环境焕发自己新的光彩?在这里我给出自己的几点见解:
1
)
精确地评估旧程序是否需要作出修改。
如
Foxmail
、
Windows
优化大师之类的桌面软件原本就只占用极少的
CPU
资源,那么就不需要针对多核改写。而作为网站服务器端运行的
CGI
程序基本上都是以多进程或多线程的方式来响应请求的,将可以平滑地充分利用多核系统的性能优势,一般而言也不需要针对多核改写。
2
)
就重避轻。
一个应用程序,性能瓶颈通常都只有几个或者一两个甚至这些瓶颈相关的功能还是用户很少使用的。那么为了这些少量需求而对已有程序进行伤筯动骨的改造是不合适的,更不宜以多线程的架构重写整个应用。如果应用程序是使用
C/C++/Fortran
编写的,那使用
OpenMP
使性能瓶颈部分的代码并行化是相当好的选择。如果代码是使用
C#/java/Python
等脚本编写的,可能需要多花一些功夫来完成同样的工作。
3
)
不追逐潮流。
一句话,如果旧的应用程序没有性能瓶颈,那就不要作任何改动,否则只会引火烧身。像暴风影音、千千静听这一类多媒体播放软件,针对多核优化是可做可不做的事情;但如果做了,用户可能反而会觉得太占用资源,因为换了双核系统还觉得播放视频
/
音频的时候做其它事情仍然有点“卡”,那就不如不做。
综上所述,如果我们手上维护着旧的程序,那我们最应该做的事情是评估软件是否有性能瓶颈,切忌为双核而双核,要以不变应万变。
写在最后
多核时代的到来,必定会给编程带来巨大的变化,对此我有几个建议:
一、
并行计算方面已经有相当多的研究人员作了几十年的基础工作,有相当多可以学习和利用的知识。
我们应该学复杂的、用简单的,
复杂如
MPI
也要去了解了解,但应用的时候就越简单越好,如上文代码
1
统计序列中值为
K
的元素个数的函数比较好的并行方案是使用
OpenMP
:
代码
2
使用
OpenMP
并行
|
//
上略
size_t cnt = 0;
#pragma omp parallel for reduciotn(+:cnt)
for(int i = 0; i < num; ++i)
//
下略
|
简单地增加了一行源码就实现了并行,不仅比使用
Win32 SDK/PThreads
创建线程的代码少得多而且更容易维护。
二、
如非必要,不要并行。
一直以来,我们都是接受串行编程的教育,而且大多数程序员都习惯于编写串行程序。即使我们对并行编程进行了学习,实践的时候仍然难免会引起一堆让人手忙脚乱的麻烦。所以现阶段在实际项目中如非必要,不要并行;比较适宜的方式是先在非核心业务中熟悉并行编程,然后再在有必要性的部分工作中实操。
三、
并行可以作为最后的优化手段。
知道在什么时候使用并行跟知道如何编写并行代码一样重要。如果你竭尽全力优化之后程序仍然不能让你的老板、客户满意,那你可以试试将性能瓶颈部分并行化,作为优化的最后选择。
参考资料
书籍类:
·
Micheal J. Quinn
著,陈文光
等译
《
MPI
与
OpenMP
并行程序设计
C
语言版》
清华大学出版社
2004
年
10
月
·
David R. Butenhof
著,于磊
等译
《
POSIX
多线程程序设计》
中国电力出版社
2003
年
4
月
·
Jim Beveridge
等著,侯捷
译
《
Win32
多线程程序设计》
华中科技大学出版社
2002
年
1
月
互联网资料类:
·《统筹方法》
http://hi.baidu.com/civay/blog/item/0bbcb016464e4351f2de3239.html
·《从奔腾
D
到安腾
2
英特尔双核处理器历史》
http://bbs.cfan.com.cn/thread-388811-1-39.html
·《什么是双核处理器》
http://bbs.zol.com.cn/index20060307/index_17_242321.html
作者简介
赖勇浩,男,现供职于网易广州。平时较关注多核编程、
GameAI
和最优化计算等,对
C++/Python
有一定了解。业余喜欢为个人博客
http://blog.csdn.net/lanphaday
撰写编程心得与大家分享。可以通过
Email:[email protected]
和我联系。
转载地址: http://soft.zdnet.com.cn/software_zone/2007/0516/392507.shtml