高效缓存Memcached 集成使用说明
Memcached 介绍与分析
Memcached是一种集中式Cache,支持分布式横向扩展。总结几个它的特点来理解一下它的优点和限制。
Memory:内存存储,不言而喻,速度快,对于内存的要求高,不指出的话所缓存的内容非持久化。对于CPU要求很低,所以常常采用将Memcached服务端和一些CPU高消耗Memory低消耗应用部属在一起。(作为我们AEP正好有这样的环境,我们的接口服务器有多台,接口服务器对于CPU要求很高(由于WS-Security),但是对于Memory要求很低,因此可以用作Memcached的服务端部属机器)
集中式Cache:避开了分布式Cache的传播问题,但是需要非单点保证其可靠性,这个就是后面集成中所作的cluster的工作,可以将多个Memcached作为一个虚拟的cluster,同时对于cluster的读写和普通的memcached的读写性能没有差别。
分布式扩展:Memcached的很突出一个优点,就是采用了可分布式扩展的模式。可以将部属在一台机器上的多个Memcached服务端或者部署在多个机器上的Memcached服务端组成一个虚拟的服务端,对于调用者来说完全屏蔽和透明。提高的单机器的内存利用率,也提供了scale out的方式。
Socket通信:传输内容的大小以及序列化的问题需要注意,虽然Memcached通常会被放置到内网作为Cache,Socket传输速率应该比较高(当前支持Tcp和udp两种模式,同时根据客户端的不同可以选择使用nio的同步或者异步调用方式),但是序列化成本和带宽成本还是需要注意。这里也提一下序列化,对于对象序列化的性能往往让大家头痛,但是如果对于同一类的Class对象序列化传输,第一次序列化时间比较长,后续就会优化,其实也就是说序列化最大的消耗不是对象序列化,而是类的序列化。如果穿过去的只是字符串,那么是最好的,省去了序列化的操作,因此在Memcached中保存的往往是较小的内容。
特殊的内存分配机制:首先要说明的是Memcached支持最大的存储对象为1M。它的内存分配比较特殊,但是这样的分配方式其实也是对于性能考虑的,简单的分配机制可以更容易回收再分配,节省对于CPU的使用。这里用一个酒窖比喻来说明这种内存分配机制,首先在Memcached起来的时候可以通过参数设置使用的总共的Memory,这个就是建造一个酒窖,然后在有酒进入的时候,首先申请(通常是1M)的空间,用来建酒架,酒架根据这个酒瓶的大小分割酒架为多个小格子安放酒瓶,将同样大小范围内的酒瓶都放置在一类酒架上面。例如20cm半径的酒瓶放置在可以容纳20-25cm的酒架A上,30cm半径的酒瓶就放置在容纳25-30cm的酒架B上。回收机制也很简单,首先新酒入库,看看酒架是否有可以回收的地方,如果有直接使用,如果没有申请新的地方,如果申请不到,采用配置的过期策略。这个特点来看,如果要放的内容大小十分离散,同时大小比例相差梯度很明显,那么可能对于使用空间来说不好,可能在酒架A上就放了一瓶酒,但占用掉了一个酒架的位置。
Cache机制简单:有时候很多开源的项目做的面面俱到,但是最后也就是因为过于注重一些非必要性的功能而拖累了性能,这里要提到的就是Memcached的简单性。首先它没有什么同步,消息分发,两阶段提交等等,它就是一个很简单的Cache,把东西放进去,然后可以取出来,如果发现所提供的Key没有命中,那么就很直白的告诉你,你这个key没有任何对应的东西在缓存里,去数据库或者其他地方取,当你在外部数据源取到的时候,可以直接将内容置入到Cache中,这样下次就可以命中了。这里会提到怎么去同步这些数据,两种方式,一种就是在你修改了以后立刻更新Cache内容,这样就会即时生效。另一种是说容许有失效时间,到了失效时间,自然就会将内容删除,此时再去去的时候就会命中不了,然后再次将内容置入Cache,用来更新内容。后者用在一些时时性要求不高,写入不频繁的情况。
客户端的重要性:Memcached是用C写的一个服务端,客户端没有规定,反正是Socket传输,只要语言支持Socket通信,通过Command的简单协议就可以通信,但是客户端设计的合理十分重要,同时也给使用者提供了很大的空间去扩展和设计客户端来满足各种场景的需要,包括容错,权重,效率,特殊的功能性需求,嵌入框架等等。
几个应用点:小对象的缓存(用户的token,权限信息,资源信息)。小的静态资源缓存。Sql结果的缓存(这部分用的好,性能提高相当大,同时由于Memcached自身提供scale out,那么对于db scale out的老大难问题无疑是一剂好药)。ESB消息缓存。
集成设计
为什么需要集成?直接使用现有的两个Java实现Memcached是否就可以了?
当前集成主要为了两方面考虑,首先是方便的配置使用,如何将Memcached内嵌到类似于ASF以及其他框架中去,并且通过配置文件方便使用,这就需要作部分的集成工作,这部分工作主要是定义了配置文件以及通过Stax去解析配置的功能。然后是如何管理Memcached,这部分内容包括了初始化,运行期检测,资源回收的工作。最后是扩展,这里的扩展分成两部分(功能的扩展以及框架实现的扩展),功能扩展例如当前扩展了虚拟的cluster,可以让多个memcached Client组成一个虚拟的cluster,如果通过放入cluster的方式放入到其中一个Cache Client中的话,那么就可以在整个cluster都作好备份,这样其实可以根据memcached的单机多实例以及多机多实例作交互备份,提高可靠性。当然后续还有很多可以扩展的内容,这里只是一个开头。框架实现的扩展指的是这里采用了类似于Jdk的JAXP的框架设计,只是规定了框架API结构,至于实现者动态载入,这个和ASF等现在可扩展的框架一样,提供了很方便的扩展点,后续的设计中会提到。
接口设计类图:
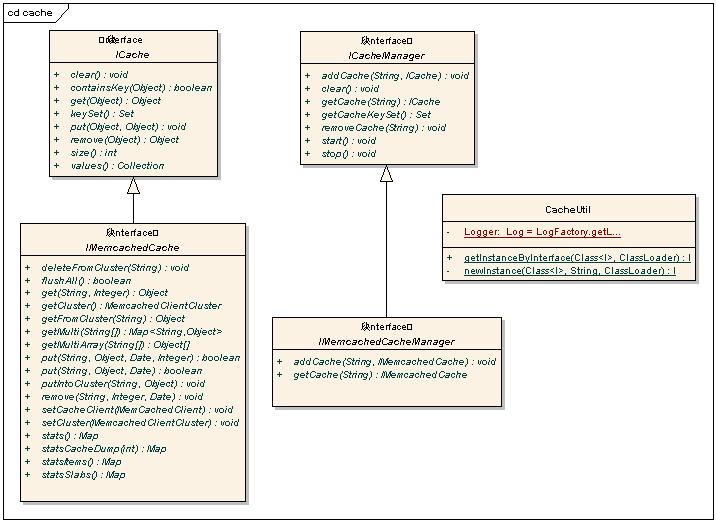
图1 Cache接口包类图
ICache和IMemcachedCache实现的是最基本的Cache的功能,只是IMemcachedCache有所增强,提供了对于虚拟的Cluster的操作,批量操作,统计的功能。ICacheManager和IMemcachedCacheManager分别是对于上面两个Cache的管理类,根据配置文件解析,初始化客户端池,建立虚拟集群,销毁客户端池等工作。

图2 Memcached 实现包
省略了一些辅助类定义。这部分是具体的实现,同时可以在图上看到spi包内的CacheManagerFactory就是用来提供扩展使用的接口。只需要定义在jar的META-INF下面建立services目录,建立两个名为:com.alisoft.xplatform.asf.cache.IMemcachedCacheManager和com.alisoft.xplatform.asf.cache.spi.CacheManagerFactory的文件就可以替换MemcachedCacheManager和CacheManagerFactory的实现类,从而改变Memcached Client实现机制。如果没有这两个文件在Classpath目录下面,那么默认将会使用当前框架中的两个实现。
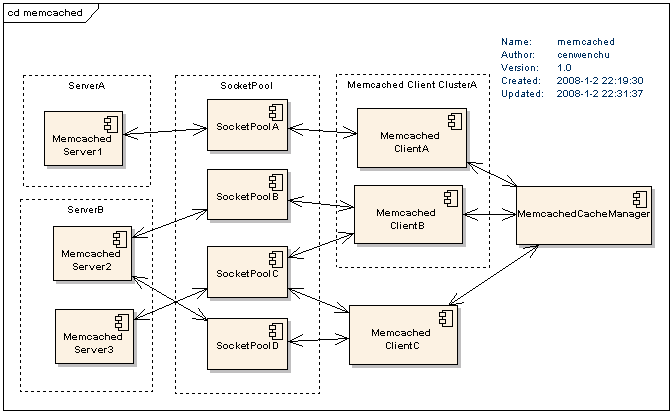
图3 Memcached的结构图
Memcached Server就是部署在不同服务器或者在同一台服务器上的Memcached实例,一般采用后台守护进程方式运行。SocketPool是客户端连接到服务端的Socket通信层,Memcached Client可以归属为虚拟的Cluster,MemcachedCacheManager作用是管理Cluster和Cache。从这个结构图可以看出客户端的每一层都是很独立,这样有利于层次的交互,以及组合扩展。
测试与使用
1. 配置:
需要有一个名为memcached.xml的文件在classpath中,可以在jar里面也可以在任意classpath可以找的到的地方,需要注意的是,CacheManager实现了对于多个memcached.xml merge的功能。
具体的配置内容如下:
<?xml version="1.0" encoding="UTF-8"?>
<memcached>//总标签
//memcached Client的配置,也就是一个IMemcachedCache的配置。Name必须填,表示Cache的名称,socketpool必须填,表示使用的远程通信连接池是哪一个,参看后面对于socketpool的定义。后面都是可选的,第三个参数表示传输的时候是否压缩,第四个参数表示默认的编码方式
<client name="mclient1" socketpool="pool1" compressEnable="true" defaultEncoding="UTF-8" >
<!--errorHandler></errorHandler-->//可定义错误处理类,一般不需要定义
</client>
<client name="mclient2" socketpool="pool2" compressEnable="true" defaultEncoding="UTF-8" >
</client>
//socketpool是通信连接池定义,每一个memcached Client要和服务端交互都必须有通信连接池作为底层数据通信的支持,name必填,表示名字,同时也是memcached client指定socketpool的依据,failover表示对于服务器出现问题时的自动修复。initConn初始的时候连接数,minConn表示最小闲置连接数,maxConn最大连接数,maintSleep表示是否需要延时结束(最好设置为0,如果设置延时的话那么就不能够立刻回收所有的资源,如果此时从新启动同样的资源分配,就会出现问题),nagle是TCP对于socket创建的算法,socketTO是socket连接超时时间,aliveCheck表示心跳检查,确定服务器的状态。Servers是memcached服务端开的地址和ip列表字符串,weights是上面服务器的权重,必须数量一致,否则权重无效
<socketpool name="pool1" failover="true" initConn="10" minConn="5" maxConn="250" maintSleep="0"
nagle="false" socketTO="3000" aliveCheck="true">
<servers>10.0.68.210:12000,10.0.68.210:12222</servers>
<weights>5,5</weights>
</socketpool>
<socketpool name="pool2" failover="true" initConn="10" minConn="5" maxConn="250" maintSleep="0"
nagle="false" socketTO="3000" aliveCheck="true">
<servers>10.0.68.210:22000,10.0.68.210:22222</servers>
<weights>5,5</weights>
</socketpool>
//虚拟集群设置,这里将几个client的cache设置为一个虚拟集群,当对这些IMemcachedCache作集群操作的时候,就会自动地对集群中所有的Cache作插入,寻找以及删除的操作,做一个虚拟交互备份
<cluster name="cluster1">
<memCachedClients>mclient1,mclient2</memCachedClients>
</cluster>
</memcached>
2. 测试代码,这里就附带一个单元测试类的代码就可以很清楚的知道使用方法。
后话
没有不好的,只有不适合的,适合的场景使用,根据场景适合的使用,才是提高性能的最有效手段。后需要根据所需的应用场景继续对这部分集成内容作完善,实践完善设计。