用WebCollector制作一个爬取《知乎》并进行问题精准抽取的爬虫(JAVA)
简介:
WebCollector是一个无须配置、便于二次开发的JAVA爬虫框架(内核),它提供精简的的API,只需少量代码即可实现一个功能强大的爬虫。
如何将WebCollector导入项目请看下面这个教程:
JAVA网络爬虫WebCollector深度解析——爬虫内核
参数:
WebCollector无需繁琐配置,只要在代码中给出下面几个必要参数,即可启动爬虫:
1.种子(必要):
种子即爬虫的起始页面。一个爬虫可添加一个或多个种子。
2.正则(可选):
正则是约束爬取范围的一些正则式。正则不一定要给出。如果用户没有给出正则,系统会自动将爬取范围限定在种子的域名内。
3.线程数(可选):
WebCollector是一个多线程的爬虫,默认使用10个线程同时工作。开发者可以自定义线程数。
需求:
简述一下教程里代码的功能:定制一个爬虫,对“知乎”网站进行爬取,不要求下载所有的网页和文件,而是要求对知乎中所有的“提问”页面中的”问题“进行提取。如图:
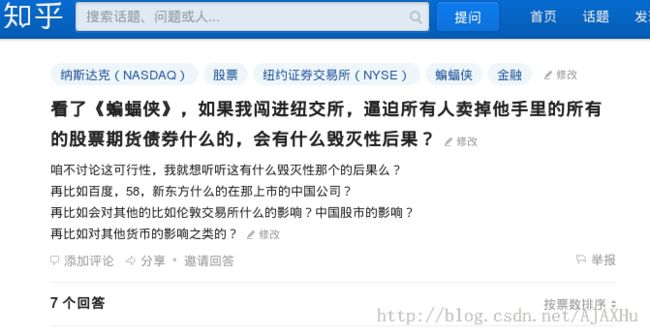
我们需要提取问题标题:“看了《蝙蝠侠》,如果我闯进纽交所,逼迫所有人卖掉他手里的所有的股票期货债券什么的,会有什么毁灭性后果?",
以及问题的内容:“咱不讨论这可行性,我就想听听这有什么毁灭性那个的后果么?再比如百度,58,新东方什么的在那上市的中国公司?再比如会对其他的比如伦敦交易所什么的影响?中国股市的影响?再比如对其他货币的影响之类的?“
代码:
代码分为两部分,爬取器和控制器。
爬取器通过Override父类中的visit方法(即对每个正在爬取的页面需要进行的操作),来定制自己的爬取任务。
控制器通过给爬取器设置参数(上面所说的种子、正则、线程数),启动爬取器来完成控制功能。
1.爬取器:
WebCollector中集成了多种爬取器(主要是遍历算法不同),最常用的遍历器是BreadthCrawler,它是基于广度遍历的算法进行爬取的。我们新建一个JAVA类ZhihuCrawler,继承BreadthCrawler,来定制我们的爬取器。
- public class ZhihuCrawler extends BreadthCrawler{
- /*visit函数定制访问每个页面时所需进行的操作*/
- @Override
- public void visit(Page page) {
- String question_regex="^http://www.zhihu.com/question/[0-9]+";
- if(Pattern.matches(question_regex, page.getUrl())){
- System.out.println("正在抽取"+page.getUrl());
- /*抽取标题*/
- String title=page.getDoc().title();
- System.out.println(title);
- /*抽取提问内容*/
- String question=page.getDoc().select("div[id=zh-question-detail]").text();
- System.out.println(question);
- }
- }
代码解析:
《知乎》中有很多种网页:提问网页、用户个人信息网页、专页。我们现在只要对提问网页进行操作。
提问网页的URL一般如下:http://www.zhihu.com/question/21962447
question_regex是所有提问网页的正则表达式,代码中:
- if(Pattern.matches(question_regex, page.getUrl())){
- //操作代码
- }
保证我们只对“提问”页面进行抽取。
visit函数的参数Page page,是一个已经爬取并解析成DOM树的页面。Page的参数:
page.getUrl() returns the url of the downloaded page
page.getContent() returns the origin data of the page
page.getDoc() returns an instance of org.jsoup.nodes.Document
page.getResponse() returns the http response of the page
page.getFetchTime() returns the time this page be fetched at generated by System.currentTimeMillis()
特别要注意的是page.getDoc()(DOM树),这里的page.getDoc()是JSOUP的Document,如果需要做HTML解析、抽取,使用page.getDoc()是不二的选择,关于jsoup的使用方法,可参考JSOUP的教程:
http://www.brieftools.info/document/jsoup/
ZhihuCrawler中用到了page.getUrl()和page.getDoc()。
我们可以发现,《知乎》提问页面的网页标题就是问题的标题,所以通过:
- String title=page.getDoc().title();
抽取《知乎》提问页面的提问内容,需要从HTML源码观察规则:
- <div data-action="/question/detail" data-resourceid="965792" class="zm-item-rich-text" id="zh-question-detail">
- <div class="zm-editable-content">咱不讨论这可行性,我就想听听这有什么毁灭性那个的后果么?<br>
- 再比如百度,58,新东方什么的在那上市的中国公司?<br>
- 再比如会对其他的比如伦敦交易所什么的影响?中国股市的影响?<br>再比如对其他货币的影响之类的?
- </div>
- </div>
对于《知乎》所有的提问界面,我们发现,提问内容都被放在一个id="zh-question-detail"的div中,这是JSOUP最适合适用的一种情况。我们只要找到这个div,将其中的文本(text)取出即可:
- String question=page.getDoc().select("div[id=zh-question-detail]").text();
2.控制器:
我们需要一个控制器来启动爬取器:
- public class Controller {
- public static void main(String[] args) throws IOException{
- ZhihuCrawler crawler=new ZhihuCrawler();
- crawler.addSeed("http://www.zhihu.com/question/21003086");
- crawler.addRegex("http://www.zhihu.com/.*");
- crawler.start(5);
- }
- }
首先实例化刚定义的ZhihuCrawler(爬取器)。
给爬取器一个种子:http://www.zhihu.com/question/21003086
crawler.start(5)并不是表示开启5个线程爬取,5表示爬取的深度(广度遍历的层数)。
运行Controller这个类,会发现不断有输出产生,但是输出比较杂乱,这是因为我们不仅输出了我们抽取的提问,还输出了爬虫的日志(爬取记录等):
- fetch:http://www.zhihu.com/people/lxjts
- fetch:http://www.zhihu.com/question/24597698
- 正在抽取http://www.zhihu.com/question/24597698
- 小米4采用304不锈钢除了提升质感和B格,还有其他的实际好处么? - 知乎
- 信号会不会跟ip4一样悲剧了……
- fetch:http://www.zhihu.com/topic/20006139
- fetch:http://www.zhihu.com/topic/19559450
- fetch:http://www.zhihu.com/question/20014415#
- fetch:http://www.zhihu.com/collection/31102864
- fetch:http://www.zhihu.com/topic/19663238
- fetch:http://www.zhihu.com/collection/20021567
"fetch:http://www.zhihu.com/question/24597698"是日志的输出,表示一个已经爬取的网页。
如果您想看到干净的爬取结果,有下面几种解决方案:
1.在ZhihuCrawler的visit方法里,添加代码,将title和question字符串输出到文件中。
2.在ZhihuCrawler的visit方法里,添加代码,将title和question字符串提交到数据库(推荐)。
可能有人会疑问,为什么我们给爬虫添加种子的时候不添加《知乎》的首页,这是因为《知乎》首页在不登录的情况下会默认返回登录页面。