Indri和Terrier搜索引擎的使用
介绍
Indri和Terrier都是开源的搜索引擎,其中Indri作为Lemur项目的一个重要部分,具有强大的查询接口,易建索引,可扩展,高效率等优点。可以在SourceForge Lemur Project Page中下载。Terrier也是IR领域非常有影响力的开源搜索引擎,Terrier是Glasgow大学用Java语言编写的,具有高效灵活及易于部署等特点,目前最新的版本为Terrier 4.0,可在Terrier官网下载。
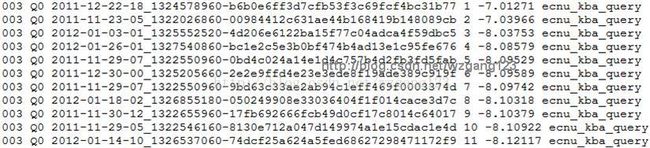
无论Indri还是Terrier整个过程,需要先建立索引,然后根据自定义的query phrases(查询短语,当然也可以是句子),在已建立的索引上查询,并返回一个结果,类似如下(后面会具体讲解每一列的含义):
两个搜索引擎的使用关键在于它们的配置文件,接下来讲解如何配置
文本格式
<DOC> <DOCNO>2011-12-05-20_1323118648-7cfd066125ff1daf479748f81346895d</DOCNO> <date>12/05/2011 (MM/DD/YYYY)</date> <SOURCE>arxiv</SOURCE> <TEXT> S and Λ production in pp interactions at √s = 0.9 and 7 TeV measured with the....</TEXT> </DOC>
1、Indri
Indri建索引
<parameters> <memory>16G<memory> <index>path/to/index</index> //建完索引后,这些索引结果文件存放的位置,如/home/tempUser/myindex <stemmer> <name>krovetz</name> //词干化工具,也即分词,这个是默认的,可以选择其他的 </stemmer> <corpus> <path>path/to/original/file/directory</path> //原始需要建立索引的文件目录 <class>trectext</class> //需要建立什么格式的索引,有xml, txt, trectext, web </corpus> <field> <name>DOCNO</name> //文本ID号 </field> <field> //如果需要用到时间信息,需加此field, <name>date</name> <numeric>true</numeric> <parserName>DateFieldAnnotator</parserName> </field> </parameters>
Indri查询
配置文件
<span style="font-size:14px;"><parameters> <index>path1/to/index</index> <index>path2/to/index</index> <rule>method:dirichlet,mu:1000</rule> //内置方法,用狄利克雷,参数值1000 <count>1000</count> //每个查询值返回1000条记录,可以自己设置 <query> //第一个查询 <number>001</number> //编号自己定义 //如果文本的发布日期在两个时间段之间的,则在其文本中查询“Abbotsford Arts Centre”,根据其内置算法,计算query phrases与文本的相关度值 <text>#scoreif(#datebetween(10/05/2011 01/26/2012) #1(Abbotsford Arts Centre))</text> </query> <query> //第二个查询 <number>003</number> <text>#scoreif(#datebetween(10/05/2011 08/08/2012) #1(Andy Billig))</text> </query> <trecFormat>true</trecFormat> <queryOffset>1</queryOffset> <runID>query_id</runID> //自定义queryID </parameters></span>
Indri查询语言
1、Combining Beliefs
#combine,#weight, #not, #max, #or, #band(boolean and)
#wsum, #wand(weighted and)
#weight( 1 #1(Abbotsford Arts Centre) 0.5 #1(office) 0.5 #1(band))
2、Filter Operators
scoreif(#datebetween(10/05/2011 01/26/2012) #1(Abbotsford Arts Centre))
3、Numeric Field Operator
#less( F N ) matches numeric field extents of type Fif value < N
#greater( F N ), #between(F N_low N_high ) , #equals(F N )
4、Date Field Operator
#dateafter( D ),
#datebefore( D ),
#datebetween( D_low D_high ),
#dateequals( D )
查询结果文件:
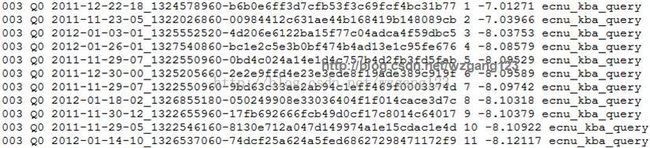
其中:
第一列:表示第003query
第二列:不用理会
第三列:DOCNO
第四列:排名
第五列:具体排序值
第六列:query_id
2、Terrier
Terrier是另一个开源的搜索引擎,可以从官网下载terrier-4.0,下载terrier-4.0.gz后,
解压:tar -xvzf terrier-4.0.gz
得到如下:
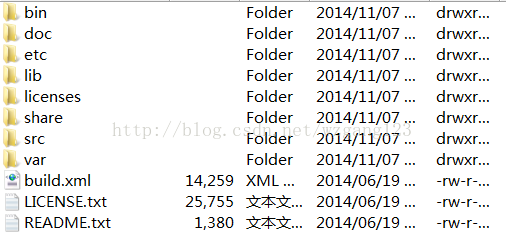
(Terrier是用java开发的,可以去上面图片的src目录下查看源码)
下面分别说说这些目录都是些什么:
bin: 在建索引,检索的时候要用到,在linux系统下用.sh,在windows下用对应的.bat
doc:一些帮助文档集
etc: 存放建立索引和检索时的配置文件
lib:包含terrier能运行所依赖的jar包,如terrier-4.0-core.jar,junit-4.8.1.jar等
licenses: 包含各种依赖包的licenses
src: 搜索引擎源码
var: 默认的索引,检索结果的存放位置(你可以通过修改etc目录下的terrier.properties配置文件,自己定义到别的文件夹)
build.xml:各种依赖关系进行build
在运行terrier之前,首先要确定是否已经安装了jdk,
可以通过:echo $JAVA_HOME,若有值,则表示已经安装,否则需要自己去安装,然后
export JAVA_HOME="Absolute_Path_of_Java_Installation"
建索引:
1)定位到terrier目录cd terrier2)收集需要建索引的文档./bin/trec_setup.sh "Absolute_Path_To_Collection_Files"这里需要指定绝对路径,比如需要建索引的文件集在/home/hadoop/kba/kba2014/trecdata/2011-10目录下(该目录下都为文件,不是目录,Files已经是最后一层目录了),则上面的Absolute_Path_To_Collection_Files即为 /home/hadoop/kba/kba2014/trecdata/2011-10运行后在etc目录下生成如下图:

collection.spec里面的内容如下:
/home/hadoop/kba/kba2014/trecdata/2011-10/2011-10-05-01.trectext /home/hadoop/kba/kba2014/trecdata/2011-10/2011-10-05-03.trectext /home/hadoop/kba/kba2014/trecdata/2011-10/2011-10-05-05.trectext /home/hadoop/kba/kba2014/trecdata/2011-10/2011-10-05-07.trectext /home/hadoop/kba/kba2014/trecdata/2011-10/2011-10-05-08.trectext /home/hadoop/kba/kba2014/trecdata/2011-10/2011-10-05-11.trectext /home/hadoop/kba/kba2014/trecdata/2011-10/2011-10-05-12.trectext /home/hadoop/kba/kba2014/trecdata/2011-10/2011-10-05-13.trectext /home/hadoop/kba/kba2014/trecdata/2011-10/2011-10-05-14.trectext
terrier.properties配置文件的内容如下:
#default controls for query expansion querying.postprocesses.order=QueryExpansion querying.postprocesses.controls=qe:QueryExpansion #default controls for the web-based interface. SimpleDecorate #is the simplest metadata decorator. For more control, see Decorate. querying.postfilters.order=SimpleDecorate,SiteFilter,Scope querying.postfilters.controls=decorate:SimpleDecorate,site:SiteFilter,scope:Scope #default and allowed controls querying.default.controls= querying.allowed.controls=scope,qe,qemodel,start,end,site,scope #document tags specification #for processing the contents of #the documents, ignoring DOCHDR TrecDocTags.doctag=DOC TrecDocTags.idtag=DOCNO TrecDocTags.skip=DOCHDR #set to true if the tags can be of various case TrecDocTags.casesensitive=false #query tags specification TrecQueryTags.doctag=TOP TrecQueryTags.idtag=NUM TrecQueryTags.process=TOP,NUM,TITLE TrecQueryTags.skip=DESC,NARR #stop-words file stopwords.filename=stopword-list.txt #the processing stages a term goes through termpipelines=Stopwords,PorterStemmer
terrier.properties里面的#行表示注释,建立索引时需要注意标签
TrecDocTags表示要建索引的文件的配置
TrecDocTags.idtag:表示需要处理的标签,TrecDocTags.skip=DOCHDR表示要忽略DOCHDR标签,可以有多个,用逗号隔开即可。
文件格式如下:
<DOC> <DOCNO>id</DOCNO> <TEXT>text content</TEXT> </DOC>
TrecQueryTags表示检索的query文件的配置
TrecQueryTags.process表示要处理哪些标签。
文件格式如下:
<TOP> <NUM>003</NUM> //这个相当于你自己给这个query定一个id,所以可以随便写 <TITLE>"Abbotsford Arts Centre" office band "Abbotsford Arts Centre May" company "Abbotsford Arts Centre" </TITLE> //Query Phrases </TOP>
3)建索引:
./bin/trec_terrier.sh -i
建索引的时候如果DOCNO里面的id长度大于默认的20个字符,那就会报错,如下:
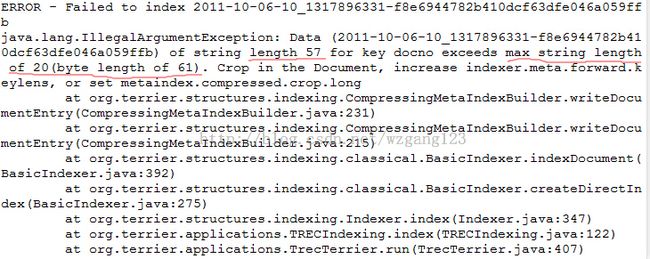
这时需要我们再次配置terrier.properties配置文件,
加入一行
indexer.meta.forward.keylens=120 //你可以自定义长度
再次运行建索引命令就不会报错了
你还可以如下配置:
collection.spec=/absolute/path/to/your.spec terrier.index.path=/absolute/path/to/index/path //你想把你的建好的index放在哪个目录 trec.results.file=/absolute/path/to/resultfile.res //你想想把你的query结果放在哪个文件 ignore.low.idf.terms=false //如果某个词的逆文档频率idf很低,还是要考虑,而不是丢弃 matching.retrieved_set_size=40000 //query后结果有多少条,如果test.query文件写了很多个query,那么这么多个query的返回的结果不大于40000,注意此时不是单个query的结果数
对于所有的properties的含义可以在官网terrier.properties中查看。
4)检索:
./bin/trec_terrier.sh -r -Dtrec.model=PL2 -c 10.99 -Dtrec.topics=/path/to/your.query
-r表示retrieve,
-Dtrec.model表示用什么model去检索,这里用到了PL2模型,具体可在 terrier weighting model中查看
-c表示参数,后面10.99表示参数值
-Dtrec.topics表示your.query文件的具体路径
如果有多个索引文件,多个不同的query,怎么办?
比如对5个文件集分别建立索引,有5个query分别要在对应的索引文件里面找怎么办,由于是共用terrier.properties配置文件的,
所以你可以通过写一个shell脚本,针对不同的文件集,配置对应的collection.spec, terrier.index.path, trec.results.file.
最终得到的结果和开头indri的结果类似。
3、Indri和Terrier注意点
两者在写query phrases时都需要注意不要有其他的字符出现,
indri:除了a-z,A-Z,0-9,空格,其余字符如#@¥%都是非法字符,会导致错误
terrier:除了a-z,A-Z,0-9,空格,在多个单词构成的词组时可用双引号(如"term1 term2 term3"),在表示权重时可用^(如”term1 term2“^0.5),还有某些情况下可用+和-,具体看官网 terrier query language