浏览器端技术体系概览 -- 前端开发的七种武器
转载地址:http://limu.iteye.com/blog/986724
科普文一则,说说我对前端技术体系(也称浏览器端技术体系)的认识,希望能让更多人了解前端,也希望能借此丰富前端开发的大局观.
去年我写了网站性能优化系列文章,看过的朋友会知道,这类文章重点并非介绍各种具体的优化技巧,而是在关注发掘这些优化点的思路和方法.然后介绍给大家多种检测手段去发现问题,进而有目标的解决问题.所有这些需要我们对有网页整个生命周期有清晰的认识,对网页中各种技术极其相互结合的方式有明确的认知.这就回归到一个更本质的问题:浏览器端技术体系是怎样的.
想用三言两语说清前端技术不大可能,但是用一篇不长的文章说清何谓前端,还是可以做到的.因为工作中我常会给后台开发的同学介绍前台技术,所以会经常涉及这类话题.
解析前端,我想需要回答如下几个问题.
1.前端涉及几种技术?分别是做什么的?
2.在前端内部各种技术之间如何整合协作?
3.前端如何和后台交流?
回答这些问题我会立即丢出前端开发的"七种武器"论,介绍前端主要涉及七种技术分别是什么的同时,重点关注"七种武器"如何对内协作,如何对外交流.(鉴于本文的科普文性质,下面具体介绍中出现的"一切","都是","全部"这类定语可能并非绝对,但可以确定在99%的情况下是正确的)
一.HTTP:网页上的一切来自Http请求
页面上所有内容都是通过若干Http请求从服务端加载而来.
第一个请求通常是一份(X)HTML文档,也就是浏览器中地址栏的指向.如图:
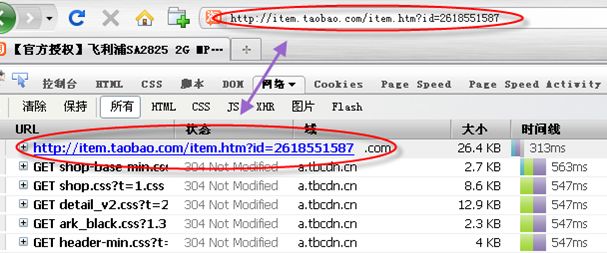
(这张图可以通过Fixfox的Firebug插件,IE的Httpwatch工具,或者Chrome直接按Ctrl+Shift+I得到)
地址栏中的url通常会包含地址和一些参数,这样就可以找到对应的后台服务,同时让其据这些动态参数来确定输出内容.
多个Http请求之间是独立的.那么其他请求又是由谁触发的呢?
由浏览器触发!是在浏览器解析这第一份(X)HTML文档的过程中发出,接下来我就将介绍这个过程.
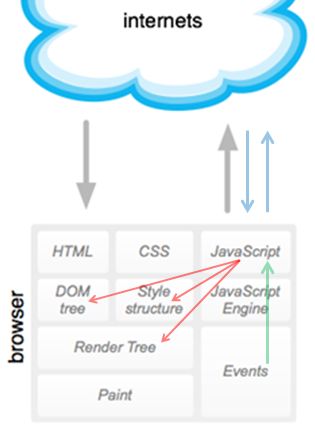
二.HTML:在浏览器中HTML被解析成DOM树
HTML文档是一份不那么严谨的XML(文本)文档.在任意网页上点击右键,点击查看源代码就可以看到.
浏览器按照HTML文档内容自上而下的解析运行.最终HTML文本被完整的解析成一颗树,称DOM树.
注意:DOM树是浏览器内一切所依附的根本,是本文的重点,以后也会多次强调.
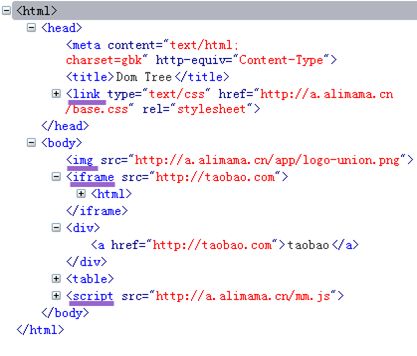
(这张图可以通过Fixfox的Firebug插件,IE8/9按F12,或者Chrome直接按Ctrl+Shift+I找到)
继续回答之前的问题:其余的HTTP请求,除XHR(后面会介绍),CSS的@import和背景图之外,几乎都是在解析HTML时,由DOM树上的几种特定节点发起的.如图中重点标示出的那些节点:
三.CSS:使用CSS设定展现样式和网页布局
如何定义网页的样式,比如字体的颜色和大小?这是CSS的工作.
Html代码

- <!--CSS出现之前,使用额外的样式节点-->
- <span><font size="50" color="red">文本</font></span>
- <!--CSS,统一在节点的style属性内定义-->
- <span style="color:red,font-size:50px">文本</span>
- <!--CSS,在节点之外统一定义,通过class,id等属性关联至节点-->
- <span class="myTxt">文本</span>
我们看到最后一种方式,为<span>节点指定了class属性myTxt.而myTxt的详细定义可以以两种方式加入文档.
Html代码
- <!--在style标签内定义-->
- <style>
- .myTxt:{color:red,font-size:50px}
- </style>
- <!--通过<link>标签引入额外的css,内部包含myTxt类的样式定义-->
- <link rel="stylesheet" type="text/css" href="http://a.com/a.css"/>
当然CSS的功能不止是简单的样式定义,还可以通过定义区块的位置确定网页布局方式,CSS也自然有其一套语法,描述CSS的功能,以及确定CSS规则与DOM节点之间的关联.这些细节并非本文重点.
我们看到CSS或者通过节点的style属性,或者通过特定的<style><link>节点影响网页,这又回到了我们反复强调的内容,DOM树,CSS并未脱离DOM树,而是驻留其上.
四.JavaScript:使用JavaScript处理交互事件
说到JavaScript,不如先澄清下"Java与JavaScript的关系是雷锋与雷峰塔的关系".
网页应用是典型的事件驱动GUI系统.JavaScript为交互事件,时间线上的事件定义响应体.
我们看一个简单的应用,点击按钮,弹出一个警告框.
Html代码
- <!--直接写在onclick属性中-->
- <button onclick="alert(1)"></button>
- <!--在onclick属性中,调用test_clk方法-->
- <button onclick="test_clk()"></button>
- <!--在script标签中,定义test_clk方法-->
- <script>
- function test_clk(){
- alert(1);
- }
- </script>
- <!--在script标签引入外部js文件,内部包含test_clk方法的定义-->
- <script src="http://a.com/a.js"></script>
接下来我们有个问题,js什么时候运行?
重要的是我们还是看到了,JS同样没有脱离DOM树.同CSS一样驻留DOM树上.同时需要明确的是JS是被load到客户端浏览器之后,在浏览器中运行的,消耗的是客户端计算资源.JS为浏览器端提供了计算能力,而浏览器端则是JS的宿主.JS作为一种脚本语言,其实并不一定非要工作在浏览器这个宿主之上,但这脱离了前端技术体系,这里不讨论.
说到这里,我们基本了解了构成一个独立网页的几项要素,各自负责什么,相互间如何协作.大家可能注意到,前面曾经说过每个http请求时相互独立的,那么如何让各个网页关联起来呢?
首先网页之间通过链接<a>或<form>表单关联到一起.一般情况,网页之间通过点击<a>形成一个新的执行a标签href属性的HttpGet请求,让浏览器从一个页面转向另一个.
当需要浏览者通过客户端提交数据时,我们通常制作一个表单,然后submit表单,将客户数据将会通过HttpPost请求提交至另一个地址.
除此之外的另一个需求就是保持登陆状态了,这需要一段信息始终在各个网页间传递,但是放在url参数中显然是不安全的.那如何实现这个功能?这正是接下来介绍的内容.
五.Cookie:借助Cookie标识浏览者身份,在页面间保持会话
再次回到Http本身,它是一种无状态的协议,分为Header和Body两部分,Body是http传递的主体内容,Header又分为请求头(RequestHeader)和(ResponseHeader)两部分,而header中除了包含表明网页间关系的参数之外也包含一些通用信息,头当中的信息以键值对的方式书写,主要负责通用的缓存策略描述和身份标识等功能,如图:
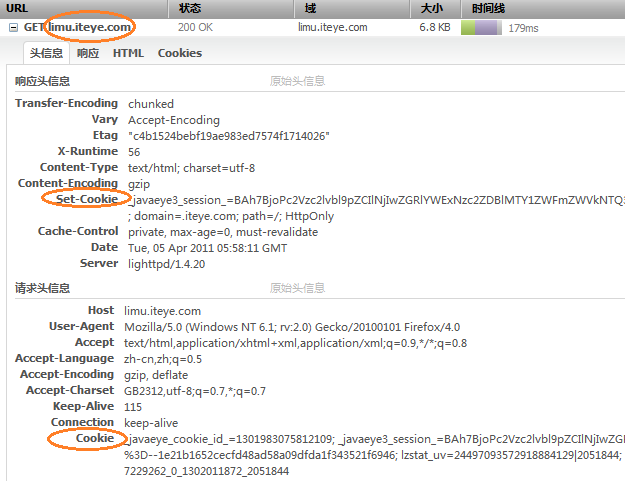
(这张图,即为第一张图中某个http请求点开之后看到的详情,需要注意图中上面列出了响应头,下面是请求头,和发生顺序不一致.firebug就是这个顺序,注意区分)
服务端可以通过响应头种植cookie到客户端,而客户端的每个请求的请求头中都会携带域名下的cookie.比如这个到limu.iteye.com的请求,会包含iteye.com下的cookie,同时也包括limu.iteye.com的cookie.服务端可以通过cookie储存会话id,这样多个请求之间就有了关联.同时服务端set cookie时指定cookie设置到哪儿域名及路径下,以及在客户端将驻留多久.
最后说一下JavaScript和Cookie的关系,JavaScript可以读写所在页面域名下的cookie值.
需要注意在http://www.a.com下面引入了http://www.b.com/b.js,b.js能读取所在页面,也就是www.a.com以及a.com下的cookie,而非b.com下的cookie.而b.js这个http的请求头中则带有b.com系列的cookie,这个请求的响应头中,也只能给b.com种植cookie.这里有点绕,但有必要澄清,可以遇到问题的时候可以再仔细看.
到此为止,我们了解了一个网页的构成要素,也了解了网页之间的联系,这样我们就了解了一个传统网站的前端技术体系.接下来我们介绍一些新花样,正是这些带来了Web2.0的前端变革.
六.DHTML:使用JavaScript操作Dom树
回到网页之内,其实我们只是获得了一颗DOM树,其他内容都驻留在树上.
接下来我们想一下,如果有一种手段能够随心所欲的改变动态这棵树,那岂不是我们就在客户端拥有了完全控制一个网页的能力.这项能力自然由JavaScript承担.
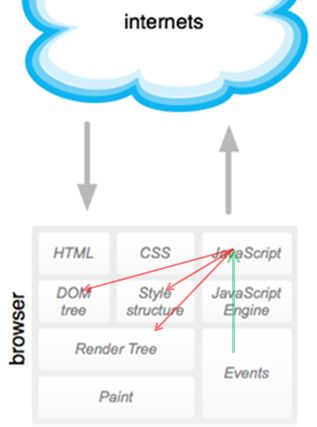
接下来设想一下,操作一个棵树,也就是一份结构化的XML文档我们需要怎样的API?
回忆一下,之前我们提到了JS的三个执行入口,很重要的一个是响应各种鼠标键盘事件,如何为节点绑定事件响应动作,IE有独特的事件模型.其余浏览器的事件模型符合W3C DOM接口定义.
这一系列技术被称为D(Dynamic)HTML,其核心是通过JS将Http,HTML,CSS,JavaScript更好的粘合在一起.通过JavaScript可以改变网页内的一切,甚至包括动态引入新的CSS和JS.
很酷是么?但单独DHTML并未流行起来,因为我们空有力量却不知道用到哪里合适.于是当接下来介绍的技术被引入,当我们能够根据服务端的指示来运用前台的力量,一场影响深远的真正的技术变革就此发生了.而在此之前,我们有必要意识到,DHTML不过是浏览器中JavaScript能力的一种扩展.
七.Ajax:使用JavaScript在网页内与服务器端交互
有了DHTML,JavaScript已经具有能力完全的改变所在网页的每个细节.JavaScript的野心不止于此,如果JS能由事件驱动,从服务器端源源不断的获取新鲜数据,那理论上不再需要第二个页面了.
我们再回忆下,网页上一切来自HTTP,获取数据自然需要JavaScript发起HTTP请求,并且可以读懂这个Http请求响应内容.于是有了XHR(XmlHttpRequest),首先作为一个ActiveX控件被IE5引入(这里必须要感谢IE对不对?).
XHR就是这样一个可以由JS发送Http请求,且当请求数据返回后将服务端数据交给JS的对象.而且XHR支持异步请求,在Http请求的过程中(因为是和服务端打交道,所以这个操作耗时可能较长),页面还可以正常工作,直到Http响应后会才触发一个事件回调JS方法处理数据.
如今Ajax并不单指XHR.所有在不离开当前页面的前提下,由JS主动发起的从服务器端获取JS可解析数据的方案,皆可称Ajax.
最常见的另一种Ajax实现方案是JSONP,JS通过DOM接口,创建一个<script>节点,指定节点的src为一个http地址到数据服务器,数据被包装成可执行的JS,在http响应结束后立即执行.(这里我们再一次涉及到了JS的执行入口之一,在浏览器遇到<script>节点是执行).
在MS,Google等先驱的引导之下,Ajax的出现引起了前端领域,乃至整个互联网开发领域的深刻变革,即为我们熟知的Web2.0.但回到本源,Ajax依然是浏览器中JavaScript能力的另一种扩展而已.
总结一下
- HTTP:一切内容通过HTTP请求获得
- HTML:浏览器把HTML解析成DOM树
- CSS:定义HTML的布局和样式
- JavaScript:提供计算能力,处理交互事件
- Cookie:网页间,请求间会话保持(JS可以操作Cookie)
- DHTML:JavaScript操作Dom树(包括CSS)
- AJAX:JavaScript操纵HTTP
前端技术体系的介绍可以告一段落,我们并没有把一个个概念的英文缩写展开,然后抄来晦涩的官方的解释.
"使用Http传输HTML文档,文档被解析成DOM树,CSS负责布局和样式,JS提供计算能力,处理事件响应,Cookie维持会话."
没错,如果换你来写一个浏览器,会不会也这样做?那么其他的客户端图形交互系统,是不是也一样要完成传输,展现,事件交互等等功能?
如果我继续介绍一下firebug这类前端开发工具,将其与七种武器对应上,再辅以一些API文档,就可以尝试体验下前端开发了.
最后和前端开发讲几句
读到这里的前端开发,先说声抱歉,写了这么长,通篇都是你烂熟于心的内容.而且你明明了解更多,这里却没有提到.
其实要点就在这里,如何在你所有知道的内容中提出来若干要点,完整的描述前端技术体系,这件事情对于前端开发而言,重要么?不重要么?重要么?不重要么?我们看几个问题:
为什么会有DHTML?
我们了解Http,HTML,CSS,JS的协作关系,知道DOM树是一切的依托,我们才会想到通过改变DOM树来操纵网页内的一切.
为什么会有Ajax?
我们了解DHTML的能力,却不知道其用武之地,后来我们想到依靠服务端指导.接下来我们又知道所有服务端内容都是通过Http获得,自然我们需要JavaScript能够操作的Http对象.
这些问题需要前端开发去发现,去解决.虽然大家都在跟着先贤们的步子走,很少能成为领域的开拓者,但是否了解整个前端技术体系的区别是你是否是在盲目跟风.区别是当一项新技术出现的时候是否能发现其解决的核心问题以及为解决问题付出的额外代价.
引入新技术的需要付出的额外代价是我要强调的另一个重点,使用DHTML的代价是什么,严重依赖Ajax的代价又是什么?了解这些然后我们才能更好的权衡要不要使用.
前端的发展依然在继续,遇到什么问题?如何解决?
解决问题付出什么代价?是否涵盖了所有常用浏览器,如果不能是否做到了渐进增强?我们要不要这样做?这些是做一名合格的前端,做一名对技术架构有影响力的前端,必然面对的问题.
前端技术体系,看起来题目很大,但其实并没有玄之又玄的东西在里边,所以即便我写的算不得优秀,但是说清楚还是可以的.我在面试高级前端的时候其实很在意前端大局观,不然叫我如何放心的把一个将会持续发展的产品交到他手里.