Introduction to Oracle Coherence
-
博客分类:
- Oracle
序:曾因为项目方财大气粗,并且极度青睐Oralce,幸而能在项目中接触并使用Oracle Coherence。期间我在公司内部做过一次Oracle Coherence的分享,为保证听众中的外国朋友不致于全场“坐飞机”,讲述内容以英文呈现。在此将讲述材料进一步整理与更多的朋友分享,就当是保证它的“原汁原味”吧,就不做翻译了,还请大家不要因此拍砖^_^
-----------------------------------------------------华丽分隔线----------------------------------------------------------------
Agenda
What is Coherence?
Demonstration
Technical
Code Examples
Architectural Patterns
What is Coherence?
Distributed Memory Data Management Solution(aka: Data Grid)
How Can a Data Grid Help?
1. Provides a reliable data tier with a single, consistent view of data
2. Enables dynamic data capacity including fault tolerance and load balancing
3. Ensures that data capacity scales with processing capacity

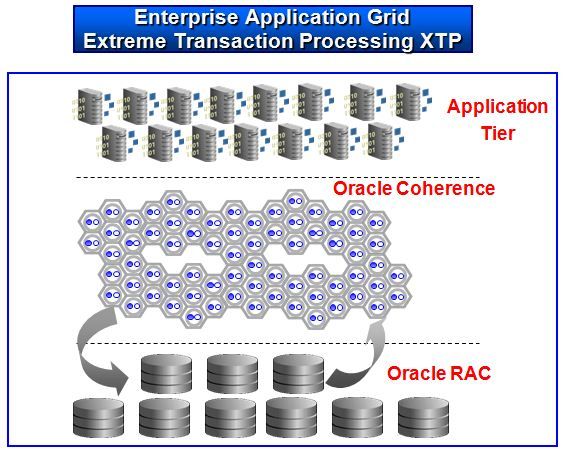
Oracle Grid Computing: Enterprise Ready
1. Common Shared Application Infrastructure (Application Virtualization)
2. Data Virtualization (Data as a Service)
3. Middle tier scale out for Grid Based OLTP
4. Massive Persistent scale out with Oracle RAC
Requirements of Enterprise Data Grid

Reliable
1. Built for continuous operation
2. Data Fault Tolerance
3. Self-Diagnosis and Healing
4. “Once and Only Once” Processing
Scalable
1. Dynamically Expandable
2. No data loss at any volume
3. No interruption of service
4. Leverage Commodity Hardware
5. Cost Effective
Universal
1. Single view of data
2. Single management view
3. Simple programming model
4. Any Application
5. Any Data Source
Data
1. Data Caching
2. Analytics
3. Transaction Processing
4. Event Processing
How Does Coherence Data Grid Work?
1. Cluster of nodes holding % of primary data locally
2. Back-up of primary data is distributed across all other nodes
3. Logical view of all data from any node

1. All nodes verify health of each other
2. In the event a node is unhealthy, other nodes diagnose state

1. Unhealthy node isolated from cluster
2. Remaining nodes redistribute primary and back-up responsibilities to healthy nodes
Customers & Coherence?
Caching: Applications request data from the Data Grid rather than backend data sources
Analytics: Applications ask the Data Grid questions from simple queries to advanced scenario modeling
Transactions: Data Grid acts as a transactional System of Record, hosting data and business logic
Events: Automated processing based on event
Coherence Demonstration
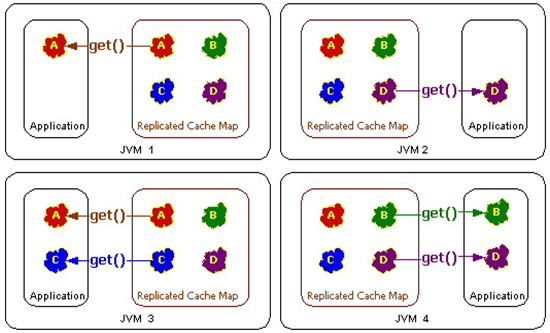
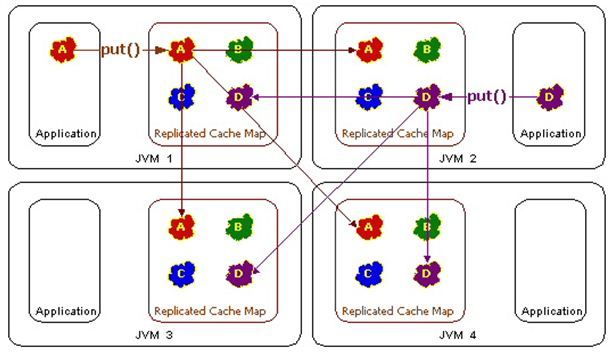
Topology #1 - Replicated Cache
Topology #2 - Partitioned Cache
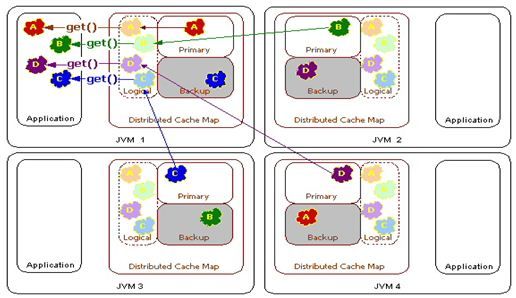
Topology #2 - Guaranteed Cluster Resiliency
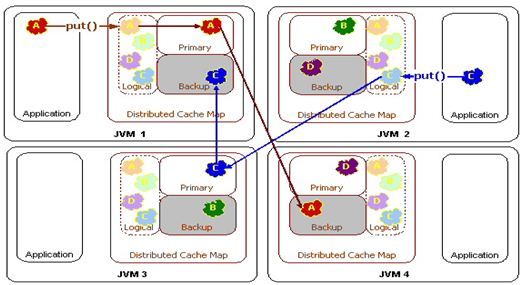
Topology #2 - Partitioned Failover
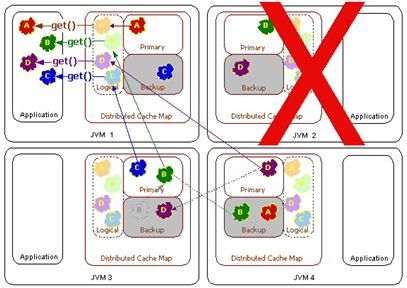
Topology #2a – Cache Client/Cache Server
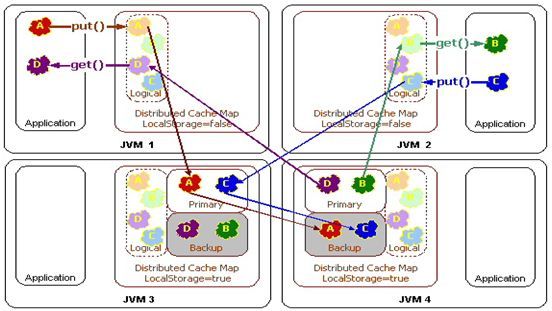
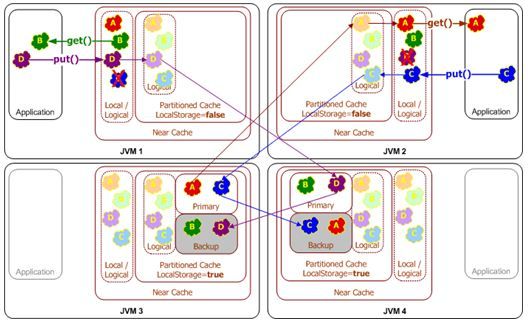
Topology #3 - Near Cache
Use Case: Coherence*Web
1. Coherence*Web is an HTTP session-management module (built-in feature of Coherence)
2. Supports a wide range of application servers.
3. Does not require any changes to the application.
4. Coherence*Web uses the NearCache technology to provide fully fault-tolerant caching, with almost unlimited scalability (to several hundred cluster nodes without issue).
5. Heterogeneous applications running on mixed hardware/OS/application servers can share common user session data. This dramatically simplifies supporting Single-Sign-On across applications.
Coherence*Web: Session State Management
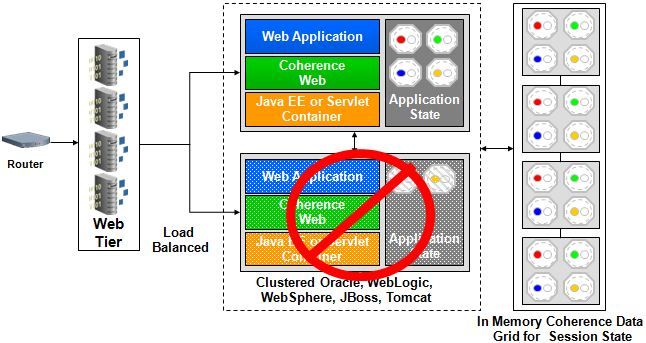
Build slide to show state is recoverable from the data grid. There is multiple important points here – the biggest is the ability to separate the session state to a tier independent of the application – you are offloading horsepower requirements in the middletier app server to the grid and getting significant reliability as a result of making this coherence.
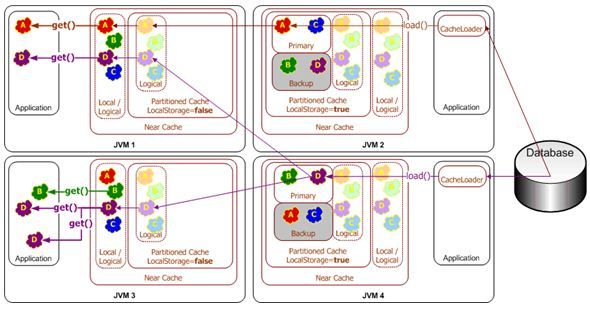
Read-Through Caching
Write-Through Caching
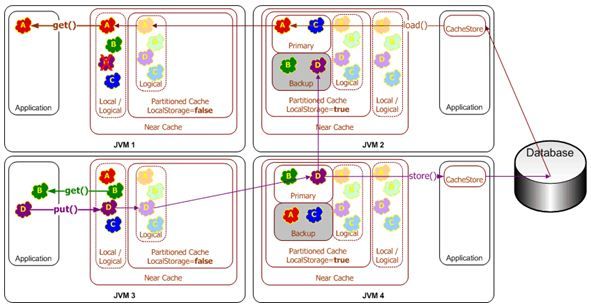
Write-Behind Caching
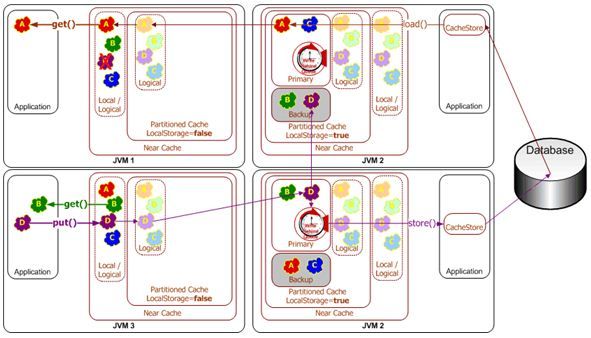
Coherence Code Examples
Clustering Java Processes
- Cluster cluster = CacheFactory.ensureCluster();
·Joins an existing cluster or forms a new cluster
Time “to join” configurable
·cluster contains information about the Cluster
Cluster Name
Members
Locations
Processes
·No “master” servers
·No “server registries”
Leaving a Cluster
- CacheFactory.shutdown();
·Leaves the current cluster
·shutdown blocks until “data” is safe
·Failing to call shutdown results in Coherence having to detect process death/exit and recover information from another process.
·Death detection and recovery is automatic
Using a Cache get, put, size & remove
- NamedCache nc = CacheFactory.getCache(“mine”);
- Object previous = nc.put(“key”, “hello world”);
- Object current = nc.get(“key”);
- int size = nc.size();
- Object value = nc.remove(“key”);
·CacheFactory resolves cache names (ie: “mine”) to configured NamedCaches
·NamedCache provides data topology agnostic access to information
·NamedCache interfaces implement several interfaces;
·java.util.Map, Jcache,
·ObservableMap*,
·ConcurrentMap*,
·QueryMap*,
·InvocableMap*
(* Coherence Extensions)
Using a Cache keySet, entrySet, containsKey
- NamedCache nc = CacheFactory.getCache(“mine”);
- Set keys = nc.keySet();
- Set entries = nc.entrySet();
- boolean exists = nc.containsKey(“key”);
·Using a NamedCache is like using a java.util.Map
·What is the difference between a Map and a Cache data-structure?
· Both use (key,value) pairs for entries
· Map entries don’t expire
· Cache entries may expire
· Maps are typically limited by heap space
· Caches are typically size limited (by number of entries or memory)
· Map content is typically in-process (on heap)
Observing Cache Changes ObservableMap
- NamedCache nc = CacheFactory.getCache(“stocks”);
- nc.addMapListener(new MapListener() {
- public void onInsert(MapEvent mapEvent) {
- }
- public void onUpdate(MapEvent mapEvent) {
- }
- public void onDelete(MapEvent mapEvent) {
- }
- });
·Observe changes in real-time as they occur in a NamedCache
·Options exist to optimize events by using Filters, (including pre and post condition checking) and reducing on-the-wire payload (Lite Events)
·Several MapListeners are provided out-of-the-box.
·Abstract, Multiplexing...
Querying Caches QueryMap
- NamedCache nc = CacheFactory.getCache(“people”);
- Set keys = nc.keySet( new LikeFilter(“getLastName”, “%Stone%”));
- Set entries = nc.entrySet(new EqualsFilter(“getAge”, 35));
·Query NamedCache keys and entries across a cluster (Data Grid) in parallel* using Filters
·Results may be ordered using natural ordering or custom comparators
·Filters provide support almost all SQL constructs
·Query using non-relational data representations and models
·Create your own Filters
( * Requires Enterprise Edition or above)
Continuous Observation Continuous Query Caches
- NamedCache nc = CacheFactory.getCache(“stocks”);
- NamedCache expensiveItems = new ContinuousQueryCache(nc, new GreaterThan(“getPrice”, 1000));
·ContinuousQueryCache provides real-time and in-process copy of filtered cached data
·Use standard or your own custom Filters to limit view
·Access to “view”of cached information is instant
·May use with MapListeners to support rendering real-time local views (aka: Think Client) of Data Grid information.
Aggregating Information InvocableMap
- NamedCache nc = CacheFactory.getCache(“stocks”);
- Double total = (Double)nc.aggregate(AlwaysFilter.INSTANCE,new DoubleSum(“getQuantity”));
- Set symbols = (Set)nc.aggregate(new EqualsFilter(“getOwner”, “Larry”), new DistinctValue(“getSymbol”));
·Aggregate values in a NamedCache across a cluster (Data Grid) in parallel* using Filters
·Aggregation constructs include; Distinct, Sum, Min, Max, Average, Having, Group By
·Aggregate using non-relational data models
·Create your own aggregators
(* Requires Enterprise Edition or above)
Mutating Information InvocableMap
- NamedCache nc = CacheFactory.getCache(“stocks”);
- nc.invokeAll(new EqualsFilter(“getSymbol”, “ORCL”), new StockSplitProcessor());
- ...
- class StockSplitProcessor extends AbstractProcessor {
- Object process(Entry entry) {
- Stock stock = (Stock)entry.getValue();
- stock.quantity *= 2;
- entry.setValue(stock);
- return null;
- }
- }
·Invoke EntryProcessors on zero or more entries in a NamedCache across a cluster (Data Grid) in
·parallel* (using Filters) to perform operations
·Execution occurs where the entries are managed in the cluster, not in the thread calling invoke
·This permits Data + Processing Affinity
(* Requires Enterprise Edition or above)
Oracle Coherence Architectural Patterns
Single Application Process
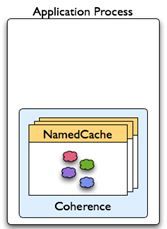
Coherence as “Data Structure”. Single applications may use Coherence java.util.Map interface implementations (and extensions) for high-performance, highly configurable caching. Clustering is not required!
Clustered Processes
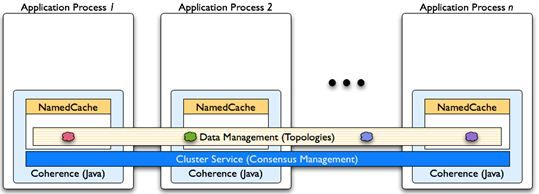
Coherence ensures that there is a consistent view of the data in-memory to all processes.
This is sometimes referred to as a “single-system-image”
Multi Platform Cluster
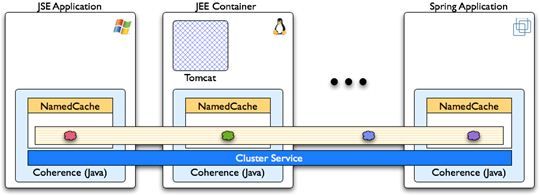
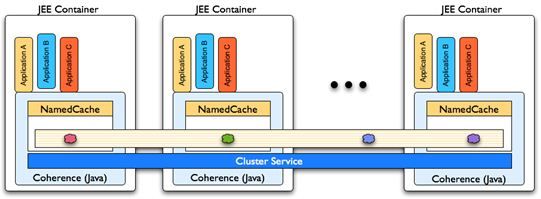
Clustered Application Servers
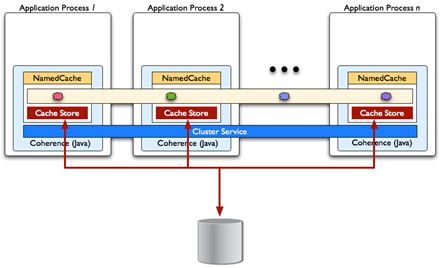
With Data Source Integration (Cache Stores)
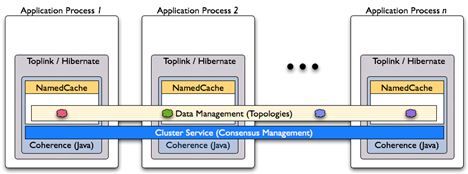
Clustered Second Level Cache (for Hibernate)
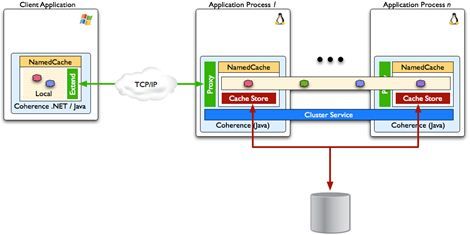
Remote Clients connected to Coherence Cluster
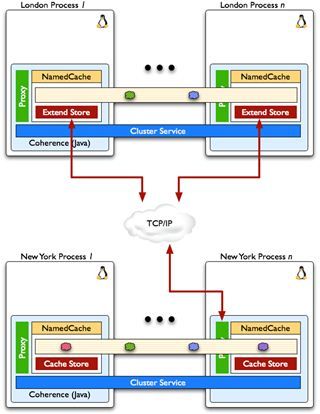
Interconnected WAN Clusters
Getting Oracle Coherence
Search:
http://search.oracle.com
Download:
http://www.oracle.com/technology/products/coherence
Support:
http://forums.tangosol.com
http://wiki.tangosol.com
Read More:
http://www.tangosol.com/