机器学习中使用的神经网络第六讲笔记
博客已经迁移至Marcovaldo’s blog (http://marcovaldong.github.io/)
Geoffery Hinton教授的Neuron Networks for Machine Learning的第六讲介绍了随机梯度下降法(SGD),并且介绍了加快学习速度的动量方法(the momentum method)、针对网络中每一个连接的自适应学习步长(adaptive learning rates for each connection)和RMSProp算法。
这几个算法的难度很大,需要反复推理思考,并在实践中摸索以加深理解。
Overview of mini-batch gradient descent
这一小节介绍随机梯度下降法(stochastic gradient descent)在神经网络中的使用,随机梯度下降法在Andrew Ng的课程中已有介绍,所以这里可能会有所简略,大家可以阅读Machine Learning第十周笔记:大规模机器学习。
这里首先回顾了第三讲中介绍的线性神经网络的误差曲面(error surface),如下图所示。线性神经网络对应的误差曲面的纵截面如碗装,横截面则如一组同心的椭圆。梯度下降法的作用就是不断调整参数,使得模型的误差由“碗沿”降到“碗底”,参数由椭圆外部移动到椭圆的中心附近。当然,这里说的是只有两个参数的情况,参数更多的情况则更复杂。
下图给出了梯度方向对梯度改变大小的影响。

下图说明了学习步长(learning rate)对损失函数改变的影响。过大的学习速率会导致损失函数越来越大,模型距离最优解(或次优解)越来越远。

上面是模型在所有的训练数据上做完梯度下降法之后再对参数进行修正的,这叫做批量梯度下降法(batch gradient descent)。而随机梯度下降法则是每一次计算某一个训练数据上的梯度或者某一组训练数据(训练数据集的一个很小的子集)的梯度,然后更新参数。在每一个训练数据上计算梯度然后更新参数的称之为在线学习(online learning),在一小组训练数据上计算梯度然后更新参数的称之为小批量梯度下降法(mini-batch gradient descent),后者的效果可能比前者好一些。


下图是对使用mini-batch gradient descent的几点建议。

A bag of tricks for mini-batch gradient descent
这一小节介绍使用小批量梯度下降法(mini-batch gradient descent)的一些技巧。下图是初始化权值参数的技巧。

下图介绍的是shifting the inputs,其是指给输入的每一个分量加上一个常数值,使不得输入的平均值为0。(这里的意思应该是给输入的每一个分量加上一个常数,不同分量的常数可能不同,使得训练数据集的所有输入加在一起是个零向量。当然,这是我自己的理解,可能有出入。)下图给出了一个二维的线性神经网络,且给出了两组训练数据及其相应向量参数对应的直线。可以看到上面的那两条直线夹角很小,二者结合在一起就会得到一个很狭长的椭圆的error surface,这样的是我们不喜欢的error surface,不利于快速找到最优解或次优解。下面我们给输入的每一个分量都加上一个-100,然后得到的error surface就有一个比较接近圆的形状,这样的是我们想要的,便于快速的找到最优解或次优解。另外这里还提到了对隐匿层神经单元的调整,比较了双曲正切函数(hyperbolic tangent function)和逻辑函数(logistic function),但是这里没听明白具体怎么使用。

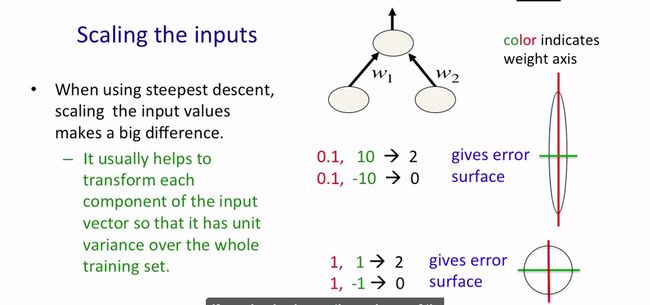
下图介绍的是scaling the inputs,该情况针对的是输入向量的分量取值相差悬殊时,通过给分量乘上一个系数来使得error surface更接近圆形,从而便于快速找到最优解或次优解。
一个更thorough的方法是去除输入向量不同分量之间的相关性(decorrelate the input components),相关的方法很多,这里给出了主成分分析法(PCA, Principal Components Analysis)。在Andrew Ng的课程中详细介绍过PCA,详细内容请阅读Machine Learning第八周笔记:K-means和降维
。对于线性模型,PCA实现了降维,从而将椭圆形的error surface转换成了圆形的。
下图列出了在多层神经网络中经常遇到的两个问题。一个是,当我们以很大的学习步长(learning rate)开始训练网络时,隐匿单元的权重往往会取到很大的正数或很小的负数,而此时这些权重对应的梯度又很小,给我们造成一种模型好像取得了一个局部最小值。另一个是,在分类网络中,我们经常使用平方误差或者交叉熵误差,一个好的策略是让每一个输出单元的输出情况和实际上的输出比例相当(实际上输出1的比例是多少,那么输出单元的输出情况一个就是这样)。神经网络很快就会发现这一策略,但需要很长的时间才能一点点的优化网络,看起来就好像模型处于一个局部最小值附近。

下图提示我们不要太快得减小学习步长(learning rate)。

下面给出四种加快mini-batch learning的方法,前三种我们会在下面一一介绍,最后一种本课程不涉及,感兴趣的话请自行搜索。这些方法具有很强的技巧性,需要我们在应用中不断摸索。

The momentum method
这一小节详细介绍动量方法(the momentum method),其应用很广泛,在full-batch learning和mini-batch learning中都可以使用。下面给出了动量方法的intuition和计算公式。

Using momentum speeds up gradient descent learning because
- Directions of consistent change get amplified.
- Directions of fluctuations get damped.
- Allows using much larger learning rates.
Momentum accumulates consistent components of the gradient and attenuates the fluctuating ones. It also allows us to use bigger learning rate because the learning is now more stable.
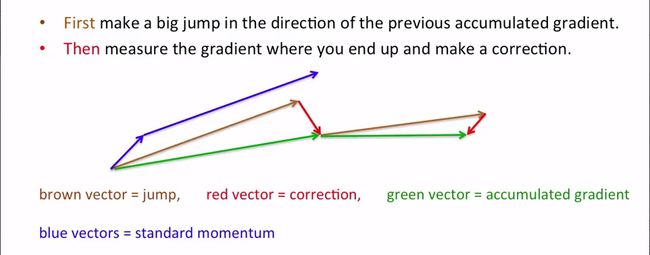
标准的动量方法(由Nesterov在1983年提出)是在当前位置计算梯度,然后在累积的更新梯度方向上做一个大的跳跃。下面给出了一种更好地动量方法(由IIya Sutskever在2012年提出),其先在先前累积的梯度方向上做一个大的跳跃,再计算新的梯度并修正错误。
下面对两种方法做了比较,图中蓝色箭头是做两次标准动量方法得到的;而图中棕色箭头是改进动量方法先做的一次大跳跃得到的,红色箭头是修正,绿色箭头是进行一次改进动量方法得到的。可以看到,改进的比标准的要快很多。
Adaptive learning rates for each connection
这一小节介绍the separate, adaptive learning rate for each connection(针对网络中每个连接的自适应学习步长)。其思想是在神经网络的每一个连接处都应该有该连接自己的自适应学习步长,并在我们调整该连接对应的参数时调整自己的学习步长:如果权值参数修正梯度,那就应该减小步长;反之,应该增大步长。
下图给出了intuition。我的理解是在多层神经网络中,不同层的梯度通常相差悬殊,最开始的几层对应的梯度可能比最后几层权值对应的梯度小几个数量级。另外一方面,网络中每一单元又受其扇入单元的影响,为了修正一个同样的错误,各个单元的“学习步长”应该是不同的。

一个可行的方法是有一个全局的学习步长,然后对每一个权值参数有一个local gain,用 gij 表示。初始时 gij 均取值为1,后每次迭代根据权值梯度的变化情况作出调整,具体调整公式如下图所示。

下图列出了几种提高自适应学习步长性能的几个技巧。
Rmsprop: Divide the gradient by a running average of its recent magnitude
这一小节介绍rmsprop算法。在网上找到一个python模块——climin,一个做优化的机器学习包,里面包含了很多优化算法。
首先介绍rprop算法。前面我们说过,不同权值参数的梯度的数量级可能相差很大,因此很难找到一个全局的学习步长。这时,我们想到了在full-batch learning中仅靠权值梯度的符号来选择学习步长。rprop算法正是采用这样的思想:对于网络中的每一个权值参数,当其对应的前面两个梯度符号相同时,则增大该权值参数对应的学习步长;反之,则减小对应的学习步长。并且,rprop算法将每一个权值对应的学习步长限制在百万分之一到50之间。

下图解释了prop算法为什么不能应用于mini-batch learning中。因为prop算法违背了随机梯度下降的原理:假设有一个在线学习系统,初始的学习步长较小,在其上应用prop算法。这里有十组训练数据,前九组都使得梯度符号与之前的梯度符号相同,那么学习步长就会增加九次;而第十次得来的梯度符号与之前的相反,那么学习步长就会减小一次。这样一个过程下来,学习步长会增长很多,如果系统的训练数据集非常之大,那学习步长可能频繁的来回波动,这样肯定是不利于学习的。

设想是否存在这样一种算法,其既能保持rprop算法的健壮性,又能应用在mini-batch learning上呢,rmsprop算法应运而生。rmsprop算法不再孤立地更新学习步长,而是联系之前的每一次梯度变化情况,具体如下。rmsprop算法给每一个权值一个变量MeanSquare(w,t)用来记录第t次更新步长时前t次的梯度平方的平均值,具体计算方法如下图所示(注意,其中的系数0.9和0.1只是个例子,具体取值还要看具体情况)。然后再用第t次的梯度除上 MeanSquare(w,t)−−−−−−−−−−−−−−√ 得到学习步长的更新比例,根据此比例去得到新的学习步长。按我的理解,如果当前得到的梯度为负,那学习步长就会减小一点点;如果当前得到的梯度为正,那学习步长就会增大一点点。这里的 MeanSquare(w,t)−−−−−−−−−−−−−−√ 是名称中RMS的由来。

下图列出了关于rmsprop算法的一些研究,想了解详情的话请自行搜索。

最后一张图是对神经网络学习方法的一个小总结。

这几个算法都比较烧脑啊,全是凭大脑推理思考,回头要好好做实验。