bloom filter与Cuckoo Filter
下面是每个字符串处理的过程,首先是将字符串str“记录”到BitSet中的过程:
对于字符串str,分别计算h(1,str),h(2,str)…… h(k,str)。然后将BitSet的第h(1,str)、h(2,str)…… h(k,str)位设为1。
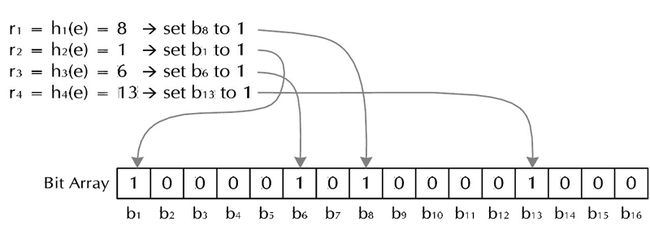
图1.Bloom Filter加入字符串过程
这样就将字符串str映射到BitSet中的k个二进制位了。
(2) 检查字符串是否存在的过程
下面是检查字符串str是否被BitSet记录过的过程:
对于字符串str,分别计算h(1,str),h(2,str)…… h(k,str)。然后检查BitSet的第h(1,str)、h(2,str)…… h(k,str)位是否为1,若其中任何一位不为1则可以判定str一定没有被记录过。若全部位都是1,则“认为”字符串str存在。
若一个字符串对应的Bit不全为1,则可以肯定该字符串一定没有被Bloom Filter记录过。(这是显然的,因为字符串被记录过,其对应的二进制位肯定全部被设为1了)
但是若一个字符串对应的Bit全为1,实际上是不能100%的肯定该字符串被Bloom Filter记录过的。(因为有可能该字符串的所有位都刚好是被其他字符串所对应)这种将该字符串划分错的情况,称为false positive 。
(3) 删除字符串过程 字符串加入了就被不能删除了,因为删除会影响到其他字符串。实在需要删除字符串的可以使用Counting bloomfilter(CBF),这是一种基本Bloom Filter的变体,CBF将基本Bloom Filter每一个Bit改为一个计数器,这样就可以实现删除字符串的功能了。
Bloom Filter参数选择:
(1)哈希函数选择
哈希函数的选择对性能的影响应该是很大的,一个好的哈希函数要能近似等概率的将字符串映射到各个Bit。选择k个不同的哈希函数比较麻烦,一种简单的方法是选择一个哈希函数,然后送入k个不同的参数。
(2)Bit数组大小选择
哈希函数个数k、位数组大小m、加入的字符串数量n的关系可以参考文献1。该文献证明了对于给定的m、n,当 k = ln(2)* m/n 时出错的概率是最小的。
同时该文献还给出特定的k,m,n的出错概率。例如:根据参考文献1,哈希函数个数k取10,位数组大小m设为字符串个数n的20倍时,false positive发生的概率是0.0000889 ,这个概率基本能满足网络爬虫的需求了。
标准的Bloom Filter是一种很简单的数据结构,它只支持插入和查找两种操作。在所要表达的集合是静态集合的时候,标准Bloom Filter可以很好地工作,但是如果要表达的集合经常变动,标准Bloom Filter的弊端就显现出来了,因为它不支持删除操作。
Counting Bloom Filter的出现解决了这个问题,它将标准Bloom Filter位数组的每一位扩展为一个小的计数器(Counter),在插入元素时给对应的k(k为哈希函数个数)个Counter的值分别加1,删除元素时给对应的k个Counter的值分别减1。Counting Bloom Filter通过多占用几倍的存储空间的代价,给Bloom Filter增加了删除操作。下一个问题自然就是,到底要多占用几倍呢?

我们先计算第i个Counter被增加j次的概率,其中n为集合元素个数,k为哈希函数个数,m为Counter个数(对应着原来位数组的大小):

上面等式右端的表达式中,前一部分表示从nk次哈希中选择j次,中间部分表示j次哈希都选中了第i个Counter,后一部分表示其它nk – j次哈希都没有选中第i个Counter。因此,第i个Counter的值大于j的概率可以限定为:
![]()
上式第二步缩放中应用了估计阶乘的斯特林公式:
![]()
在Bloom Filter中,我们提到过k的最优值为(ln2)m/n,现在我们限制k ≤ (ln2)m/n,就可以得到如下结论:

如果每个Counter分配4位,那么当Counter的值达到16时就会溢出。这个概率为:
![]()
这个值足够小,因此对于大多数应用程序来说,4位就足够了。
关于Counting Bloom Filter最早的论文:Summary Cache: A Scalable Wide-Area Web Cache Sharing Protocol
3. Cuckoo Filter
为了解决上面提到的问题,本文引入了一种新的哈希算法——cuckoo filter,它既可以确保该元素存在的必然性,又可以在不违背此前提下删除任意元素,仅仅比bitmap牺牲了微量空间效率。先说明一下,这个算法的思想来源是一篇CMU论文,笔者按照其思路用C语言做了一个简单实现(Github),附上对一段文本数据进行导入导出的正确性测试。
接下来我会结合自己的示例代码讲解哈希算法的实现。我们先来看看cuckoo hashing有什么特点,它的哈希函数是成对的(具体的实现可以根据需求设计),每一个元素都是两个,分别映射到两个位置,一个是记录的位置,另一个是备用位置。这个备用位置是处理碰撞时用的,这就要说到cuckoo这个名词的典故了,中文名叫布谷鸟,这种鸟有一种即狡猾又贪婪的习性,它不肯自己筑巢,而是把蛋下到别的鸟巢里,而且它的幼鸟又会比别的鸟早出生,布谷幼鸟天生有一种残忍的动作,幼鸟会拼命把未出生的其它鸟蛋挤出窝巢,今后以便独享“养父母”的食物。借助生物学上这一典故,cuckoo hashing处理碰撞的方法,就是把原来占用位置的这个元素踢走,不过被踢出去的元素还要比鸟蛋幸运,因为它还有一个备用位置可以安置,如果备用位置上还有人,再把它踢走,如此往复。直到被踢的次数达到一个上限,才确认哈希表已满,并执行rehash操作。如下图所示:

我们不禁要问发生哈希碰撞之前的空间利用率是多少呢?不幸地告诉你,一维数组的哈希表上跟其它哈希函数没什么区别,也就50%而已。但如果是二维的呢?
一个改进的哈希表如下图所示,每个桶(bucket)有4路槽位(slot)。当哈希函数映射到同一个bucket中,在其它三路slot未被填满之前,是不会有元素被踢的,这大大缓冲了碰撞的几率。笔者自己的简单实现上测过,采用二维哈希表(4路slot)大约80%的占用率(CMU论文数据据说达到90%以上,应该是扩大了slot关联数目所致)。

Cuckoo Filter的代码相关实现请见:https://github.com/begeekmyfriend/CuckooFilter
参考文献:
[1] Pei Cao. Bloom Filters - the math.
http://pages.cs.wisc.edu/~cao/papers/summary-cache/node8.html
[2] Wikipedia. Bloom filter.
http://en.wikipedia.org/wiki/Bloom_filter
[3] http://coolshell.cn/articles/17225.html
[4] Cuckoo Filter: Practically Better Than Bloom