加快页面加载速度的解决方案-asp.net使用httphandler打包多CSS或JS文件
介绍
使用许多小得JS、CSS文件代替一个庞大的JS或CSS文件来让代码获得更好的可维护性,这是一个很好的实践。但这样做反过来却损失了网站的性能。虽然你应该将你的Javascript代码写在小文件中并且将大的CSS文件分割到小文件中,当一个浏览器请求那些JS以及CSS文件,它却将为每一个文件产生一个请求。每一个HTTP请求将导致从你的浏览器到服务器上的一次“往返”,从响应服务器到客户端浏览器之间的等待时间称之为“延时”。因此,如果你有四个JS文件以及三个CSS文件需要被页面加载,你将要等待七次网络上的“往返”。在本国内,延时平均为70ms。所以总延时为490ms,大概半秒钟。而来自国外的访问,平均延时大概在200ms左右。因此,那意味着1400ms的时间浪费。而直到CSS与JS文件被完全加载,页面才会被完全地显示出来。所以,越长时间的延时,页面加载地越慢。
延时有多糟糕
这里有一张图片显示了,每一个请求怎样产生了“延时”,这些“延时”累加起来显著地影响了页面的加载:
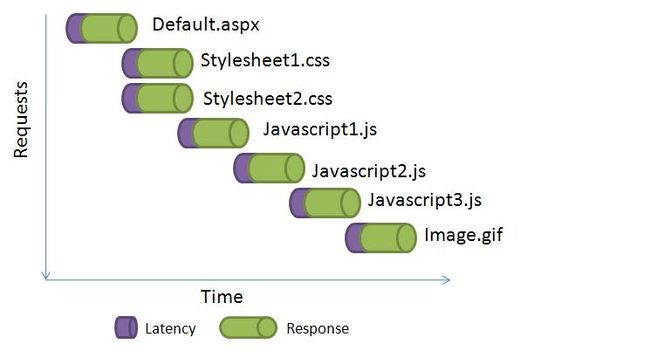
你可以通过使用CDN(Content Delivery Network)来减少等待时间。然而,一个更好的解决方案是使用HttpHandler提供多个文件的一次请求,该HttpHandler整合了数个文件并且提供了一次输出。所以,代之以许多的<scropt>或者<link>标签,你只需要写一个<scropt>以及<link>标签,并将它们标记在HttpHandler中。由你来告诉handler哪些文件需要被整合,并且它提供了哪些文件的一次输出。这省去了从浏览器发出许多请求产生的延时。
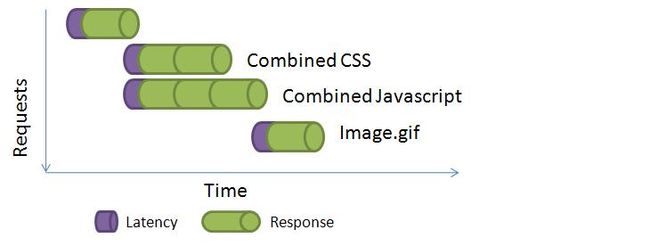
这里你能看到如果你把多个JS文件以及CSS文件整合到一个输出里,有怎样的性能提升。
在通常的网页中,你将看到很多的JS引用:
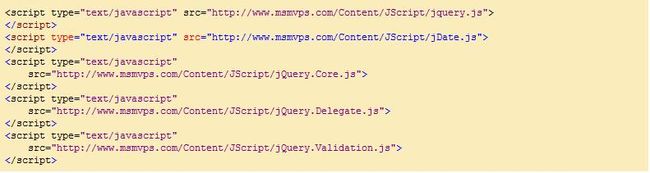
而我们可以仅用一个<script>标签请求整个JS文件的集合,来代替这里的每一个<script>标签:

HttpHandler读取定义在一个配置文件中的文件名,整合所有的那些文件,并将它们一次响应到客户端。它通过gzip来压缩响应内容以此节约带宽。另外它提供一个带有cache的响应请求头来缓存响应到浏览器的Cache里,使得浏览器对之后的访问不需要再次请求它。
在请求参数中,你可以用“S”参数标识文件集合的名称,然后用“t”参数来标识content type,然后使用“v”参数来标识一个版本。因为响应被缓存了,如果你修改了文件集合中的任何一个,你将不得不增加参数“v”的值来让浏览器再次下载响应。
使用该HttpHandler,你可以这样来请求CSS文件: ![]()
这里列出了你将需要怎样来定义请求的集合,在web.config中:

使用HttpHandler整合器的例子
我构建了一个简单的测试网站来向你展示它的使用,该测试网站有两个CSS以及JS文件。Default.aspx仅使用一个<link>和<script>标签通过HttpCombiner.ashx来请求它们。

下面是Default.aspx文件的内容:
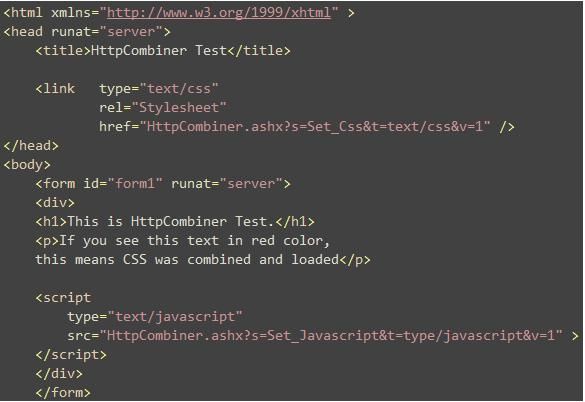
就像你看到的那样,有一个<link>标签向HttpCombiner.ashx发送了一个请求并提供了请求集合的名称——Set_Css,当然还有一个<script>标签请求了一个Set_Javascript的集合。
上面的两个集合都被定义在web.config文件中:

这里列出了Handler如何工作:
(1) 首先,它会从“s”参数中读取文件集合的名称
(2) 然后它从web.config文件中拿到集合的定义
(3) 它读取每一个文件,然后将它们缓存在缓冲区中
(4) 缓冲区然后通过gzip进行压缩
(5) 被压缩后的缓冲区内的内容将被发送到浏览器
(6) 被压缩后的缓冲区内的内容被存储在ASP.NET缓冲中,以让随后的对相同集合的请求能够直接地从Cache中获取数据,而不是从文件系统或外部的URL去读取每一个文件。
Handler带来的好处:
(1) 它减少了网络上的“往返”次数,你把越多的文件放到一个集合中,就越能减少网络延时,它提高了性能。
(2) 它缓存了所有的整合过的压缩响应,因此省去了一次又一次的读取文件系统并压缩它。它提供了可扩展性。
HttpHandler如何工作
首先handler从请求字符串中读取集合名、类型以及版本:

如果要加载的文件集合已经被缓存了,那将直接从cache中写入响应流。否则,文件将被一个接一个地加载,然后被存储在一个MemoryStream。MemoryStream被通过GzipStream压缩(如果浏览器支持压缩输出)。
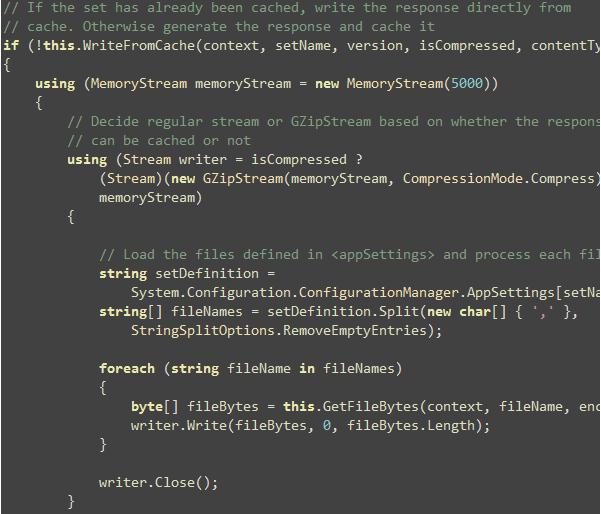
在整合了所有的文件并压缩后,被整合的字节流被缓存起来,以让随后的请求可以直接地从缓存获取数据。
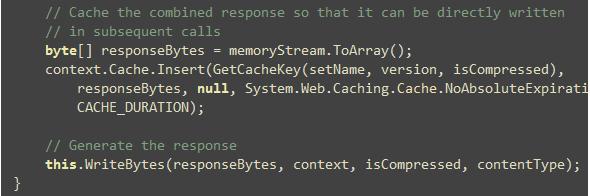
GetFileBytes方法读取一个文件或者URL,然后返回字节。所以,你可以在你的网站里使用虚拟路径,或者你可以使用URL指向一个宿主在另外的域中的Js/Css文件。
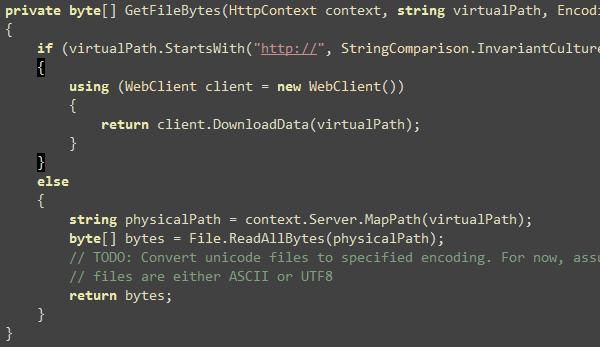
WriteBytes方法有许多技巧在里面。它提供了一个基于是否字节是压缩格式的响应头。然后它提供了一个缓存标识头,让浏览器缓存响应内容。
怎样使用这个handler呢?
- 包含HttpCombiner.ashx在你的项目中
- 定义文件集合在你的web.config配置文件的<appSettings>节点中
- 改变的<link>与<script>标签,使用HttpCombiner.ashx需要的格式:HttpCombiner.ashx?s=<setName>&t=<contentType>&v=<versionNo>
译者注:今天在尝试使用该技术时,遇到一个问题。那就是在打包压缩CSS文件时。如果文件中涉及到图片路径(例如background-img的url属性时)。无法正确请求图片。原因是,通常这些图片都使用的是相对路径。浏览器通常情况下载获取到CSS文件后,会以CSS文件本身作为参考,根据图片的相对路径来查找图片。而批量打包时,用来参考的路径本身变成了handler的路径,因而会导致查找图片的路径出错而无法下载。其实就算是人为将图片的路径设置成相对于本handler的相对路径仍然无法下载!
解决方案:采用绝对路径,但也取决于网站的发布方式。如果发布时新建的网站,那么可以直接通过"/"来从根目录开始表达CSS中的背景图片的绝对路径。因为新建网站时,可以直接用“/”来标识根目录。而新建虚拟目录时,则需要加入新建虚拟目录的文件夹名。如myweb,则绝对路径表示为"/myweb/images......."这样才能正确地获取图片。
转自:http://blog.csdn.net/yanghua_kobe/article/details/6840739