网易视频云技术分享:linux软raid的bitmap分析
网易视频云是网易倾力打造的一款基于云计算的分布式多媒体处理集群和专业音视频技术,提供稳定流畅、低时延、高并发的视频直播、录制、存储、转码及点播等音视频的PAAS服务,在线教育、远程医疗、娱乐秀场、在线金融等各行业及企业用户只需经过简单的开发即可打造在线音视频平台。现在,网易视频云的技术专家给大家分享一则技术文:linux软raid的bitmap分析。
在使用raid1,raid5等磁盘阵列的时候,对于数据的可靠性有很高的要求,raid5在写的时候需要计算校验并写入,raid1则写源和镜像来保证数据的一致性,在写的过程中,有可能存在不稳定的因素,比如磁盘损坏,系统故障等,这样导致写入失败,在系统恢复后,raid也需要进行恢复,传统的恢复方式就是全盘扫描计算校验或者全量同步,如果磁盘比较大,那同步恢复的过程会很长,有可能再发生其他故障,这样就会对业务有比较大的影响。以raid1来说,在发生故障时,其实两块盘的数据很多都是已经一致的了,可能只有少部分不一致,所以就没必要进行全盘扫描,但是系统并不知道两块盘哪些数据是一致的,这就需要在某个地方记录哪些是已同步的,为此,就诞生了bitmap,简单来说,bitmap就是记录raid中哪些数据是一致的,哪些是不一致的,这样在raid进行恢复的时候就不用全量同步,而是增量同步了,从而减少了恢复的时间。
1. bitmap的使用
bitmap的使用比较简单,mdadm的帮助文档里有很详细的说明。bitmap分两种,一种是internal,一种是external。
internal bitmap是存放在raid设备的成员盘的superblock附近(可以在之前也可以在之后),而external是单独指定一个文件用来存放bitmap。
这里简单的介绍一下bitmap的使用。
# mdadm –create /dev/md/test_md1 –run –force –metadata=0.9 –assume-clean –bitmap=/mnt/test/bitmap_md1 –level=1 –raid-devices=2 /dev/sdb /dev/sdc
mdadm: /dev/sdb appears to be part of a raid array:
level=raid1 devices=2 ctime=Tue Dec 17 21:00:58 2013
mdadm: array /dev/md/test_md1 started.
查看md的状态
#cat /proc/mdstat
Personalities : [raid1]
md126 : active raid1 sdc[1] sdb[0]
2097216 blocks [2/2] [UU]
bitmap: 1/257 pages [4KB], 4KB chunk, file: /mnt/test/bitmap_md1
可以看到最后一行就是md126的bitmap信息,这里的默认bitmap的chunksize是4KB,可以通过–bitmap-chunk来指定bitmap chunk大小,bitmap的chunk表示在bitmap中
1bit对应md设备的一个chunk(大小为bitmap的chunksize)。
这里对cat /proc/mdstat查看到的bitmap的信息进行说明。
其中的4KB chunk表示bitmap的chunk大小是4KB;
1/257 pages指的是bitmap所对应的内存位图(作为磁盘上的bitmap的缓存,提高对位图的操作效率),257是内存bitmap占的总page数,1表示已经分配的page数,内存bitmap是动态分配的,使用完后就可以回收。内存位图使用16bit来表征一个chunk,其中的14bit用来统计该chunk上正在进行的写io数(后面会有详细的介绍)。
[4KB]表示已经分配的内存位图page总大小。
总的chunk数=md设备大小/bitmap的chunk大小
内存bitmap一个page可以表示的chunk数=PAGE_SIZE*8/16
内存bitmap占的总page数=总的chunk数/内存bitmap一个page可以表示的chunk数
上面给出的例子中总的chunk数为2097216KB/4KB=524304
取页大小为4096,一个page可以表示的chunk数为4096*8/16=2048
总共需要524304/2048=256个page,看实际上是257,这是因为有可能不能整除的情况,最后一个page可能不是全部都使用。
2. bitmap的内存结构
bitmap的结构体有比较多的字段,这里关注几个重要的字段,加以说明,便于后面的分析。
struct bitmap {
struct bitmap_page *bp; /* 指向内存位图页的结构*/
……
unsigned long chunks; /* 阵列总的chunk数 */
……
struct file *file; /* bitmap文件 */
……
struct page **filemap; /* 位图文件的缓存页 */
unsigned long *filemap_attr; /* 位图文件缓存页的属性 */
……
};
其中struct bitmap_page结构如下:
struct bitmap_page {
char *map; /* 指向实际分配的内存页*/
/*
* in emergencies (when map cannot be alloced), hijack the map
* pointer and use it as two counters itself
*/
unsigned int hijacked:1;
/*
* count of dirty bits on the page
*/
unsigned int count:31; /* 该页上有多少脏的chunk,每16bit表示一个chunk*/
};
实际动态分配的每个内存页,每16bit对应bitmap file的一个bit,即表示md的一个chunk
这16个bit的作用如下:
15 14 13 0
+————-+———-+————————————-+
| needed |resync | counter |
+————-+———-+————————————+
最高一位表示是否需要同步,后面一位表示是否正在同步,低14bit是counter,用来统计该chunk有多少正在进行的写io。
这14bit表示的counter记为bmc,方便后面描述。bmc的值0,1,2比较特殊,为0时表示对应chunk还未进行写操作,内存位图还未置位,bmc为1时表示内存位图已经置位,bmc为2表示所有写操作刚结束,真正的写io数是从2开始累加的。
bitmap结构中的filemap表示bitmap file的对应缓存,bitmap file有多大,对应的这个filemap缓存就有多大,在初始化的时候就分配好的。
filemap_attr 表示位图文件缓存页的属性,使用4bit来表示一个缓存页的属性,
第0bit是BITMAP_PAGE_DIRTY,该bit为1表示内存bitmap中为脏,但是bitmap file中的对应位不为脏,因此对于有这种标记的page需要同步刷到磁盘(实际上是异步调用write_page,但是等到写完成)
第1bit是BITMAP_PAGE_PENDING,置位后表示内存bitmap中的脏位已经清0,但是此时外存bitmap file中的对应脏位没有清0,需要进行清0的操作,这是一个过渡状态,过渡到BITMAP_PAGE_NEEDWRITE。
第2bit是BITMAP_PAGE_NEEDWRITE,置位后表示需要进行同步,把内存位图缓存中的数据刷到外部位图文件中,所对于这种标记的page只需要异步写,因为即使写失败,最多带来额外的同步,不会带来数据的危害。
第3bit在代码中没有看到使用,猜测是预留的。
bp中的page和filemap对应的page以及bitmap file的关系如下:
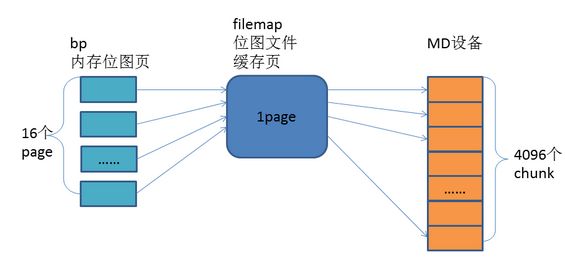
1个位图文件缓存页可以表示4096个chunk,而内存位图页则需要16个page。bp数组所对应的内存位图页的作用其实是控制bitmap的置位与复位,并且也控制一个chunk上的io不能超过最大值(14bit表示的最大整数),达到最大值的时候会进行io schedule。
3.bitmap的可靠刷新机制
在进行写操作的时候,是先把bitmap的对应位置为脏,然后再进行写操作,写完成后再复位。那么如何保证每次写操作时,内存bitmap中的数据都被可靠刷到对应的磁盘bitmap file中?
一般的逻辑是在写io到md设备前,先在bitmap中标记为dirty(成功刷到磁盘中),然后执行写io,io完成后需要清理dirty的标记这就需要在正常数据写操作之前,完成bitmap的刷新操作。那么bitmap如何实现呢?
以raid1为例,md在make_request中,调用了bitmap_startwrite函数,但是这个函数并没有直接调用write_page刷新数据到磁盘,而是调用了bitmap_file_set_bit将bitmap位标记为BITMAP_PAGE_DIRTY。之所以不在bitmap_startwrite函数中调用write_page刷新,是因为块设备的io操作是通过queue队列进行的,不能保证每次io操作都能及时完成,而且io调度的顺序也可能调换,因此如果直接调用write_page进行写操作的话,就有可能存在bitmap的刷新和正常的数据写操作的顺序发生颠倒。
真正处理BITMAP_PAGE_DIRTY是在bitmap_unplug中,对于raid1来说,bitmap_unplug是在raid1.c中的flush_pending_writes函数中调用的,而flush_pending_writes是由raid1的守护进程raid1d调用的。flush_pending_writes会调用bitmap_unplug刷新bitmap到磁盘,然后遍历conf->pending_bio_list,取出bio来处理正常挂起的写io。(在raid1的make_request中会把mbio加到conf->pending_bio_list中)
从上面的分析可知,raid1在收到写io请求时,先把内存位图置为dirty,并把该写io加到pending_list,然后raid1d守护进程会把标记为dirty的内存位图页刷到外存的位图文件中,然后从pendling_list中取出之前挂起的写io进行处理。
在刷脏页时,需要把位图文件缓存页的数据写到位图文件中,因为md是内核态的程序,在实现时并没有直接调用通常的写函数往外存的文件写数据,而是通过bmap机制,根据inode,把文件数据块和物理磁盘块映射起来,这样就可以透过文件系统,调用submit_bh进行bitmap的刷新。
上面描述的可靠刷新机制也就是bitmap设置的过程,下面分析bitmap清理的逻辑。
4.bitmap位的清除
前面说到从pending_list中取出写io进行处理,当io完成后需要清除dirty的标记,会把内存位图页的属性设置为BITMAP_PAGE_PENDING,表示正要去清除,BITMAP_PAGE_PENDING属性页并不会立即刷到外存的位图文件中,而是异步清0的过程。真正的清理流程在bitmap_daemon_work中实现。这是有raid的守护进程定期执行时调用的(比如raid1d),守护进程会定期调用md_check_recovery,然后md_check_recovery会调用bitmap_daemon_work根据各种状态进行清0的操作。
bitmap_daemon_work的实现比较复杂,里面各种状态判断与转换,很容易把人绕晕,bitmap的清0(内存位图页的bit清0及刷到外存的位图文件)是需要经过3次调用bitmap_daemon_work。下面以1个bit的清理来阐述,在io完成后,在bitmap_endwrite中会把这边bit的计数器bmc会置为2(前提是这个bit对应的chunk上的写io都完成),并标记位为BITMAP_PAGE_PENDING。
1)第一次进入bitmap_daemon_work,bmc=2,页属性为BITMAP_PAGE_PENDING。
这里判断位是否为BITMAP_PAGE_PENDING,这时候bit所对应的确实是BITMAP_PAGE_PENDING,所以跳过这个判断里的处理逻辑
if (!test_page_attr(bitmap, page, BITMAP_PAGE_PENDING)) {
int need_write = test_page_attr(bitmap, page,
BITMAP_PAGE_NEEDWRITE);
if (need_write)
clear_page_attr(bitmap, page, BITMAP_PAGE_NEEDWRITE);spin_unlock_irqrestore(&bitmap->lock, flags);
if (need_write)
write_page(bitmap, page, 0);
spin_lock_irqsave(&bitmap->lock, flags);
j |= (PAGE_BITS – 1);
continue;
}
接着执行后续的,
这里会判断page是否为BITMAP_PAGE_NEEDWRITE,但是这个时候的page不是BITMAP_PAGE_NEEDWRITE,所以进入else的处理,
把页标记为BITMAP_PAGE_NEEDWRITE
if (lastpage != NULL) {
if (test_page_attr(bitmap, lastpage,
BITMAP_PAGE_NEEDWRITE)) {
clear_page_attr(bitmap, lastpage,
BITMAP_PAGE_NEEDWRITE);
spin_unlock_irqrestore(&bitmap->lock, flags);
write_page(bitmap, lastpage, 0);
} else {
set_page_attr(bitmap, lastpage,
BITMAP_PAGE_NEEDWRITE);
bitmap->allclean = 0;
spin_unlock_irqrestore(&bitmap->lock, flags);
}
}
继续执行,bmc为2,会把bmc设置为1,并且再设置一次BITMAP_PAGE_PENDING
if (*bmc) {
if (*bmc == 1 && !bitmap->need_sync) {
/* we can clear the bit */
*bmc = 0;
bitmap_count_page(bitmap,
(sector_t)j << CHUNK_BLOCK_SHIFT(bitmap),
-1);
/* clear the bit */
paddr = kmap_atomic(page, KM_USER0);
if (bitmap->flags & BITMAP_HOSTENDIAN)
clear_bit(file_page_offset(bitmap, j),
paddr);
else
__clear_bit_le(
file_page_offset(bitmap,
j),
paddr);
kunmap_atomic(paddr, KM_USER0);
} else if (*bmc <= 2) {
//进入这里把bmc设置为bmc=1
*bmc = 1; /* maybe clear the bit next time */
set_page_attr(bitmap, page, BITMAP_PAGE_PENDING);
bitmap->allclean = 0;
}
第一次调用结束。
2)第二次进入bitmap_daemon_work,bmc=1,页属性为BITMAP_PAGE_PENDING和BITMAP_PAGE_NEEDWRITE。
这样就会走到下面的流程,把BITMAP_PAGE_PENDING清掉
if (*bmc == 1 && !bitmap->need_sync) {
/* we can clear the bit */
*bmc = 0;
bitmap_count_page(bitmap,
(sector_t)j << CHUNK_BLOCK_SHIFT(bitmap),
-1);
/* clear the bit */
// 这里才是真正的位图文件缓存页bit位清0的地方
paddr = kmap_atomic(page, KM_USER0);
if (bitmap->flags & BITMAP_HOSTENDIAN)
clear_bit(file_page_offset(bitmap, j),
paddr);
else
__clear_bit_le(
file_page_offset(bitmap,
j),
paddr);
kunmap_atomic(paddr, KM_USER0);
}
2)第三次进入bitmap_daemon_work,bmc=1,页属性为BITMAP_PAGE_NEEDWRITE。
会走到下面的流程,清掉BITMAP_PAGE_NEEDWRITE,然后调用write_page刷到磁盘中,至此,清理操作才完成,
总共需要调用三次bitmap_daemon_work才能完成一个bit的清0操作。
if (!test_page_attr(bitmap, page, BITMAP_PAGE_PENDING)) { int need_write = test_page_attr(bitmap, page, BITMAP_PAGE_NEEDWRITE); if (need_write) clear_page_attr(bitmap, page, BITMAP_PAGE_NEEDWRITE);spin_unlock_irqrestore(&bitmap->lock, flags);
if (need_write)
write_page(bitmap, page, 0);
spin_lock_irqsave(&bitmap->lock, flags);
j |= (PAGE_BITS – 1);
continue;
}
这种异步清零的机制好处在于,在还未清零或者内存位图清0但没有刷到磁盘的时候,又有对该页的写请求到来,就只用增加bmc计数器或者只是把内存位图置位,而不用再写到外存的位图文件中,从而减少了一次写外存位图的io。
更多技术交流,请关注我们哦!后续会更新更多的技术文章!