不同平台字节序影响位字段封包
How Endianness Effects Bitfield Packing
Hints for porting drivers.Big endian machines pack bitfields from most significant byte to least.
Little endian machines pack bitfields from least significant byte to most.
When we read hexidecimal numbers ourselves, we read them from most significant byte to least. So reading big endian memory dumps is easer than reading little endian. When it comes to reading memory dumps of bitfields, it is even harder than reading integers.
Consider:
union {
unsigned short value;
unsigned char byte[2];
struct {
unsigned short a : 4;
unsigned short b : 4;
unsigned short c : 4;
unsigned short d : 4;
} field;
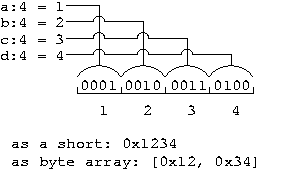
} u; On a big endian machine, the first field is in the first nibble in memory. When we print out a memory dump's character hex values, say [ 0x12, 0x34 ], it is easy to see that a = 1, b = 2, c = 3 and d = 4.
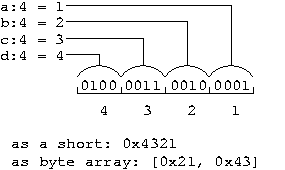
On a little endian machine, a memory dump of [ 0x12, 0x34 ] would indicate that a = 2, b = 1, c = 4, and d = 3. This is because our 2-nibble, or 1 byte, hex value has transposed the pairs of nibbles. Remember that field a would go in the least significant bits, so if we set (a, b, c, d) = (1, 2, 3, 4) we would read the nibbles from least significant to most as 1 2 3 4, but the bytes as 0x21, 0x43. Interpreting this memory as a short gives us the value 0x4321.
These two figures illustrate how the nibble sized elements are packed into memory with the 16 bit field being laid out from MSB to LSB.
 |
 |
| Big Endian Layout | Little Endian Layout |
|---|
union {
unsigned short value;
unsigned char byte[2];
struct {
unsigned short a : 1;
unsigned short b : 2;
unsigned short c : 3;
unsigned short d : 4;
unsigned short e : 5;
} field;
} v; Again, the bits are pack from most significant on a big endian machine and least significant on a little endian machine. Interpreted as a short, the bitfield 'a' adds 0x0001 to 'value' on a little endian machine and 0x8000 on a big endian machine. The unused bit is left to the end of interpreting the struct, so it is the MSB on a little endian machine and the LSB on a big endian machine.
These two figures illustrate how the differently sized elements are packed into memory with the 16 bit field being laid out from MSB to LSB.
 |
 |
| Big Endian Layout | Little Endian Layout |
|---|
If I had a device that took a message in little endian order, as PC devices often do, and wanted to write endian portable driver code, I would write something like this:
struct message {
uint16 word;
struct {
#ifdef LITTLE_ENDIAN
uint16 dir : 1;
uint16 reg : 5;
uint16 val : 8;
uint16 : 1;
#else
uint16 : 1;
uint16 val : 8;
uint16 reg : 5;
uint16 dir : 1;
#endif
} field;
};
Fill in the fields of the message m using m.field.reg, etc. The, place the message into a transfer buffer:
buf[i] = m.word & 0xFF;
buf[i+1] = m.word >> 8 & 0xFF;
You will see Intel coders doing stuff like this:
*(uint16*)&buf[i] = m.word;This is because x86 CPUs have no alignment rules. Doing this will cause a bus error on most CPUs for odd values of i.
Here is a test program you can play around with on machines of various architectures.
引用:http://mjfrazer.org/mjfrazer/bitfields/