搜狗2012.9.23校园招聘会笔试题
zz from http://blog.csdn.net/hackbuteer1/article/details/8016173
http://www.cnblogs.com/jmp0xf/archive/2013/05/13/Sougou_2013_Research_Paper_Test_V_Research_Questions.html
C/C++类
1、以下程序的输出是(12)
- class Base
- {
- public:
- Base(int j) : i(j) { }
- virtual ~Base() { }
- void func1()
- {
- i *= 10;
- func2();
- }
- int getValue()
- {
- return i;
- }
- protected:
- virtual void func2()
- {
- i++;
- }
- protected:
- int i;
- };
- class Child : public Base
- {
- public:
- Child(int j) : Base(j) { }
- void func1()
- {
- i *= 100;
- func2();
- }
- protected:
- void func2()
- {
- i += 2;
- }
- };
- int main(void)
- {
- Base *pb = new Child(1);
- pb->func1();
- cout<<pb->getValue()<<endl;
- delete pb;
- return 0;
- }
#define DOUBLE(x) x+x // x*2
int i = DOUBLE(5)*5;
cout<<i<<endl;
3、写出一下程序的输出(死循环)
- int main(void)
- {
- char num;
- for(num = 0; num < 255; )
- num += num;
- printf("%d\n",num);
- return 0;
- }
- int main(void)
- {
- http://www.sogou.com
- cout<<"welcome to sogou"<<endl;
- return 0;
- }
因为http://www.sogou.com中//后面是注释,前面的http:是标签(类似于goto语句中的标签)。(这个题目碉堡了)
5、下面程序执行结果为【说明:X86_64环境】(D)
- int main(void)
- {
- int a[4][4] = {
- {1,2,3,4},
- {50,60,70,80},
- {900,1000,1100,1200},
- {13000,14000,15000,16000} };
- int (*p1)[4] = a;
- int (*p2)[4] = &a[0];
- int *p3 = &a[0][0];
- printf("%d %d %d %d\n",*(*(a+1)-1),*(*(p1+3)-2)+1,*(*(p2-1)+16)+2,*(p3+sizeof(p1)-3));
- return 0;
- }
B、4 2 3 60
C、16000 2 3 2
D、4 1101 13002 60
p1为指向一维数组的指针,所以a + 1指向{50,60,70,80}这一维的地址。减一则为4的地址;同理第二个输出1101。同理,由于数组的列是4,所以*(p2 - 1) + 16就相当于*(p2) + 12,所以第三个输出13002。
第四个由于p1是指针,所以sizeof(p1)为8(68位的系统),所以第四个输出60。
6、在32位操作系统gcc编译器环境下,下面的程序的运行结果是(A)
- class A
- {
- public:
- int b;
- char c;
- virtual void print()
- {
- cout<<"this is father's function!"<<endl;
- }
- };
- class B : A
- {
- public:
- virtual void print()
- {
- cout<<"this is children's function!"<<endl;
- }
- };
- int main(void)
- {
- cout<<sizeof(A)<<" "<<sizeof(A)<<endl;
- return 0;
- }
B、8 8
C、9 9
D、12 16
7、以下哪些做法是不正确或者应该极力避免的:【多选】(ACD)
A、构造函数声明为虚函数
B、派生关系中的基类析构函数声明为虚函数
C、构造函数调用虚函数
D、析构函数调用虚函数
8、关于C++标准模板库,下列说法错误的有哪些:【多选】(AD)
A、std::auto_ptr<Class A>类型的对象,可以放到std::vector<std::auto_ptr<Class A>>容器中
B、std::shared_ptr<Class A>类型的对象,可以放到std::vector<std::shared_ptr<Class A>>容器中
C、对于复杂类型T的对象tObj,++tObj和tObj++的执行效率相比,前者更高
D、采用new操作符创建对象时,如果没有足够内存空间而导致创建失败,则new操作符会返回NULL
A中auto是给别人东西而自己没有了。所以不符合vector的要求。而B可以。C不解释。new在失败后抛出标准异常std::bad_alloc而不是返回NULL。
9、有如下几个类和函数定义,选项中描述正确的是:【多选】(B)
- class A
- {
- public:
- virtual void foo() { }
- };
- class B
- {
- public:
- virtual void foo() { }
- };
- class C : public A , public B
- {
- public:
- virtual void foo() { }
- };
- void bar1(A *pa)
- {
- B *pc = dynamic_cast<B*>(pa);
- }
- void bar2(A *pa)
- {
- B *pc = static_cast<B*>(pa);
- }
- void bar3()
- {
- C c;
- A *pa = &c;
- B *pb = static_cast<B*>(static_cast<C*>(pa));
- }
B、bar2无法通过编译
C、bar3无法通过编译
D、bar1可以正常运行,但是采用了错误的cast方法
选B。dynamic_cast是在运行时遍历继承树,所以,在编译时不会报错。但是因为A和B没啥关系,所以运行时报错(所以A和D都是错误的)。static_cast:编译器隐式执行的任何类型转换都可由它显示完成。其中对于:(1)基本类型。如可以将int转换为double(编译器会执行隐式转换),但是不能将int*用它转换到double*(没有此隐式转换)。(2)对于用户自定义类型,如果两个类无关,则会出错(所以B正确),如果存在继承关系,则可以在基类和派生类之间进行任何转型,在编译期间不会出错。所以bar3可以通过编译(C选项是错误的)。
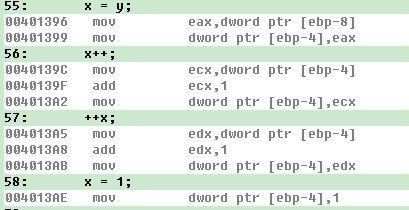
10、在Intel CPU上,以下多线程对int型变量x的操作,哪几个不是原子操作,假定变量的地址都是对齐的。【多选】(ABC)
A、x = y B、x++ C、++x D、x = 1
看下在VC++6.0下的汇编命令即可:从图可以看出本题只有D选项才是原子操作。
11、一般情况下,下面哪些操作会执行失败?【多选】(BCD)
- class A
- {
- public:
- string a;
- void f1()
- {
- printf("Hello World");
- }
- void f2()
- {
- a = "Hello World";
- printf("%s",a.c_str());
- }
- virtual void f3()
- {
- printf("Hello World");
- }
- virtual void f4()
- {
- a = "Hello World";
- printf("%s",a.c_str());
- }
- };
B、A *aptr = NULL; aptr->f2();
C、A *aptr = NULL; aptr->f3();
D、A *aptr = NULL; aptr->f4();
至于A为什么正确,因为A没有使用任何成员变量,而成员函数是不属于对象的,所以A正确。其实,A* aptr = NULL;aptr->f5();也是正确的,因为静态成员也是不属于任何对象的。至于BCD,在B中使用了成员变量,而成员变量只能存在于对象,C有虚表指针,所以也只存在于对象中。D就更是一样了。但是,如果在Class A中没有写public,那么就全都是private,以至于所有的选项都将会失败。
12、C++下,下面哪些template实例化使用,会引起编译错误?【多选】(CEF)
- template<class Type> class stack;
- void fi(stack<char>); //A
- class Ex
- {
- stack<double> &rs; //B
- stack<int> si; //C
- };
- int main(void)
- {
- stack<char> *sc; //D
- fi(*sc); //E
- int i = sizeof(stack<string>); //F
- return 0;
- }
由于stack只是声明,所以C是错误的,stack不能定义对象。E也是一样,stack只是申明,所以不能执行拷贝构造函数,至于F,由于stack只是声明,不知道stack的大小,所以错误。如果stack定义了,将全是正确的。
13、以下哪个说法正确()
- int func()
- {
- char b[2]={0};
- strcpy(b,"aaa");
- }
B、Debug版正常,Release版崩溃
C、Debug版崩溃,Release版崩溃
D、Debug版正常,Release版正常
选A。因为在Debug中有ASSERT断言保护,所以要崩溃,而在Release中就会删掉ASSERT,所以会出现正常运行。但是不推荐如此做,因为这样会覆盖不属于自己的内存,这是搭上了程序崩溃的列车。
数据结构类
37、每份考卷都有一个8位二进制序列号,当且仅当一个序列号含有偶数个1时,它才是有效的。例如:00000000 01010011 都是有效的序列号,而11111110不是,那么有效的序列号共有(128)个。
38、对初始状态为递增序列的数组按递增顺序排序,最省时间的是插入排序算法,最费时间的算法(B)
A、堆排序 B、快速排序 C、插入排序 D、归并排序
39、下图为一个二叉树,请选出以下不是遍历二叉树产生的顺序序列的选项【多选】(BD)
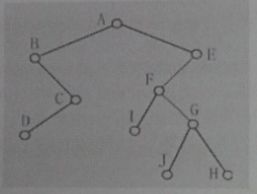
A、ABCDEFIGJH
B、BDCAIJGHFE
C、BDCAIFJGHE
D、DCBJHGIFEA
40、在有序双向链表中定位删除一个元素的平均时间复杂度为()
A、O(1) B、O(N) C、O(logN) D、O(N*logN)
41、将10阶对称矩阵压缩存储到一维数组A中,则数组A的长度最少为()
A、100 B、40 C、55 D、80
42、将数组a[]作为循环队列SQ的存储空间,f为队头指示,r为队尾指示,则执行出队操作的语句为(B)
A、f = f+1 B、f = (f+1)%m C、r = (r+1)%m D、f = (f+1)%(m+1)
43、以下哪种操作最适合先进行排序处理?
A、找最大、最小值 B、计算算出平均值 C、找中间值 D、找出现次数最多的值
44、设有一个二维数组A[m][n],假设A[0][0]存放位置在644(10),A[2][2]存放位置在676(10),每个元元素占一个空间,问A[3][3]存放在什么位置?(C)脚注(10)表示用10进制表示
A、688 B、678 C、692 D、696
45、使用下列二维图形变换矩阵A=T*a,将产生的变换结果为(D)
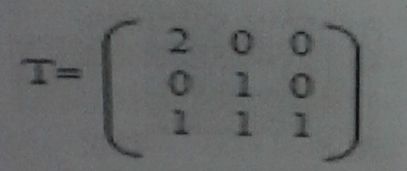
A、图形放大2倍
B、图形放大2倍,同时沿X、Y坐标轴方向各移动一个单位
C、沿X坐标轴方向各移动2个单位
D、沿X坐标轴放大2倍,同时沿X、Y坐标轴方向各移动一个单位
46、体育课的铃声响了,同学们都陆续地奔向操场,按老师 的要求从高到矮站成一排。每个同学按顺序来到操场时,都从排尾走向排头,找到第一个比自己高的同学,并站到他的后面,这种站队的方法类似于()算法。
A、快速排序 B、插入排序 C、冒泡排序 D、归并排序
47、处理a.html文件时,以下哪行伪代码可能导致内存越界或者抛出异常(B)
int totalBlank = 0;
int blankNum = 0;
int taglen = page.taglst.size();
A for(int i = 1; i < taglen-1; ++i)
{
//check blank
B while(page.taglst[i] == "<br>" && i < taglen)
{
C ++totalBlank;
D ++i;
}
E if(totalBlank > 10)
F blankNum += totalBlank;
G totalBlank = 0;
}
注意:以下代码中taglen是html文件中存在元素的个数,a.html中taglen的值是15,page.taglst[i]取的是a.html中的元素,例如page.taglst[1]的值是<html>
a.html 的文件如下:
<html>
<title>test</title>
<body>
<div>aaaaaaa</div>
</body>
</html>
<br>
<br>
<br>
<br>
<br>
48、对一个有向图而言,如果每个节点都存在到达其他任何节点的路径,那么就称它是强连通的。例如,右图就是一个强连通图,事实上,在删掉哪几条边后,它依然是强连通的。(A)
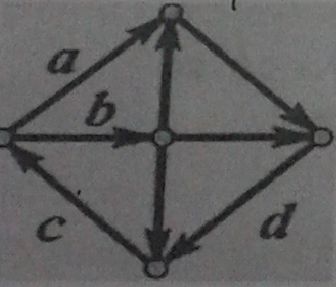
A、a B、b C、c D、d
100、一种计算机,其有如下原子功能:
1、赋值 a=b
2、+1操作,++a; a+1;
3、循环,但是只支持按次数的循环 for(变量名){/*循环里面对变量的修改不影响循环次数*/}
4、只能处理0和正整数
5、函数调用 fun(参数列表)
请用伪代码的形式分别在这个计算机上编程实现变量的加法、减法、乘法。
fun_add(a , b)
{
}
fun_multi(a , b)
{
}
fun_minus(a , b)
{
}
问题的关键在于如何实现自减一操作。
本来让-1自增n次即可实现n的自减的,但系统偏偏又不支持负数。
- fun_add(a , b)
- {
- result = a;
- for(b)
- ++result;
- return result;
- }
- fun_muti(a , b)
- {
- result = 0;
- for(b)
- result = fun_add(result , a);
- return result;
- }
- dec(int n)
- {
- temp = 0;
- result = 0;
- for(n)
- {
- result = temp; //result永远比temp少1,巧妙地减少了一次自增
- ++temp;
- }
- return result;
- }
- /*
- 上面的dec这段函数代码执行后,result的值将变为n-1。注意到这段代码在自增时是如何巧妙地延迟了一步的。
- 现在,我们相当于有了自减一的函数dec。实现a-b只需要令a自减b次即可
- */
- fun_minus(a , b)
- {
- result = a;
- for(b)
- result = dec(result);
- }
101、实现一个队链表排序的算法,C/C++可以使用std::list<int>,Java使用LinkedList<Integer>
要求先描述算法,然后再实现,算法效率尽可能高效。
主要考察链表的归并排序。
要点:需要使用快、慢指针的方法,找到链表的的中间节点,然后进行二路归并排序
- typedef struct LNode
- {
- int data;
- struct LNode *next;
- }LNode , *LinkList;
- // 对两个有序的链表进行递归的归并
- LinkList MergeList_recursive(LinkList head1 , LinkList head2)
- {
- LinkList result;
- if(head1 == NULL)
- return head2;
- if(head2 == NULL)
- return head1;
- if(head1->data < head2->data)
- {
- result = head1;
- result->next = MergeList_recursive(head1->next , head2);
- }
- else
- {
- result = head2;
- result->next = MergeList_recursive(head1 , head2->next);
- }
- return result;
- }
- // 对两个有序的链表进行非递归的归并
- LinkList MergeList(LinkList head1 , LinkList head2)
- {
- LinkList head , result = NULL;
- if(head1 == NULL)
- return head2;
- if(head2 == NULL)
- return head1;
- while(head1 && head2)
- {
- if(head1->data < head2->data)
- {
- if(result == NULL)
- {
- head = result = head1;
- head1 = head1->next;
- }
- else
- {
- result->next = head1;
- result = head1;
- head1 = head1->next;
- }
- }
- else
- {
- if(result == NULL)
- {
- head = result = head2;
- head2 = head2->next;
- }
- else
- {
- result->next = head2;
- result = head2;
- head2 = head2->next;
- }
- }
- }
- if(head1)
- result->next = head1;
- if(head2)
- result->next = head2;
- return head;
- }
- // 归并排序,参数为要排序的链表的头结点,函数返回值为排序后的链表的头结点
- LinkList MergeSort(LinkList head)
- {
- if(head == NULL)
- return NULL;
- LinkList r_head , slow , fast;
- r_head = slow = fast = head;
- // 找链表中间节点的两种方法
- /*
- while(fast->next != NULL)
- {
- if(fast->next->next != NULL)
- {
- slow = slow->next;
- fast = fast->next->next;
- }
- else
- fast = fast->next;
- }*/
- while(fast->next != NULL && fast->next->next != NULL)
- {
- slow = slow->next;
- fast = fast->next->next;
- }
- if(slow->next == NULL) // 链表中只有一个节点
- return r_head;
- fast = slow->next;
- slow->next = NULL;
- slow = head;
- // 函数MergeList是对两个有序链表进行归并,返回值是归并后的链表的头结点
- //r_head = MergeList_recursive(MergeSort(slow) , MergeSort(fast));
- r_head = MergeList(MergeSort(slow) , MergeSort(fast));
- return r_head;
- }
V.Research类
49. 两艘船在同一时刻驶离河的两岸,一艘船从A驶往B,另一艘船从B驶往A,其中一艘开的比另一艘快些,因此他们在距离较近的岸5公里处相遇,到达预定地点后,每艘船要停留15分钟。以便乘客上下船,然后他们又返航,这两艘船在距另一岸1公里处重新相遇,请问河宽_14_公里。
解:
首先要确认的是“每艘船要停留15分钟”只是干扰项,可以直接忽略。
设从A开出的船快一些,河宽为 d
第一次相遇时AB共走一个河宽,设耗时为 t
A -------------------------------><~~~~5~~~~ B
第二次相遇时AB共走两个河宽,则耗时 2t
A ~~~~~~~~~d-5~~~~~~~~<>-------------- B
A ~1~><----------------------------------------- B
由上图易知
(d−5)+12t=5t
则 d=14
50. 下列哪个不属于常用的文本分类的特征选择算法? ( D )
A.卡方检验值 B.互信息 C.信息增益 D.主成分分析
51. N-Gram语言模型可用于查询分类。实际能获取到的查询分类训练数据往往带有一定噪音。以下四种模型和训练数据的选择中,哪种能达到最好的实际使用效果?
( C )
A.二元和三元模型,正负例查询词各2,000,精度100%
B.四元模型,正负例查询词各10,000,精度85%
C.一元和二元模型,正负例查询词各20,000,精度80%
D.二元模型,正负例查询词各5,000,精度95%
解:
首先可以排除A、B, 虽然常用的是一元和二元模型,但也不是说三四元不可用,而是AB中给出的数据集相对来说实在是太小了。
D不如C是因为5000*95%<20000*80%
52. 语言模型的参数估计经常使用MLE(最大似然估计)。面临的—个问题是没有出现的项概率为0,这样会导致语言模型的效果不好。为了解决这个问题,需要使用:
( A )
A.平滑 B.去噪 C.随机插值 D.增加白噪音
平滑估计公式:
P(e)=Ne+fe∑e′∈E(Ne′+fe′)简单平滑: fe=常数
Expected likelihood estimation (ELE): fe=0.5
拉普拉斯平滑 Laplace smoothing: fe=1
Add-tiny smoothing: fe=1/∑e′∈ENe′
Good-Turing平滑
53. 所有人口中,某癌症的患病率为0.008。对有癌症的病人,医院的化验测试有2%的可能错判其无癌症。对无癌症的病人,有3%的可能错判其有癌症。问:现有一新病人,化验测试表明其有癌症,该病人实际患有癌症的概率是多少?(计算过程四舍五入保留4位小数) ( C )
A.0.0078 B.00298 C.0.2074 D.0.98
解:
由题知, P(cancer)=0.008 , P(positive¯¯¯¯¯¯¯¯¯¯¯|cancer)=0.02 , P(positive|cancer¯¯¯¯¯¯¯¯¯¯)=0.03
P(cancer|positive)=P(positive|cancer)P(cancer)P(positive|cancer)P(cancer)+P(positive|cancer¯¯¯¯¯¯¯¯¯¯)P(cancer¯¯¯¯¯¯¯¯¯¯)=11+P(positive|cancer¯¯¯¯¯¯¯¯¯¯)(1−P(cancer))(1−P(positive¯¯¯¯¯¯¯¯¯¯¯|cancer))P(cancer)≈11+0.02980.0078=1/4.821≈0.2074
54. 在大规模的语料中,挖掘词的相关性是一个重要的问题。以下哪一个信息不能用于确定两个词的相关性。( B )
A.互信息 B.最大熵 C.卡方检验 D.最大似然比
55. 下列哪个不属于CRF模型对于HMM和MEMM模型的优势 ( B )
A.特征灵活 B.速度快 C.可容纳较多上下文信息 D.全局最优
56. 下列不是SVM核函数的是:( B )
A.多项式核函数 B.logistic核函数 C.径向基核函数 D.Sigmoid核函数
57. 下列属于无监督学习的是:( A )
A.K-means B.SVM C.最大熵 D.CRF
58. 以下哪些方法不可以直接来对文本分类 ( A )
A.K-means B.决策树 C.支持向量机 D.KNN
59. 解决隐马模型中预测问题的算法是 ( D )
A.前向算法 B.后向算法 C.Baum-Welch算法 D.维特比算法
60. 一个有偏的硬币,抛了100次,出现1次人头,99次字。问用最大似然估计(ML)和最小均方误差(LSE)估计出现人头的概率哪个大 ( C )
A.ML=MSE B.ML>MSE C.ML<MSE
解一:
P(H)MLE=argmaxθ^θ^(1−θ^)99令 ddθ^(1−θ^)99=(θ^−1)98(1−100θ^)=0
则 P(H)MLE=1100
假设真实值 P(H)=θ
那么 P(H)MMSE=argminθ^ ∫10(θ^−θ)2p(θ|D)dθ
又 P(θ|D)∼P(D|θ)P(θ) 而在没有其他信息的情况下,先验地认为 P(θ) 均匀分布
于是P(H)MMSE=argminθ^ ∫10(θ^−θ)2p(D|θ)dθ
=argminθ^ ∫10(θ^−θ)2θ(1−θ)99dθ
令 x=1−θ , P(H)MMSE=argminθ^ ∫10(θ^+x−1)2(1−x)x99dx
用WolframAlpha解得
P(H)MMSE=argminθ^(5253θ^2−206θ^+constant)
P(H)MMSE=151>P(H)MLE=1100
解二:
用直觉一点的方式,MLE比较激进,“听风就是雨”,要是没看到人头,就会估计人头的出现概率为0,而MMSE就不会。MMSE比较保守,所造成的效果就是总把估计往先验(在此为均匀分布)拉一拉,因此MLE估高的MMSE就会估小一点儿,MLE估低MMSE就会估大一点儿。
61. a和b两个人每天都会在7点-8点之间到同一个车站乘坐公交车,a坐101路公交车,每5分钟一班【7:00,7:05....】,b坐102路公交车,每10分钟一班【7:03,7:13...】,问a和b碰面的概率是多少? ( C )
A.1/8 B.41/400 C.143/1200 D.199/1800 E.431/3600
解:
ab┗━━━━┳━━┻━━━━━━━┻━━━━┳━━┻━━━━━━━┻ ┅ ┅ ┅ ┻━━━━┳━━┻━━━━━━━┻━━━━┳━━┻━━━━━━━┛
上图表示7点-8点之间的60分钟区间内, a、b两人可用的乘车时间点(a上b下)
可以看出每10分钟有一个最小循环, 那么可以先就前10分钟的区间进行分析.
以b为主体, b的时间可以被各时间点切成三份 (30−3,23−5,55−10) , 那么在这个区间里, 两人相遇的概率是
360×30−360+260×130−1360+560×85−1360=753600
需要注意的是后两项"使用了"下一个循环区间的时间, 因此需要单独考虑最后10分钟的相遇概率
360×350−5360+260×1050−6060+560×555−6060=543600
汇总的相遇概率为
753600×5+543600=1431200
62. 假设某日是否有雨只和前一日是否有雨相关:今日有雨,则明日有雨的概率是0.7;今日无雨,则明日有雨的概率是0.5。如果周一有雨,求周三也有雨的概率 ( B)
A.0.5 B.0.64 C.0.72 D.0.81
解:
转移矩阵为
A=(0.70.50.30.5)
P(周三也有雨)=[(1 0)A2]1,1=[(0.7 0.3)(0.70.50.30.5)]1,1=0.64
63. 在large-scale且sparse的数据分析中,knn的k个最近邻应该如何选择 ( D )
A.随机选择 B.L1-norm最近的 C.L2-norm最近的 D.不用knn