B树操作详解
B树是一颗多路的平衡搜索树,其规定树根至少有两个孩子,每个内部节点有两个或以上的孩子。用来衡量B树规模的一个指标是“最小度数”t,其表示B树所有内部节点的孩子数为t~2t个。
B树的一个结点有两个存储域,分别是关键字和孩子结点,关键字用于划分孩子节点,一个关键字的左右两侧各有一个孩子。类似于二叉搜索树,一个关键字x的左孩子的关键字值都比x小,右孩子的关键字值都比x大。因此,一个结点的关键字的个数是t-1~2t-1个。
下图是一个简单的B树,该树的最小度数t是2。
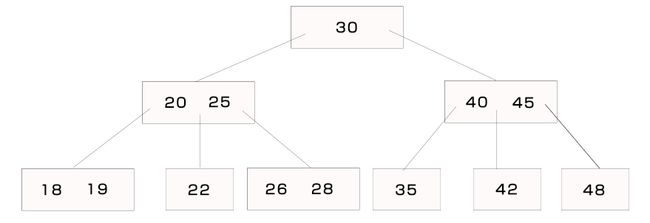
B树有以下性质:
下面给出实际编程时B树以及B树结点的数据结构定义。
typedef struct LinkKey
{
int key;
struct LinkKey *next;
} LinkKey;
typedef struct LinkNode
{
void *node;
struct LinkNode *next;
} LinkNode;
typedef struct BNode
{
int n; // 孩子个数,so key个数为n-1
bool leaf;
LinkKey *key;
LinkNode *children;
struct BNode *parent;
} BNode;
typedef struct BTree
{
BNode *root;
int t; // B树的最小度数
} Btree;
考虑到B树结点中多关键字和多结点的遍历,删除以及插入操作以及其数目的不确定性,为了降低时间和空间复杂度,我们不使用数组对这些数据进行组织,取而代之的是单链表。上述定义中的LinkKey和LinkNode就是存储一个结点的关键字和孩子结点指针的链表数据结构。一个结点的关键字以非递减的顺序存储,结点指针的存储顺序与关键字顺序对应。BNode的leaf属性记录该结点是否为叶子结点(true/false)。
1. B树的插入
B树的插入操作需要先根据要插入的关键字k值找到正确的插入位置,该过程与二叉搜索树的插入类似。从树根出发,遍历当前结点的关键字链表,找到一个前面的关键字比k小,后面的关键字比k大的位置,然后再取出这个位置的孩子指针,继续遍历该孩子结点的关键字。如此往复,直到当前结点为叶子结点时,找到合适的位置将关键字k插入叶子结点的关键字链表中即可。
1.1 单链表操作
该过程主要涉及到的是对单链表的操作,这里不做详细讨论,只给出后续程序中使用到的方法的定义。
/**
* 以下是链表的操作
*/
LinkKey *initLinkKey()
{
LinkKey *head = (LinkKey *)malloc(sizeof(LinkKey));
head->key = INT_MIN;
head->next = NULL;
return head;
}
void destroyLinkKey(LinkKey *link)
{
while (link != NULL)
{
LinkKey *next = link->next;
free(link);
link = next;
}
}
int getKey(LinkKey *link, int which)
{
int i = -1;
while (i < which && link->next != NULL)
{
link = link->next;
i++;
}
if (i == -1) return INT_MIN;
return link->key;
}
void insertLinkKey(LinkKey *link, int key)
{
while (link->next != NULL)
{
if (key <= link->next->key)
{
break;
}
link = link->next;
}
LinkKey *node = (LinkKey *)malloc(sizeof(LinkKey));
node->key = key;
node->next = link->next;
link->next = node;
}
bool deleteLinkKey(LinkKey *link, int key)
{
while (link->next != NULL && key > link->next->key)
{
link = link->next;
}
if (key == link->next->key)
{
link->next = link->next->next;
return true;
}
return false;
}
LinkNode *initLinkNode()
{
LinkNode *head = (LinkNode *)malloc(sizeof(LinkNode));
head->next = NULL;
head->node = NULL;
return head;
}
void destroyLinkNode(LinkNode *link)
{
while (link != NULL)
{
LinkNode *next = link->next;
free(link);
link = next;
}
}
BNode *getLinkNode(LinkNode *link, int which)
{
int i = -1;
while (i < which && link->next != NULL)
{
link = link->next;
i++;
}
if (i == -1) return NULL;
return (BNode*)(link->node);
}
void insertLinkNode(LinkNode *link, BNode *node, int which)
{
int i = 0;
while (i < which && link->next != NULL)
{
link = link->next;
i++;
}
LinkNode *linkNode = (LinkNode *)malloc(sizeof(LinkNode));
linkNode->node = node;
linkNode->next = link->next;
link->next = linkNode;
}
bool deleteLinkNode(LinkNode *link, int which)
{
int i = 0;
while (link->next != NULL && i < which)
{
link = link->next;
i++;
}
if (i == which)
{
link->next = link->next->next;
return true;
}
return false;
}
上述方法涵盖了对LinkKey链表和LinkNode链表的初始化,插入,删除和获取指定值的操作。
1.2 分裂
下面具体讨论在插入操作中会遇到的问题:定义孩子关键字个数为2t-1的结点为满结点,在沿树下降寻找插入位置时,经过满结点时会有两种情况:
情况1. 关键字k有可能会插入到其中,就会导致该结点度数过大,破坏了B树的性质。
情况2. 关键字k有可能插入到满结点的满结点孩子中,然后导致孩子结点度数过大,通过分裂操作(后面介绍)使孩子节点度数降低,但又会导致当前结点度数过大,破坏了B树的性质。
因此,在沿路下降搜索插入位置时,对经过的满结点,均进行分裂操作以消除满结点。
以下图为例介绍分裂操作,该树按关键字S分裂结点得到右图,关键字S从下面的结点移动到了上面的结点中,下面的结点以S为界分裂成了两个结点分别位于S的两侧。
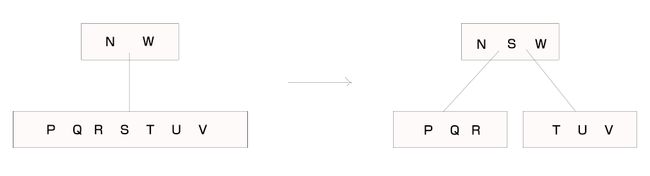
分裂操作使的原来的关键字个数为2t-1的满结点分裂成了两个关键字个数为t-1的结点,其父结点的关键字个数也增加1,这也是上面情况2所叙述的分裂结点会导致满父结点失衡的原因。下面给出分裂操作的程序。
void splitBNode(BNode *parent, int which)
{
int i;
BNode *node = getLinkNode(parent->children, which);
BNode *right = createBNode();
// 配置分裂出来的右结点
right->leaf = node->leaf;
right->n = node->n / 2;
for (i = 0; i < right->n; i++)
{
if (!right->leaf) insertLinkNode(right->children, getLinkNode(node->children, right->n + i), i);
if (i != right->n - 1) insertLinkKey(right->key, getKey(node->key, right->n + i));
}
if (!right->leaf) insertLinkNode(right->children, getLinkNode(node->children, right->n + i), i);
right->parent = parent;
// 原来的node作为左结点
node->n -= right->n;
i = 0;
LinkKey *keys = node->key;
while (i < node->n - 1)
{
keys = keys->next;
i++;
}
int key = keys->next->key;
keys->next = NULL; // 断开与被分裂出去的关键字的联系
// 将key和分裂后的结点插入parent结点
LinkKey *pKeys = parent->key;
LinkNode *pNodes = parent->children;
insertLinkKey(pKeys, key);
insertLinkNode(pNodes, right, which + 1);
parent->n++;
}
splitNode方法分裂指定的parent结点位于which位置的孩子结点。该方法首先访问parent结点的LinkNode链表得到第which个孩子结点node,然后将其分裂成两个结点,并将原来node的中间关键字移到parent结点的关键字链表LinkKey中,再修改node到分裂后的两个结点的指向。
分裂有一个特殊情况:当要分裂的结点是根结点时,需要先用一个空(没有关键字,不是NULL)的结点newRoot指向根结点,然后再对根结点执行分裂操作,最后再将B树的根结点指针指向newRoot。
1.3 沿树单程下行插入关键字
向B树插入关键字的算法流程是,从树根开始,沿着树往下查抄新的关键字所属位置时,分裂沿途遇到的每一个满结点(包括叶子结点),直到找到正确的叶子结点并插入关键字。插入的程序如下。
void insertBTree(BTree *tree, int key)
{
BNode *root = tree->root;
// 新根
if (root == NULL)
{
BNode *newRoot = createBNode();
newRoot->leaf = true;
insertLinkKey(newRoot->key, key);
newRoot->n++;
tree->root = newRoot;
return;
}
// 分裂根
if (root->n == tree->t * 2)
{
BNode *newRoot = createBNode();
newRoot->leaf = false;
newRoot->n = 1;
insertLinkNode(newRoot->children, root, 0);
root->parent = newRoot;
splitBNode(newRoot, 0);
tree->root = newRoot;
}
// 寻找插入路径
BNode *node = tree->root;
while (node->leaf == false)
{
LinkKey *keys = node->key;
int i = 0;
while (keys->next != NULL && key > keys->next->key)
{
keys = keys->next;
i++;
}
BNode *next = getLinkNode(node->children, i);
if (next->n == tree->t * 2)
{
splitBNode(node, i); // 分裂满结点
if (key < getKey(node->key, i))
{
node = next;
}
else
{
node = getLinkNode(node->children, i + 1);
}
}
else
{
node = next;
}
}
// 将key插入叶子结点
LinkKey *pKeys = node->key;
insertLinkKey(pKeys, key);
node->n++;
}
上述insertBTree方法可以用于从零开始构造B树,因为它涵盖了插入空树的情况。
2. 删除关键字
从B树种删除关键字操作前面的过程与二叉搜索树类似,根据要删除的关键字沿树下行找到该关键字所属的结点,然后从该结点的关键字链表中删除之。和插入操作一样,这里也涉及到了结点度的问题。删除关键字会使结点的度降低,如果结点本来只有t-1个关键字,删除关键字后就会破坏其平衡。和插入操作一样,删除操作也是沿树下降搜索的时候,对遇到的每一个关键字个数只有t-1的结点做出处理,直到找到关键字所属的结点为止。该处理是合并结点或者移动关键字,其中,合并结点是分裂结点的逆过程。
下面给出删除操作搜寻关键字所属结点的过程中可能会遇到的情况:
情况1. 如果关键字k在叶子结点x中,则直接删除之;
情况2. 如果关键字在内部结点x中:
2.a 考察关键字k前面的孩子结点y是否至少包含t个关键字,如果是,则找出关键字k在以y为根的子树中的前驱k‘,并用k’代替k,再递归地删除k‘;
2.b 在考察关键字k后面的孩子结点z是否至少包含t个关键字,如果是,则找出关键字k在以z为根的子树中的后驱k‘,并用k’代替k,再递归地删除k‘;
2.c 如果关键字k前后的结点y和z都只有t-1或以下个数的关键字,则合并y和z,再从合并后的结点所在的子树中删除k;
情况3. 如果关键字k不在当前结点中,则考虑该结点中包含k的孩子结点c,如果孩子结点c的关键字个数只有t-1,那么则执行3.a或者3.b操作,然后再继续搜寻包含k的结点:
3.a 如果结点c的前一个结点或者后一个结点(均称为结点z)的关键字个数都大于t-1个,则从结点x中移动一个关键字到c中,再从结点z中移动一个关键字到x中,这样x的关键字个数不变,c的关键字个数变为t,z的关键字个数也知道有t-1个,B树的平衡不被破坏;
3.b 如果结点c的前后结点都只有t-1个关键字,那么就选择一个结点与结点c合并。
上述操作其实都是在保证删除操作在B树下降搜寻关键字k所属结点的过程中,所经过的结点均能满足在删除关键字或者子结点合并操作后仍然能够保持B树性质的要求。执行上述操作,在最后,关键字看都会落在叶子结点中,然后就可以直接删除之。
下面给出合并结点的程序。
void unionBNodes(BNode *parent, int a, int b)
{
int middleKey = getKey(parent->key, a);
BNode *aNode = getLinkNode(parent->children, a);
BNode *bNode = getLinkNode(parent->children, b);
LinkKey *aKey = aNode->key;
LinkKey *bKey = bNode->key;
LinkNode *aNodes = aNode->children;
LinkNode *bNodes = bNode->children;
while (aKey->next != NULL) aKey = aKey->next;
LinkKey *middle = (LinkKey *)malloc(sizeof(LinkKey));
middle->key = middleKey;
aKey->next = middle;
middle->next = bKey->next;
free(bKey);
while (aNodes->next != NULL) aNodes = aNodes->next;
aNodes->next = bNodes->next;
free(bNodes);
aNode->n += bNode->n;
deleteLinkKey(parent->key, middleKey);
deleteLinkNode(parent->children, b);
parent->n--;
}
unionNodes方法将parent结点中第a个和第b个结点合并成一个新的结点,a和b必须是相邻的。
下面给出针对情况3.a的移动关键字的操作的方法moveKey。
void moveKey(BNode *parent, int from, int to)
{
BNode *f = getLinkNode(parent->children, from);
BNode *t = getLinkNode(parent->children, to);
if (from < to)
{
LinkKey *pLink = parent->key;
int i = -1;
while (i < from && pLink->next != NULL)
{
pLink = pLink->next;
i++;
}
insertLinkKey(t->key, pLink->key);
LinkKey *fLink = f->key;
while (fLink->next->next != NULL) fLink = fLink->next;
pLink->key = fLink->next->key;
free(fLink->next);
fLink->next = NULL;
f->n--;
LinkNode *fNodes = f->children;
while (fNodes->next->next != NULL) fNodes = fNodes->next;
insertLinkNode(t->children, (BNode*)(fNodes->next->node), 0);
free(fNodes->next);
fNodes->next = NULL;
}
else if (from > to)
{
LinkKey *pLink = parent->key;
int i = -1;
while (i < to && pLink->next != NULL)
{
pLink = pLink->next;
i++;
}
insertLinkKey(t->key, pLink->key);
t->n++;
LinkKey *fLink = f->key;
pLink->key = fLink->next->key;
LinkKey *nextKey = fLink->next;
fLink->next = fLink->next->next;
free(nextKey);
f->n--;
LinkNode *fNodes = f->children;
insertLinkNode(t->children, (BNode*)(fNodes->next->node), t->n);
LinkNode *nextNode = fNodes->next;
fNodes->next = fNodes->next->next;
free(nextNode);
}
}
moveKey方法将parent结点的第from个结点的某一个关键字移动到parent结点上,将parent结点的某一个关键字移动到第同个结点上。这些操作都是基于单链表实现的。
下面给出辅助获取一个关键字的前驱和后驱的方法。
int getMinKey(BNode *tree)
{
while (!tree->leaf)
{
LinkNode *link = tree->children;
tree = (BNode *)(link->next->node);
}
return tree->key->next->key;
}
int getMaxKey(BNode *tree)
{
while (!tree->leaf)
{
LinkNode *link = tree->children;
while (link->next != NULL) link = link->next;
tree = (BNode *)(link->next->node);
}
LinkKey *key = tree->key;
while (key->next != NULL) key = key->next;
return key->key;
}
getMinKey和getMaxKey方法分别获取指定B树的最小关键之和最大关键值,这两个方法的编写依赖与B树遍历的知识,以及二叉搜索树中前驱后驱的概念,不了解的可以先去查看一下我之前的博客 二叉搜索树基于以上方法,编写一个实现B树删除关键字操作的程序 如下。
void deleteFromBTree(BTree *tree, int key)
{
BNode *node = tree->root;
if (node == NULL) return;
while (!node->leaf)
{
LinkKey *keys = node->key;
// 寻找匹配key的node
int which = 0;
while (keys->next != NULL && key > keys->next->key)
{
which++;
keys = keys->next;
}
BNode *next = getLinkNode(node->children, which);
if (key == keys->next->key)
{
// 当key匹配到当前结点
if (next->n > tree->t)
{
// 情况2.a
keys->next->key = getMaxKey(next);
key = keys->next->key; // 从next结点开始删除新key
}
else
{
next = getLinkNode(node->children, which + 1);
if (next->n > tree->t)
{
// 情况2.b
keys->next->key = getMinKey(next);
key = keys->next->key; // 从next结点开始删除新key
}
else
{
// 情况2.c
unionBNodes(node, which, which + 1);
next = getLinkNode(node->children, which);
}
}
}
else
{
// 当key在子树中,且子树的度数不合要求
if (next->n <= tree->t)
{
BNode *left = getLinkNode(node->children, which - 1);
BNode *right = getLinkNode(node->children, which + 1);
if (left != NULL && left->n > tree->t)
{
// 情况3.a
moveKey(node, which - 1, which); // 从左子树移动key
}
else if (right != NULL && right->n > tree->t)
{
// 情况3.a
moveKey(node, which + 1, which); // 从右子树移动key
}
else
{
// 情况3.b
unionBNodes(node, which, which + 1); // 与右子树合并
}
}
}
node = next;
}
// 情况1
LinkKey *keys = node->key;
if (deleteLinkKey(keys, key))
{
node->n--;
}
}deleteFromBTree方法在当前结点不是叶子结点的时候循环工作,依次判断情况1~3并执行相应操作。该方法针对情况2.a和2.b没有使用递归实现,而是使用了循环。
BTree实现的完整代码可以参考我的github项目 数据结构与算法
该项目中包含了我的博客中已经介绍过的以及即将要介绍的数据结构与算法的C语言实现,由于我的算法之路还很漫长,所以该项目将会持续更新哦~