谈谈Oracle数据库的启动
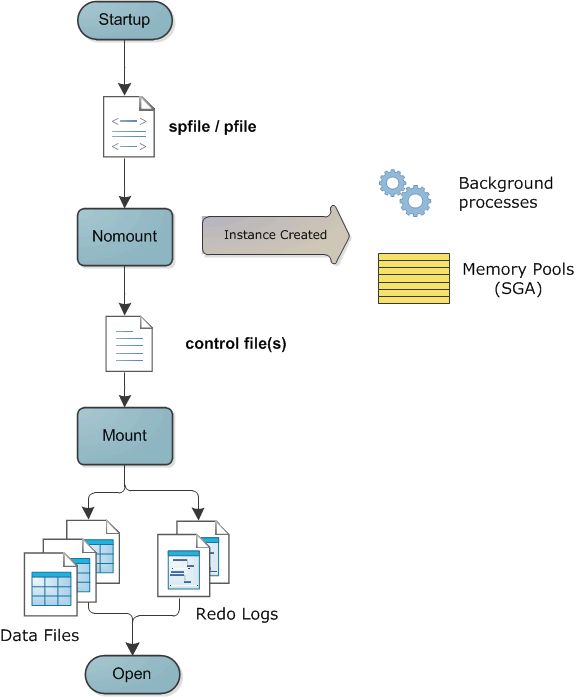
Oracle数据库启动过程实际包含三个阶段:
NOMOUNT -> MOUNT -> OPEN
一、启动数据库到NOMOUNT状态
NOMOUNT的过程就是启动Oracle数据库实例的过程。
在这个阶段Oracle首先会寻找参数文件(pfile或者spfile),然后根据参数文件中的设置,创建数据库实例(分配内存,创建后台进程)。
[oracle@mydb ~]$ sqlplus nolog
SQL*Plus: Release 11.2.0.4.0 Production on Sun Nov 9 05:00:30 2014
Copyright (c) 1982, 2013, Oracle. All rights reserved.
Enter password:
[oracle@mydb ~]$ sqlplus /nolog
SQL*Plus: Release 11.2.0.4.0 Production on Sun Nov 9 05:00:49 2014
Copyright (c) 1982, 2013, Oracle. All rights reserved.
SQL> conn / as sysdba
Connected to an idle instance.
SQL> startup nomount;
ORACLE instance started.
Total System Global Area 313860096 bytes
Fixed Size 1364340 bytes
Variable Size 155192972 bytes
Database Buffers 150994944 bytes
Redo Buffers 6307840 bytes
SQL> select status from v$instance;
STATUS
------------
STARTED
SQL>
SQL*Plus: Release 11.2.0.4.0 Production on Sun Nov 9 05:00:30 2014
Copyright (c) 1982, 2013, Oracle. All rights reserved.
Enter password:
[oracle@mydb ~]$ sqlplus /nolog
SQL*Plus: Release 11.2.0.4.0 Production on Sun Nov 9 05:00:49 2014
Copyright (c) 1982, 2013, Oracle. All rights reserved.
SQL> conn / as sysdba
Connected to an idle instance.
SQL> startup nomount;
ORACLE instance started.
Total System Global Area 313860096 bytes
Fixed Size 1364340 bytes
Variable Size 155192972 bytes
Database Buffers 150994944 bytes
Redo Buffers 6307840 bytes
SQL> select status from v$instance;
STATUS
------------
STARTED
SQL>
看下警告日志(Alert Log),我们看看Oracle在后台实际在做些什么动作。首先找到alert log所在的位置。
SQL> show parameter background_dump_dest
NAME TYPE VALUE
------------------------------------ ----------- ------------------------------
background_dump_dest string /u01/app/oracle/diag/rdbms/orcl/ORCL/trace
SQL>
NAME TYPE VALUE
------------------------------------ ----------- ------------------------------
background_dump_dest string /u01/app/oracle/diag/rdbms/orcl/ORCL/trace
SQL>
|
什么是警告日志(Alert Log)?
The alert log file (also referred to as the ALERT.LOG) is a chronological log of messages and errors written out by an Oracle Database. Typical messages found in this file is: database startup, shutdown, log switches, space errors, etc. This file should constantly be monitored to detect unexpected messages and corruptions.Oracle will automatically create a new alert log file whenever the old one is deleted. (Source:Link)
|
通过使用tail -f命令实时跟踪警告日志的变化。
[oracle@mydb trace]$ tail -f alert_ORCL.log
Sun Nov 09 05:22:34 2014
Starting ORACLE instance (normal)
************************ Large Pages Information *******************
Per process system memlock (soft) limit = 64 KB
Total Shared Global Region in Large Pages = 0 KB (0%)
Large Pages used by this instance: 0 (0 KB)
Large Pages unused system wide = 0 (0 KB)
Large Pages configured system wide = 0 (0 KB)
Large Page size = 2048 KB
RECOMMENDATION:
Total System Global Area size is 302 MB. For optimal performance,
prior to the next instance restart:
1. Increase the number of unused large pages by
at least 151 (page size 2048 KB, total size 302 MB) system wide to
get 100% of the System Global Area allocated with large pages
2. Large pages are automatically locked into physical memory.
Increase the per process memlock (soft) limit to at least 310 MB to lock
100% System Global Area's large pages into physical memory
********************************************************************
LICENSE_MAX_SESSION = 0
LICENSE_SESSIONS_WARNING = 0
Initial number of CPU is 1
CELL communication is configured to use 0 interface(s):
CELL IP affinity details:
NUMA status: non-NUMA system
cellaffinity.ora status: N/A
CELL communication will use 1 IP group(s):
Grp 0:
Picked latch-free SCN scheme 2
Using LOG_ARCHIVE_DEST_1 parameter default value as USE_DB_RECOVERY_FILE_DEST
Autotune of undo retention is turned on.
IMODE=BR
ILAT =27
LICENSE_MAX_USERS = 0
SYS auditing is disabled
Starting up:
Oracle Database 11g Enterprise Edition Release 11.2.0.4.0 - Production
With the Partitioning, OLAP, Data Mining and Real Application Testing options.
ORACLE_HOME = /u01/app/oracle/product/11.2.0/db_1
System name: Linux
Node name: mydb
Release: 2.6.39-400.17.1.el6uek.i686
Version: #1 SMP Fri Feb 22 18:17:46 PST 2013
Machine: i686
Using parameter settings in server-side pfile /u01/app/oracle/product/11.2.0/db_1/dbs/initORCL.ora
System parameters with non-default values:
processes = 150
sga_target = 300M
control_files = "/u01/oradata/control01.ctl"
db_block_size = 8192
compatible = "11.2.0.4.0"
db_create_file_dest = "/u01/oradata/"
db_recovery_file_dest = "/u01/app/oracle/fast_recovery_area"
db_recovery_file_dest_size= 4152M
undo_tablespace = "UNDOTBS1"
remote_login_passwordfile= "EXCLUSIVE"
db_domain = ""
dispatchers = "(PROTOCOL=TCP) (SERVICE=ORCLXDB)"
audit_file_dest = "/u01/app/oracle/admin/ORCL/adump"
audit_trail = "DB"
db_name = "ORCL"
open_cursors = 300
pga_aggregate_target = 100M
diagnostic_dest = "/u01/app/oracle"
Sun Nov 09 05:22:35 2014
PMON started with pid=2, OS id=1855
Sun Nov 09 05:22:35 2014
PSP0 started with pid=3, OS id=1857
Sun Nov 09 05:22:36 2014
VKTM started with pid=4, OS id=1859 at elevated priority
VKTM running at (1)millisec precision with DBRM quantum (100)ms
Sun Nov 09 05:22:36 2014
GEN0 started with pid=5, OS id=1863
Sun Nov 09 05:22:36 2014
DIAG started with pid=6, OS id=1865
Sun Nov 09 05:22:36 2014
DBRM started with pid=7, OS id=1867
Sun Nov 09 05:22:36 2014
DIA0 started with pid=8, OS id=1869
Sun Nov 09 05:22:36 2014
MMAN started with pid=9, OS id=1871
Sun Nov 09 05:22:36 2014
DBW0 started with pid=10, OS id=1873
Sun Nov 09 05:22:36 2014
LGWR started with pid=11, OS id=1875
Sun Nov 09 05:22:36 2014
CKPT started with pid=12, OS id=1877
Sun Nov 09 05:22:36 2014
SMON started with pid=13, OS id=1879
Sun Nov 09 05:22:36 2014
RECO started with pid=14, OS id=1881
Sun Nov 09 05:22:36 2014
MMON started with pid=15, OS id=1883
starting up 1 dispatcher(s) for network address '(ADDRESS=(PARTIAL=YES)(PROTOCOL=TCP))'...
Sun Nov 09 05:22:36 2014
MMNL started with pid=16, OS id=1885
starting up 1 shared server(s) ...
ORACLE_BASE from environment = /u01/app/oracle
Starting ORACLE instance (normal)
************************ Large Pages Information *******************
Per process system memlock (soft) limit = 64 KB
Total Shared Global Region in Large Pages = 0 KB (0%)
Large Pages used by this instance: 0 (0 KB)
Large Pages unused system wide = 0 (0 KB)
Large Pages configured system wide = 0 (0 KB)
Large Page size = 2048 KB
RECOMMENDATION:
Total System Global Area size is 302 MB. For optimal performance,
prior to the next instance restart:
1. Increase the number of unused large pages by
at least 151 (page size 2048 KB, total size 302 MB) system wide to
get 100% of the System Global Area allocated with large pages
2. Large pages are automatically locked into physical memory.
Increase the per process memlock (soft) limit to at least 310 MB to lock
100% System Global Area's large pages into physical memory
********************************************************************
LICENSE_MAX_SESSION = 0
LICENSE_SESSIONS_WARNING = 0
Initial number of CPU is 1
CELL communication is configured to use 0 interface(s):
CELL IP affinity details:
NUMA status: non-NUMA system
cellaffinity.ora status: N/A
CELL communication will use 1 IP group(s):
Grp 0:
Picked latch-free SCN scheme 2
Using LOG_ARCHIVE_DEST_1 parameter default value as USE_DB_RECOVERY_FILE_DEST
Autotune of undo retention is turned on.
IMODE=BR
ILAT =27
LICENSE_MAX_USERS = 0
SYS auditing is disabled
Starting up:
Oracle Database 11g Enterprise Edition Release 11.2.0.4.0 - Production
With the Partitioning, OLAP, Data Mining and Real Application Testing options.
ORACLE_HOME = /u01/app/oracle/product/11.2.0/db_1
System name: Linux
Node name: mydb
Release: 2.6.39-400.17.1.el6uek.i686
Version: #1 SMP Fri Feb 22 18:17:46 PST 2013
Machine: i686
Using parameter settings in server-side pfile /u01/app/oracle/product/11.2.0/db_1/dbs/initORCL.ora
System parameters with non-default values:
processes = 150
sga_target = 300M
control_files = "/u01/oradata/control01.ctl"
db_block_size = 8192
compatible = "11.2.0.4.0"
db_create_file_dest = "/u01/oradata/"
db_recovery_file_dest = "/u01/app/oracle/fast_recovery_area"
db_recovery_file_dest_size= 4152M
undo_tablespace = "UNDOTBS1"
remote_login_passwordfile= "EXCLUSIVE"
db_domain = ""
dispatchers = "(PROTOCOL=TCP) (SERVICE=ORCLXDB)"
audit_file_dest = "/u01/app/oracle/admin/ORCL/adump"
audit_trail = "DB"
db_name = "ORCL"
open_cursors = 300
pga_aggregate_target = 100M
diagnostic_dest = "/u01/app/oracle"
Sun Nov 09 05:22:35 2014
PMON started with pid=2, OS id=1855
Sun Nov 09 05:22:35 2014
PSP0 started with pid=3, OS id=1857
Sun Nov 09 05:22:36 2014
VKTM started with pid=4, OS id=1859 at elevated priority
VKTM running at (1)millisec precision with DBRM quantum (100)ms
Sun Nov 09 05:22:36 2014
GEN0 started with pid=5, OS id=1863
Sun Nov 09 05:22:36 2014
DIAG started with pid=6, OS id=1865
Sun Nov 09 05:22:36 2014
DBRM started with pid=7, OS id=1867
Sun Nov 09 05:22:36 2014
DIA0 started with pid=8, OS id=1869
Sun Nov 09 05:22:36 2014
MMAN started with pid=9, OS id=1871
Sun Nov 09 05:22:36 2014
DBW0 started with pid=10, OS id=1873
Sun Nov 09 05:22:36 2014
LGWR started with pid=11, OS id=1875
Sun Nov 09 05:22:36 2014
CKPT started with pid=12, OS id=1877
Sun Nov 09 05:22:36 2014
SMON started with pid=13, OS id=1879
Sun Nov 09 05:22:36 2014
RECO started with pid=14, OS id=1881
Sun Nov 09 05:22:36 2014
MMON started with pid=15, OS id=1883
starting up 1 dispatcher(s) for network address '(ADDRESS=(PARTIAL=YES)(PROTOCOL=TCP))'...
Sun Nov 09 05:22:36 2014
MMNL started with pid=16, OS id=1885
starting up 1 shared server(s) ...
ORACLE_BASE from environment = /u01/app/oracle
从上边的日志信息,我们能看出什么,
1、Oracle 实例是由一组内存和一组后台进程组成的,内存以及进程的参数都写在参数文件中,NOMOUNT阶段读取这些参数值,构造数据库实例环境。
sga_target = 300M
pga_aggregate_target = 100M
2、后台进程是按照一定顺序一个一个启动的,PMON首先启动。
PMON started with pid=2, OS id=1855
...
DBW0 started with pid=10, OS id=1873
...
LGWR started with pid=11, OS id=1875
...
CKPT started with pid=12, OS id=1877
...
SMON started with pid=13, OS id=1879
...
DBW0 started with pid=10, OS id=1873
...
LGWR started with pid=11, OS id=1875
...
CKPT started with pid=12, OS id=1877
...
SMON started with pid=13, OS id=1879
| pid表示该进程在数据库内部的标示编号;OS id表示该进程在操作系统上的进程编号。 |
问题来了,启动到NOMOUNT阶段,Oracle是从哪里读取参数文件来构造Oracle实例的?
因为NOMOUNT是第一个阶段,数据库还没有启动,所以肯定不是从数据库里边读取的,应该是某一个本地文件读取参数的。这就是SPFILE或者PFILE。Oracle首选spfile<sid>.ora文件作为启动参数文件;如果该文件不存在,oracle会选择spfile.ora文件;如果前两者都不存在,Oracle将会选择init<sid>.ora文件。如果这三个文件都不存在,Oracle将无法创建instance。在上边的日志中,有这么一条:
Using parameter settings in server-side pfile /u01/app/oracle/product/11.2.0/db_1/dbs/initORCL.ora
说明了Oracle启动时,没有找到前两样SPFILE,最终读取的是PFILE参数文件:initORCL.ora
启动到NOMOUNT可以查询哪些动态视图?
只有这三个动态视图:V$PARAMETER, V$SESSION, V$INSTANCE,这些动态视图信息已经随着参数文件加载到SGA内存中了。
V$DATABASE, V$DATAFILE ,V$LOGFILE是从Control file读取的,所以必须等数据库启动到MOUNT下,这几个动态视图才可以访问。
而数据字典只有等数据库切换到OPEN状态,才可以访问。
二、启动数据库到MOUNT状态
在上边启动到NOMOUNT阶段的日志中,可以看到一条:
control_files = "/u01/oradata/control01.ctl"
启动到NOMOUNT状态后,Oracle就可以从SPFILE或PFILE中获取了Control File的位置信息,找到控制文件,并读取控制文件。那么控制文件记录了什么呢?控制文件是二进制文件,记录了以下信息:
- Database name
- Timestamp of database creation
- Names and locations of Data Files
- Names and locations of Redo Log files
- The current log sequence number
- Checkpoint information
- Recent RMAN backups taken
- Etc.
注意,在MOUNT阶段,虽然已经可以通过控制文件找到数据文件以及日志文件,但在此阶段,并没有打开他们。
从NOMOUNT到MOUNT:
SQL> alter database mount;
Database altered.
SQL> select status from v$instance;
STATUS
------------
MOUNTED
Database altered.
SQL> select status from v$instance;
STATUS
------------
MOUNTED
Alert Log:
Sun Nov 09 06:25:28 2014
alter database mount
Sun Nov 09 06:25:32 2014
Successful mount of redo thread 1, with mount id 1390902744
Database mounted in Exclusive Mode
Lost write protection disabled
Completed: alter database mount
alter database mount
Sun Nov 09 06:25:32 2014
Successful mount of redo thread 1, with mount id 1390902744
Database mounted in Exclusive Mode
Lost write protection disabled
Completed: alter database mount
MOUNT数据库之后,后台进程就可以根据控制文件中记录的数据文件信息来验证数据文件是否存在了。
SQL> select name from v$datafile;
NAME
----------------------------------------------
/u01/oradata/system01.dbf
/u01/oradata/sysaux01.dbf
/u01/oradata/undotbs01.dbf
/u01/oradata/users01.dbf
/u01/oradata/example01.dbf
/u01/oradata/test_tbs01.dbf
6 rows selected.
NAME
----------------------------------------------
/u01/oradata/system01.dbf
/u01/oradata/sysaux01.dbf
/u01/oradata/undotbs01.dbf
/u01/oradata/users01.dbf
/u01/oradata/example01.dbf
/u01/oradata/test_tbs01.dbf
6 rows selected.
三、启动数据库到OPEN状态
在这个阶段,首先会对每个数据文件做一检查,检查数据文件头中的检查点计数(Checkpoint CNT)是否和控制文件中的检查点计数一致,然后再打开数据库,锁定数据文件。
从MOUNT到OPEN:
SQL> alter database open;
Database altered.
SQL> select status from v$instance;
STATUS
------------
OPEN
Database altered.
SQL> select status from v$instance;
STATUS
------------
OPEN
此阶段完整的Alert Log:
Sun Nov 09 06:28:33 2014
alter database open
Beginning crash recovery of 1 threads
Started redo scan
Completed redo scan
read 132 KB redo, 47 data blocks need recovery
Started redo application at
Thread 1: logseq 3, block 18925
Recovery of Online Redo Log: Thread 1 Group 3 Seq 3 Reading mem 0
Mem# 0: /u01/oradata/redo03.log
Mem# 1: /u01/oradata/redo03_2.log
Completed redo application of 0.04MB
Completed crash recovery at
Thread 1: logseq 3, block 19190, scn 1146502
47 data blocks read, 47 data blocks written, 132 redo k-bytes read
Sun Nov 09 06:28:34 2014
LGWR: STARTING ARCH PROCESSES
Sun Nov 09 06:28:34 2014
ARC0 started with pid=20, OS id=2279
ARC0: Archival started
LGWR: STARTING ARCH PROCESSES COMPLETE
ARC0: STARTING ARCH PROCESSES
Sun Nov 09 06:28:35 2014
ARC1 started with pid=21, OS id=2281
Sun Nov 09 06:28:35 2014
ARC2 started with pid=22, OS id=2283
ARC1: Archival started
ARC2: Archival started
ARC1: Becoming the 'no FAL' ARCH
ARC1: Becoming the 'no SRL' ARCH
ARC2: Becoming the heartbeat ARCH
Sun Nov 09 06:28:35 2014
ARC3 started with pid=23, OS id=2285
Thread 1 advanced to log sequence 4 (thread open)
Thread 1 opened at log sequence 4
Current log# 4 seq# 4 mem# 0: /u01/oradata/redo04.log
Current log# 4 seq# 4 mem# 1: /u01/oradata/redo04_2.log
Successful open of redo thread 1
MTTR advisory is disabled because FAST_START_MTTR_TARGET is not set
Sun Nov 09 06:28:35 2014
SMON: enabling cache recovery
ARC3: Archival started
ARC0: STARTING ARCH PROCESSES COMPLETE
Archived Log entry 28 added for thread 1 sequence 3 ID 0x52e6dc5b dest 1:
[1890] Successfully onlined Undo Tablespace 2.
Undo initialization finished serial:0 start:4464354 end:4464934 diff:580 (5 seconds)
Verifying file header compatibility for 11g tablespace encryption..
Verifying 11g file header compatibility for tablespace encryption completed
SMON: enabling tx recovery
Cannot re-create tempfile /u01/app/oracle/oradata/ORCL/temp01.dbf, the same name file exists
Sun Nov 09 06:28:37 2014
Errors in file /u01/app/oracle/diag/rdbms/orcl/ORCL/trace/ORCL_dbw0_1873.trc:
ORA-01157: cannot identify/lock data file 201 - see DBWR trace file
ORA-01110: data file 201: '/u01/app/oracle/oradata/ORCL/temp01.dbf'
ORA-27037: unable to obtain file status
Linux Error: 2: No such file or directory
Additional information: 3
Database Characterset is AL32UTF8
No Resource Manager plan active
replication_dependency_tracking turned off (no async multimaster replication found)
Starting background process QMNC
Sun Nov 09 06:28:40 2014
QMNC started with pid=24, OS id=2287
Sun Nov 09 06:28:46 2014
Completed: alter database open
Sun Nov 09 06:28:46 2014
Starting background process CJQ0
Sun Nov 09 06:28:46 2014
CJQ0 started with pid=29, OS id=2303
Sun Nov 09 06:28:46 2014
db_recovery_file_dest_size of 4152 MB is 1.44% used. This is a
user-specified limit on the amount of space that will be used by this
database for recovery-related files, and does not reflect the amount of
space available in the underlying filesystem or ASM diskgroup.
Sun Nov 09 06:28:47 2014
Errors in file /u01/app/oracle/diag/rdbms/orcl/ORCL/trace/ORCL_m001_2301.trc:
ORA-01157: cannot identify/lock data file 201 - see DBWR trace file
ORA-01110: data file 201: '/u01/app/oracle/oradata/ORCL/temp01.dbf'
Setting Resource Manager plan SCHEDULER[0x32DF]:DEFAULT_MAINTENANCE_PLAN via scheduler window
Setting Resource Manager plan DEFAULT_MAINTENANCE_PLAN via parameter
Sun Nov 09 06:28:49 2014
Starting background process VKRM
Sun Nov 09 06:28:49 2014
VKRM started with pid=25, OS id=2305
alter database open
Beginning crash recovery of 1 threads
Started redo scan
Completed redo scan
read 132 KB redo, 47 data blocks need recovery
Started redo application at
Thread 1: logseq 3, block 18925
Recovery of Online Redo Log: Thread 1 Group 3 Seq 3 Reading mem 0
Mem# 0: /u01/oradata/redo03.log
Mem# 1: /u01/oradata/redo03_2.log
Completed redo application of 0.04MB
Completed crash recovery at
Thread 1: logseq 3, block 19190, scn 1146502
47 data blocks read, 47 data blocks written, 132 redo k-bytes read
Sun Nov 09 06:28:34 2014
LGWR: STARTING ARCH PROCESSES
Sun Nov 09 06:28:34 2014
ARC0 started with pid=20, OS id=2279
ARC0: Archival started
LGWR: STARTING ARCH PROCESSES COMPLETE
ARC0: STARTING ARCH PROCESSES
Sun Nov 09 06:28:35 2014
ARC1 started with pid=21, OS id=2281
Sun Nov 09 06:28:35 2014
ARC2 started with pid=22, OS id=2283
ARC1: Archival started
ARC2: Archival started
ARC1: Becoming the 'no FAL' ARCH
ARC1: Becoming the 'no SRL' ARCH
ARC2: Becoming the heartbeat ARCH
Sun Nov 09 06:28:35 2014
ARC3 started with pid=23, OS id=2285
Thread 1 advanced to log sequence 4 (thread open)
Thread 1 opened at log sequence 4
Current log# 4 seq# 4 mem# 0: /u01/oradata/redo04.log
Current log# 4 seq# 4 mem# 1: /u01/oradata/redo04_2.log
Successful open of redo thread 1
MTTR advisory is disabled because FAST_START_MTTR_TARGET is not set
Sun Nov 09 06:28:35 2014
SMON: enabling cache recovery
ARC3: Archival started
ARC0: STARTING ARCH PROCESSES COMPLETE
Archived Log entry 28 added for thread 1 sequence 3 ID 0x52e6dc5b dest 1:
[1890] Successfully onlined Undo Tablespace 2.
Undo initialization finished serial:0 start:4464354 end:4464934 diff:580 (5 seconds)
Verifying file header compatibility for 11g tablespace encryption..
Verifying 11g file header compatibility for tablespace encryption completed
SMON: enabling tx recovery
Cannot re-create tempfile /u01/app/oracle/oradata/ORCL/temp01.dbf, the same name file exists
Sun Nov 09 06:28:37 2014
Errors in file /u01/app/oracle/diag/rdbms/orcl/ORCL/trace/ORCL_dbw0_1873.trc:
ORA-01157: cannot identify/lock data file 201 - see DBWR trace file
ORA-01110: data file 201: '/u01/app/oracle/oradata/ORCL/temp01.dbf'
ORA-27037: unable to obtain file status
Linux Error: 2: No such file or directory
Additional information: 3
Database Characterset is AL32UTF8
No Resource Manager plan active
replication_dependency_tracking turned off (no async multimaster replication found)
Starting background process QMNC
Sun Nov 09 06:28:40 2014
QMNC started with pid=24, OS id=2287
Sun Nov 09 06:28:46 2014
Completed: alter database open
Sun Nov 09 06:28:46 2014
Starting background process CJQ0
Sun Nov 09 06:28:46 2014
CJQ0 started with pid=29, OS id=2303
Sun Nov 09 06:28:46 2014
db_recovery_file_dest_size of 4152 MB is 1.44% used. This is a
user-specified limit on the amount of space that will be used by this
database for recovery-related files, and does not reflect the amount of
space available in the underlying filesystem or ASM diskgroup.
Sun Nov 09 06:28:47 2014
Errors in file /u01/app/oracle/diag/rdbms/orcl/ORCL/trace/ORCL_m001_2301.trc:
ORA-01157: cannot identify/lock data file 201 - see DBWR trace file
ORA-01110: data file 201: '/u01/app/oracle/oradata/ORCL/temp01.dbf'
Setting Resource Manager plan SCHEDULER[0x32DF]:DEFAULT_MAINTENANCE_PLAN via scheduler window
Setting Resource Manager plan DEFAULT_MAINTENANCE_PLAN via parameter
Sun Nov 09 06:28:49 2014
Starting background process VKRM
Sun Nov 09 06:28:49 2014
VKRM started with pid=25, OS id=2305
关于数据库的关闭,可以见另外一篇文章: 谈谈Oracle数据库的关闭