Spark1.1.0 源码编译和部署包生成
本文转至 《Spark1.1.0 源码编译和部署包生成 》:http://blog.csdn.net/book_mmicky/article/details/25714445
虽然是转载的,但是笔者也尝试了其中的 Maven 编译方法,成功,并附上笔者成功的图片,及补充。
一、编译方式介绍
Spark1.1.0的源码编译和部署包生成,其本质只有两种:Maven和SBT,只不过针对不同场景而已:
- Maven编译
- SBT编译
- IntelliJ IDEA编译(可以采用Maven或SBT插件编译),适用于开发人员
- 部署包生成(内嵌Maven编译),适用于维护人员
编译的目的是生成指定环境下运行Spark本身或Spark Application的JAR包。缺省编译所支持的hadoop环境是hadoop1.0.4。Spark1.1.0的编译对几种编译方法(Maven、SBT、make-distribution.sh)进行了配置项的统一,都可以使用Maven的profile配置项;另外,对于需要额外版权的集成组件也提供了Maven配置项,如spark-ganglia-lgpl、kinesis-asl,方便了用户的编译。在本例中,笔者使用的环境是hadoop2.2.0,支持hive,并和ganglia、kinesis-asl集成。
二、获取Spark1.1.0 源码
官网下载地址http://spark.apache.org/downloads.html
或者笔者网百度云盘,链接:http://pan.baidu.com/s/1hqjjLLa 密码:8z7c
三、SBT 编译
将源代码复制到指定目录,然后进入该目录,运行:
sbt/sbt assembly -Pyarn -Phadoop-2.2 -Pspark-ganglia-lgpl -Pkinesis-asl -Phive 四、Maven编译
事先安装好maven3.2.1,并设置要环境变量MAVEN_HOME,将$MAVEN_HOME/bin加入PATH变量。具体可以参考:Centos6.5 下 Maven 安装。然后将源代码复制到指定目录,然后进入该目录,先设置Maven参数:
export MAVEN_OPTS="-Xmx2g -XX:MaxPermSize=512M -XX:ReservedCodeCacheSize=512m" 再到源码目录下运行:
mvn -Pyarn -Phadoop-2.2 -Pspark-ganglia-lgpl -Pkinesis-asl -Phive -DskipTests clean package | tee spark-1.1.0-bin-2.2.0-building.txt其中 tee spark-1.1.0-bin-2.2.0-building.txt 是将编译的结果不仅显示到屏幕上,同时也保存到 spark-1.1.0-bin-2.2.0-building.txt 文件中,便于日后研究,虽然也懒的研究…

编译之前的目录结构:

编译之后的目录,总共 446 M 大小

五、IntelliJ IDEA编译
IntelliJ IDEA是个优秀的scala开发IDE,所以顺便就提一下IntelliJ IDEA里的spark编译。
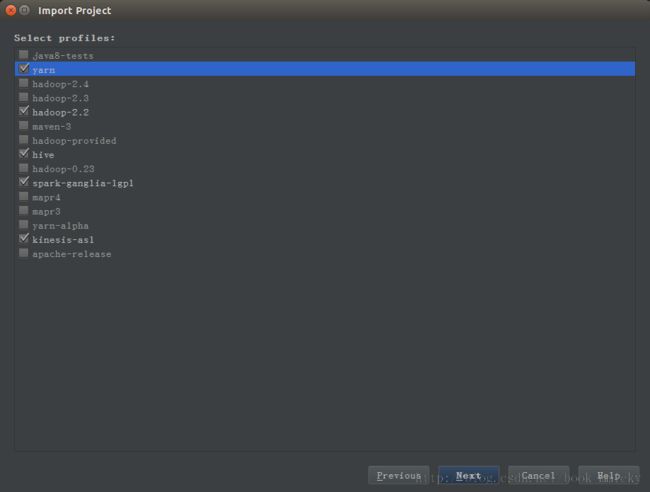
首先将源代码复制到指定目录,然后启动IDEA -> import project -> import project from external model -> Maven编译目录中的pom.xml -> 在选择profile时选择配置(如hadoop2.2、yarn、hive等) -> 直到导入项目。
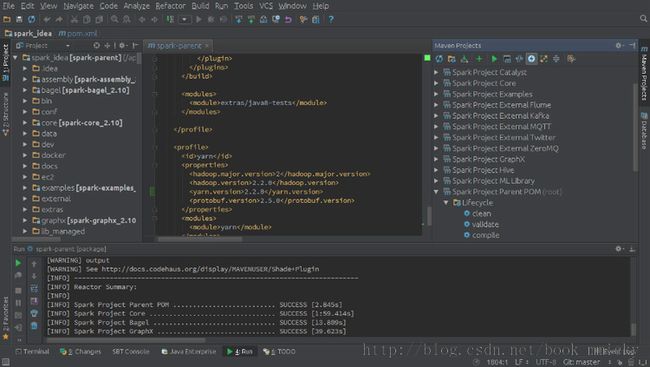
在maven projects视图选择Spark Project Parent POM(root),然后选中工具栏倒数第四个按钮(ship Tests mode)按下,这时Liftcycle中test是灰色的。
接着按倒数第一个按钮进入Maven设置,在runner项设置VM option:
-Xmx2g -XX:MaxPermSize=512M -XX:ReservedCodeCacheSize=512m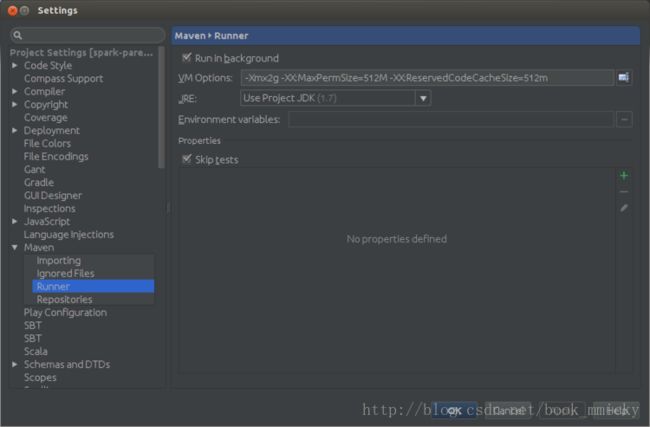
按OK 保存。
回到maven projects视图,点中Liftcycle中package,然后按第5个按钮(Run Maven Build按钮),开始编译。其编译结果和Maven编译是一样的。
六、生成spark部署包
编译完源代码后,虽然直接用编译后的目录再加以配置就可以运行spark,但是这时目录很庞大,有446M左右多吧,部署起来很不方便,所以需要生成部署包。
spark1.1.0源码根目录下带有一个脚本文件make-distribution.sh可以生成部署包,其用法和spark1.0.0有了较大变动,开始支持MAVEN的配置参数,用法如下:
./make-distribution.sh [--name] [--tgz] [--with-tachyon] <maven build options> –with-tachyon:是否支持内存文件系统Tachyon,不加此参数时不支持tachyon
–tgz:在根目录下生成 spark-$VERSION-bin.tgz,不加此参数时不生成tgz文件,只生成/dist目录
–name NAME:和–tgz结合可以生成spark- VERSION−bin− NAME.tgz的部署包,不加此参数时NAME为hadoop的版本号
如果要生成spark支持yarn、hadoop2.2.0、hive的部署包,只需要将源代码复制到指定目录,进入该目录后运行:
./make-distribution.sh --tgz --name 2.2.0 -Pyarn -Phadoop-2.2 -Phive 如果要生成spark支持yarn、hadoop2.2.0、ganglia、hive的部署包,只需要将源代码复制到指定目录,进入该目录后运行:
./make-distribution.sh --tgz --name 2.2.0 -Pyarn -Phadoop-2.2 -Pspark-ganglia-lgpl -Phive 
生成在部署包位于根目录下,文件名类似于spark-1.1.0-bin-2.2.0.tgz

make 成功之后,整个包为 817 M ,其中 spark-1.1.0-bin-2.2.0.tgz 大致为 182M
值得注意的是:make-distribution.sh已经带有Maven编译过程,所以不需要先编译再打包。
七、后记
解压部署包后或者直接在编译过的目录,通过配置conf下的文件,就可以使用spark了。
Spark有下列几种部署方式:
- Standalone
- YARN
- Mesos
- Amazon EC2
其实说部署,还不如说运行方式,Spark只是利用不同的资源管理器来申请计算资源。其中Standalone方式是使用Spark本身提供的资源管理器,可以直接运行;而在YARN运行,需要提供运行Spark Application的spark jar包(或者直接在YARN节点上部署Spark jar包):
maven编译的jar包为:./assembly/target/scala-2.10/spark-assembly-1.1.0-hadoop2.2.0.jar
SBT编译的jar包为:./assembly/target/scala-2.10/spark-assembly-1.1.0-hadoop2.2.0.jar
PS:众所周知的网络问题,编译的时候经常会发生卡死的现象,对于maven编译,只需要安ctrl+z结束进程重新编译就可以了;而对于sbt编译,由于有时候会有文件锁定的问题,在按ctrl+z结束进程后,最好退出终端后再开启一个新的终端进行编译。