Oracle学习笔记(未完待续)
前言
一个好的技术只能决定你的开始,不能决定你的以后。
技术+项目管理+CMM+心理学+会计+金融。
第一年:做2~4个项目,第二年:编写一些文档(离项目经理不远了),第三年:有一定的管理能力的话就成为经理了,开始进行一些业务上的设计。
1、大型数据库DB2(只限制于IBM的产品),oracle。
2、Oracle 8/8i:i表示的是internet,意味着oracle开始向网络发展,但是这个版本属于过渡版本。
3、Oracle 9i:是现在使用最广泛地版本,是Oracle的升级版,共3CD。
4、Oracle 10g:是一个过渡性的产品,g表示的网格就算,700M。
5、Oracle 11g:是一个完整性的产品,1.8G。
6、安装时,关掉防火墙和网络!
7、全局数据库名我设的为orcl,SID为orcl
8、密码是oracleadmin
9、主要有四个用户:
超级管理员:sys/change_on_install
普通管理员:system/manager
普通用户:scott/tiger(scott是oracle创始人之人,他有一只叫做“tiger”的猫)
大数据用户:sh/sh
10、在安装过程过,一定要选上“创建带样本方案的数据库”,则以后不会出现大数据用户(实验用)。
11、最好将 oracle服务改成手工服务,否则启动电脑速度变慢。
12、有两个重要的服务:
监听服务: OracleOraDb10g_home1TNSListener
如果有程序要操作数据库,或者是一些远程的客户端要连接数据库则必须启动此服务;
数据库的实例服务:OracleServiceORCL
保存数据库的具体信息的服务,每一个数据库都有一个数据库实例(服务)。
命名规则:OracleServiceXXX,XXX是配置的数据库名称(严格来讲是SID名称)。
13、卸载:
a.直接运行卸载程序
b.删除硬盘上的残留文件,如果删除不掉则先进入到安全模式下删除;
c.同时删除注册表中所有与Oracle有关的配置项;
如果没有正常的安装成功,则必须进行卸载,直接用b和c就可以完成卸载。
14、Oracle监听服务经常出现的错误
错误一:注册表使用了优化软件被删除了相关项
对于每一个系统服务实际上都会在注册表中有所保存;
运行-> regedit->进入注册表编辑器。搜索OracleOraDb10g_home1TNSListener,右击->复制项名称-》得到监听注册项“HKEY_LOCAL_MACHINE\SYSTEM\ControlSet002\Services\OracleOraDb10g_home1TNSListener”
里面有一个“ImagePath”的选项,这个选项有可能会在使用优化软件的时候被自动的删除,如果被删除的话则应该建立一个新的项。名称为“ImagePath”,数值数据为“D:\oracle\product\10.2.0\db_1\BIN\TNSLSNR”,BIN里Oracle的可执行程序,TNSLSNR是监听的启动程序。 TNSLSNR.exe 也可能是恶意软件所伪装,尤其是当它们存在于 c:\windows 或 c:\windows\system32 目录,所以优化器有可能把它优化掉!!!
错误二:网络环境的改变
在Oracle 10g里面,如果网络的环境改变了,有可能原始的网络就无法正常工作,此时就必须手工进行网络配置的修改。网络环境的改变最多就是电脑名称的修改。这个问题11g版本可以自动进行重新配置,但是10g或者以前的版本,只能手工修改。否则监听服务无法正常启动,因为网络环境发生改变了。必须修改网络配置文件:
配置文件路径:D:\oracle\product\10.2.0\db_1\NETWORK\ADMIN
有两个配置文件:listener.ora和tnsnames.ora(可以用记事本打开),把两个文件里的HOST的值改为修改过的计算机名称,之后再重新启动监听服务。但是以后如果使用程序连接Oracle 10g的话,则以上的配置有可能还是不能正常访问数据库,此时可以进入到第二步操作,进行数据库名称的注册,配置和移动工具-》Net Manager,-》监听程序-》LISTENER-》数据库服务。按照图1.保存。
保存以后则在listener.ora中多出下列:
(SID_DESC =
(GLOBAL_DBNAME = orcl)
(SID_NAME = ORCL)
)
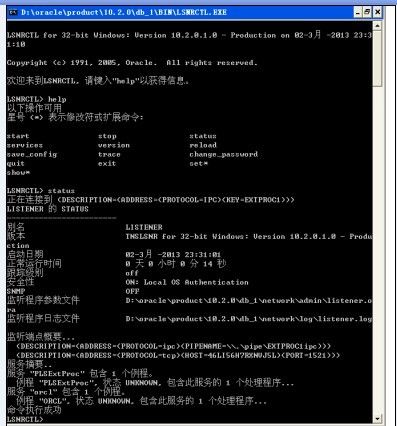
在BIN在也有一个监听状态的的检查命令LSNRCTL.EXE
打开后运行如图2
15、对于Oracle数据库操作主要使用命令行方式,而所有的命令都使用sqlplus完成,sqlplus有两种形式:
a:dos风格,sqlplus.exe
b:windows风格,sqlplusw.exe
直接在“运行”中敲入“sqlpus”进入dos,“sqlplusw”进入window。
在sqlplus中会有折行、折页问题,在sqlplus中也有折行、折页问题,但是可以调整,所以sqlplusw用得较多。
“主机字符串”为空时表示找到默认的实例(orcl数据库),如果这里有多个数据库的话,这里就写上数据库的名称。
16、sqlplusw.exe也有折行,和折页的问题
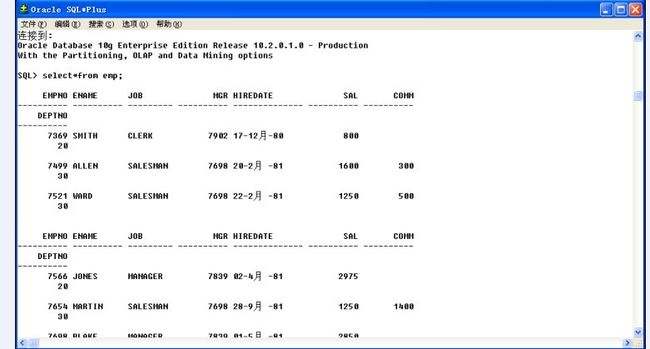
但是可以通过两个格式化命令进行调整:
a.设置每行显示的记录长度:set linesize 300;
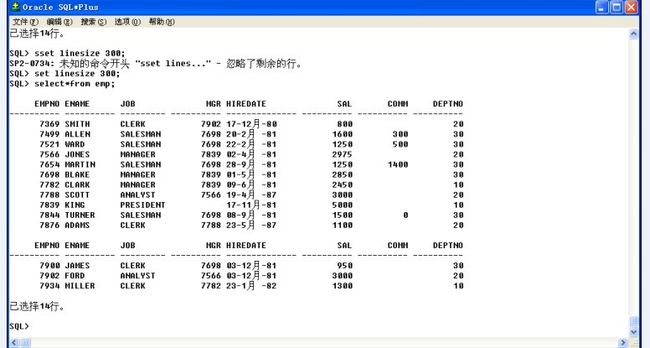
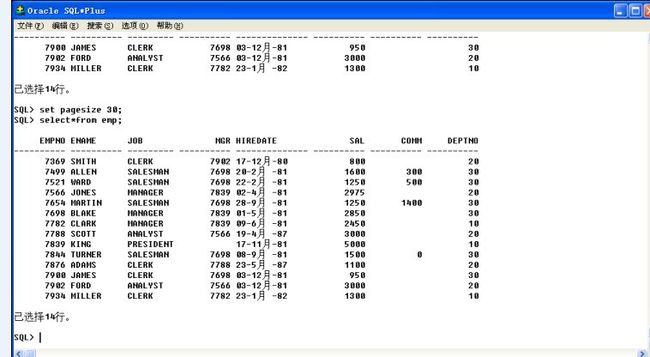
但是有折页(有两行字段名),默认打印13行,
b.设置每页显示的记录长度:set pagesize 30;
虽然sqlplusw显示上方便一些,可是对于命令的编辑上却不是很方便。如果正常的操作,命令写错了,则肯定能使用方向键移到错误的位置上进行修改。但是在sqlplusw中,方向键只能控制屏幕的移动。所以在sqlplusw中提供了ed和@指令(在sqlplus中也可以使用),可以进行记事本的调用和执行。
a.使用ed,调用记事本程序。
在命令行输入ed a,则会弹出
选择是, 但是使用ed打开记事本之后,sqlplusw窗口会进入到阻塞状态,无法使用。
b.使用@执行:@a。
但是在winidows中,由于提供了许多的方便的编辑软件,所以一般会在外部编辑程序,例如,在D盘上建立一个demo.txt的文件,里面有sql语句。要读取键盘上的文件,则必须写上完整的路径:@D:\demo.txt。而且如果这个文件的后缀是*.sql,则不用输入文件后缀(demo.sql),输入:@d:\demo或者@d:demo。
我个人的爱好是:在编辑软件中写sql,复制、粘贴就行了。
17、sqlplus中set linesize 300无效(因为dos窗口的宽度不变),set pagesize 30有效(长度可变)。
18、
在一个数据库中,会有许多的用户(现在已知的是四个用户),这每一个用户下都会有多张自己的数据表,所以要想查看所有的数据表,则可以使用如下的命令:
select* from tab;
19、
show user用于显示当前的登录用户。
20、
直接进行用户的登录切换
conn 用户名/密码[as sysdba/sysoper] 例如:conn sys/change_on_install as sysdba;
“[]”,为可选的,sysoper为普通操作者。
但是,一旦使用了sys连接之后,则无法直接查询emp表数据。 对于每张表,都有其属于的用户,所以一张表的完整名称是“用户名.表名称”或者说是“模式名.表名”。所以要想访问其他用户的表,应该加上用户名,如:select*from scott.emp。
21、
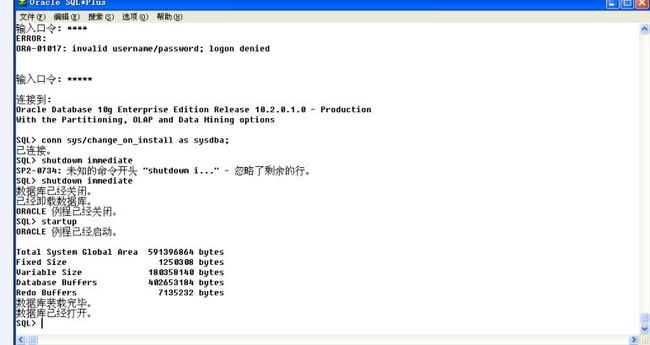
但是一旦使用了超级管理员登陆的话 ,可以通过手工的控制数据库实例的打开和关闭,
a.关闭数据库实例命令:shutdown immediate
一旦关闭以后用户无法直接连接到数据库,
ERROR:
ORA-01034: ORACLE not available
ORA-27101: shared memory realm does not exist
此时可以在sqlplusw中,先使用“/nolog”登录,之后使用管理员登录,conn sys/change_on_install as sysdba,然后启动数据库实例“startup”。
22、
sqlplusw也可以调用操作系统命令,使用“host”作为前缀。例如:host copy d:\demo.sql d:\hello.txt。
23、
查看所有表名称
select*from tab;
24、
查看表结构
desc 表名称
25、
number(2):由两位数字组成;
varchar2(14):最多由14个字符组成;
date:日期类型
number(7,2):两位小数,五位整数,共7位
number:数字
26、
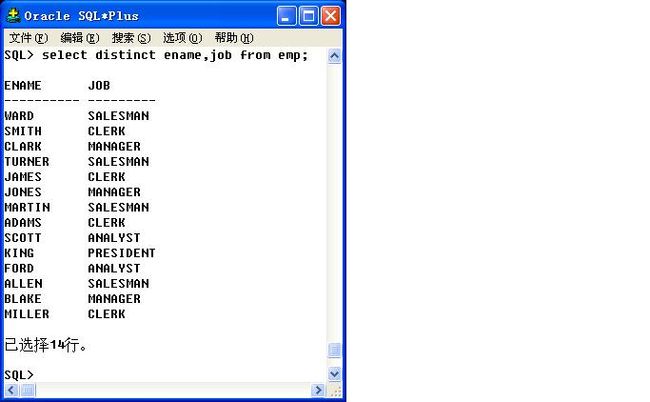
重复数据:指的是一行中的每列的记录都重复,才叫重复数据。
select distinct ename,job from emp;
27、
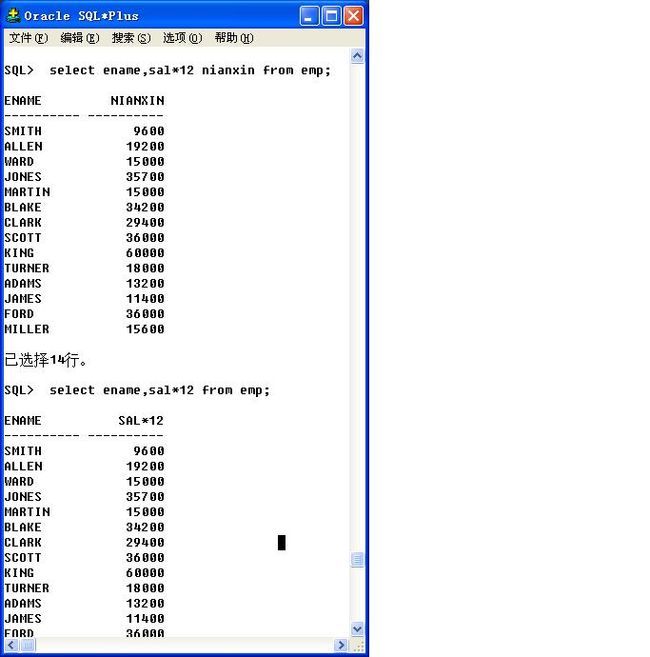
改变列的名字:
select ename,sal*12 nianxin from emp;
28、
四则运算
select ename,(sal+200)*12+300 nianxin from emp;
29、
使用“||”连接查询的字段
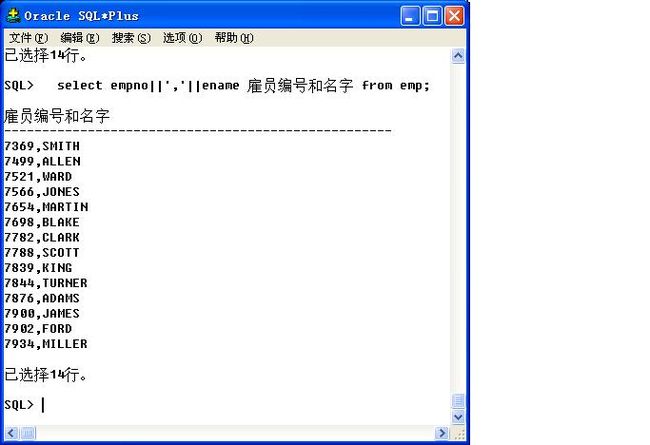
select empno||','||ename from emp;
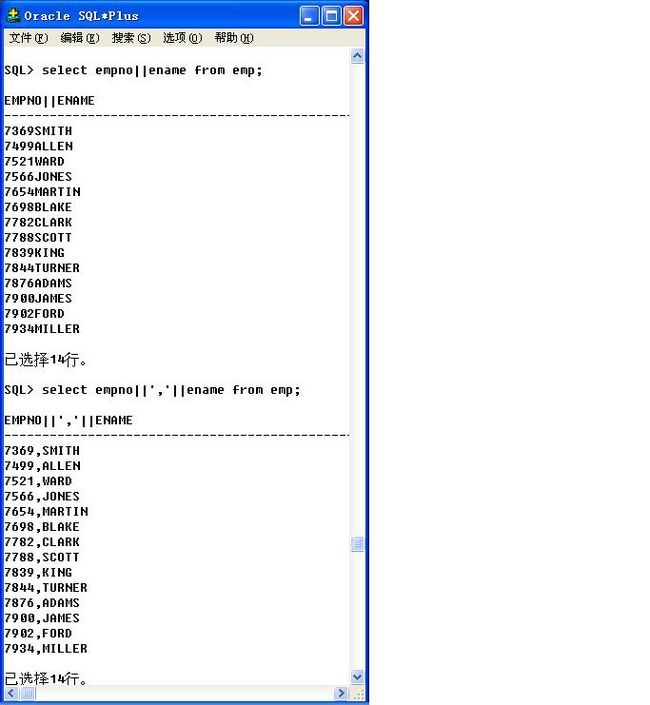
由于“,”属于原样输出的字符串,所以必须使用单引号括起来,在sql语句中,单引号表示字符串。
加上表头“雇员编号和名字”
select empno||','||ename 雇员编号和名字 from emp;
30、
“||”举例
select '雇员编号是:'||empno||'的名字是'||ename||'基本工资是:'||sal||',职位是'||job||'。' 雇员信息 from emp;
加上表头“雇员信息”
31、
select*from emp where (job='CLERK' or job='SALESMAN') and sal>1200;
32、
下面的效果是一样的
select*from emp where job<>'CLERK';
select*from emp where job!='CLERK';
select*from emp where not job='CLERK';
33、
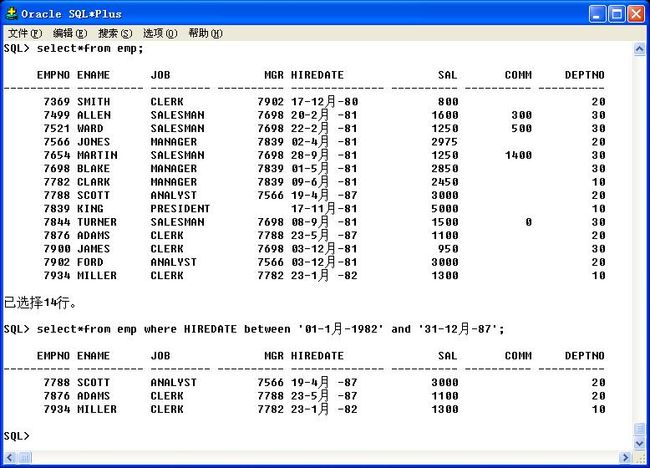
between and 也对日期起作用
select*from emp where HIREDATE between '01-1月-1982' and '31-12月-87';
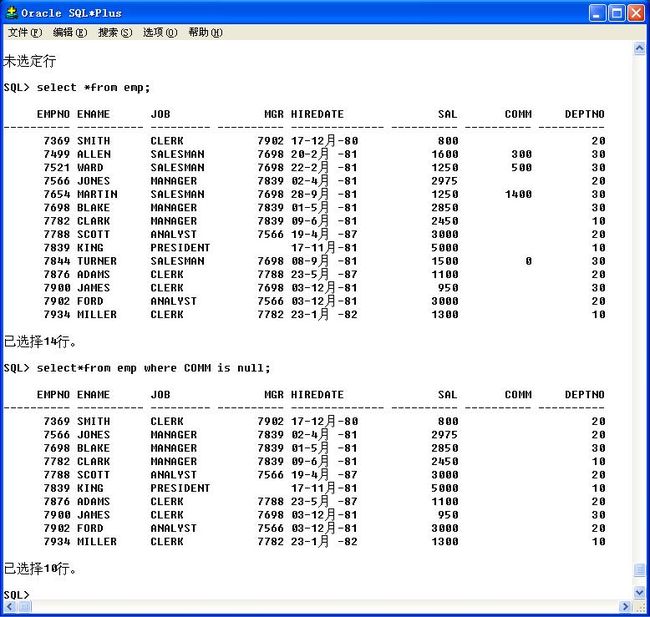
34、
只要列值中没有任何形式的值就是null。
35、
关于not in的问题
a.正常情况下
select*from emp where empno in(7369,7566,null);
如果在in操作符中使用了null,则不会影响查询。
b.not in
select*from emp where empno not in(7369,7566,null);
不会有任何的查询结果返回!,以后会讲解为什么not in 中不能出现null,而且:如果not in中出现了null就表示的是查询全部数据。
36、
模糊查询
a.
select*from emp where ename like '%A%';
查出带有字母“A”的雇员。
b.%%
在使用like子句的时候有一个最大的注意点:如果不设置任何关键字的话('%%')则表示查询全部记录:
这个特点可以节约很多的代码,一定要记住!!!
37、
order by一定是放在where之后.
升序asc(默认),降序desc。
下面效果是一样的:
select*from emp order by sal;
select*from emp order by sal asc;
38、
按照工资由高到低,如果工资相同,则按照雇佣日期由早到晚排序:
select*from emp order by sal desc,hiredate asc;
39、
每种数据库系统都有自己的操作函数,即单行函数;
单行函数主要分为以下五类:字符函数、数字函数、日期函数、转换函数、通用函数;
40、
字符函数主要进行字符串数据的操作:
upper(字符串|列):变为大写;
lower(字符串|列):变为小写;
initcap(字符串|列):开头首字母大写;
length(字符串|列):求出长度;
replace(字符串|列):替换;
substr(字符串|列,开始点[结束点]):字符串截取;
41、
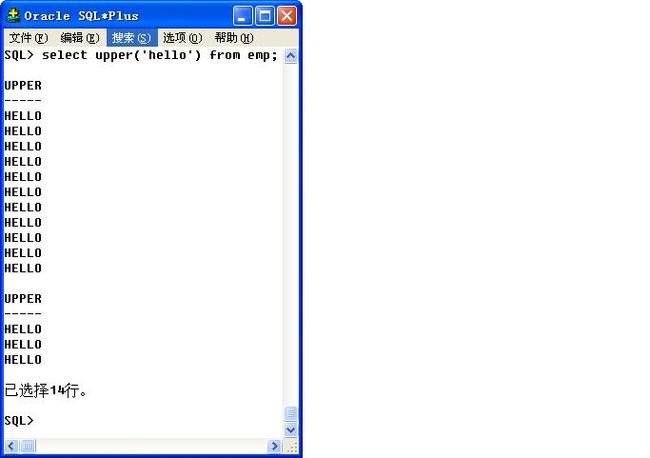
由上图可知,因为emp有14行,所有会多出13行无用的,所以Oracle数据库为了使用户查询方便,专门提供了一个“dual”的虚拟表。
42、
上图中,upper会把输入的的值变成大写的。&有代替变量的作用,&后边的x值可以是任意的。
43、
select ename,length(ename) from emp where length(ename)=4;
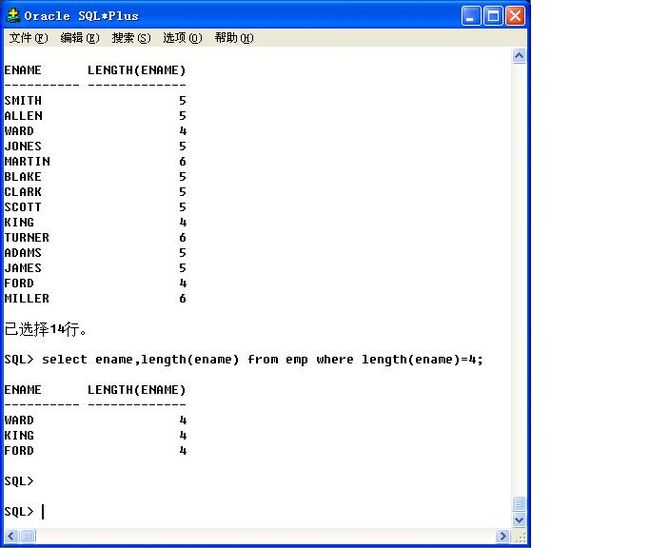
44、
select replace(ename,'A','________') 改变后名字 from emp;

45、
字符串截取操作有两种语法:
语法一:substr(字符串|列,开始点),表示从开始点一直截取到结尾;
语法二:substr(字符串|列,开始点,结束点);
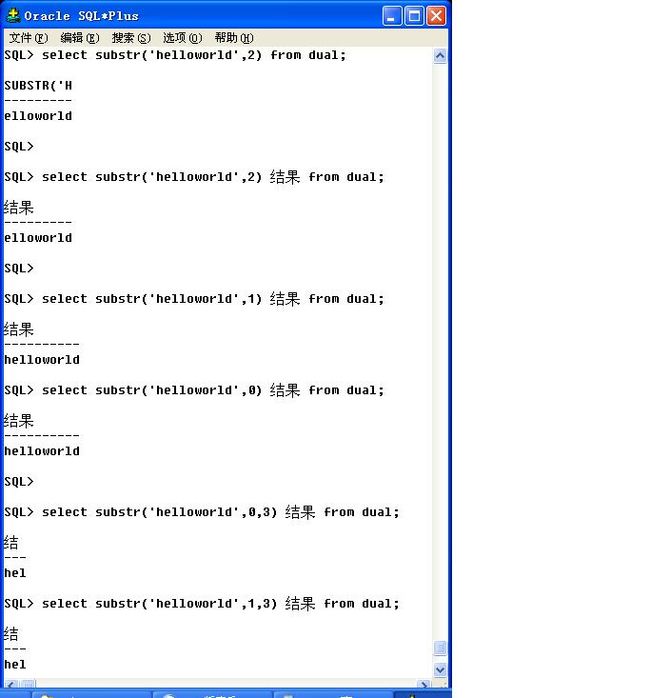
请问subst()函数截取的时候下标是从0开始还是从1开始?
从0或者1开始都是一样的。
45、
要求截取雇员姓名的后三个字母.
方法一:select ename,substr(ename,length(ename)-2) from emp;
方法二:select ename,substr(ename,-3) from emp;
oracle中,substr()也可以设置为负数,表示由后指定截取的开始点;
46、
round(数字|列[保留小数的位数]):四舍五入的操作;
trunc(数字|列[保留小数的位数]):舍弃制定位置的内容;
mod():去余数;
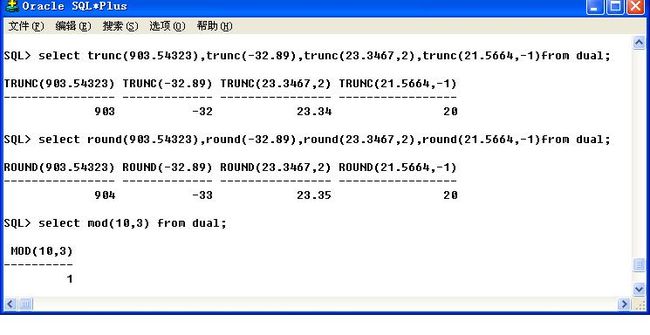
47、
日期函数
select sysdate from dual;取得当前系统日期。
日期+数字,表示若干天之后的日期;
日期-数字,表示若干天之前的日期;
日期-日期=数字,两个日期之间的天数;
除了以上的三个公式之外,也提供了以下四个操作函数;
last_day(日期):求出制定日期的最后一天,
例如:select last_day(sysdate)from dual;
next_day(日期,星期数):求出下个指定星期x的日期,
例如:select next_day(sysdate,"星期五")from dual;
add_months(日期,数字):求出若干个月之后的日期,
例如:select add_months(sysdate,4)from dual;
months_between(日期,日期):求出两个日期之间所经历的月份。
select ename,months_between(sysdate,hiredate)from emp;
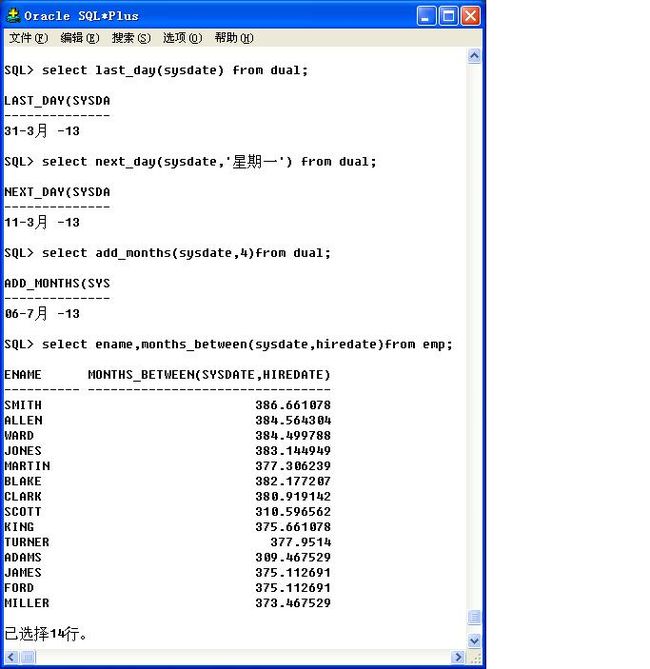
在开发中,如果是日期的操作,建议使用以上的函数,因为这些个函数可以避免闰年的问题。
48、
转换函数
数据类型:number、varchar2、date等等之间的互相转换的操作,需要用到转换函数。
to_char(字符串|列,格式字符串):将日期或者数字变为字符串显示;
to_date(字符串,格式字符串):将字符串变为date数据显示;
to_number(字符串):将字符串变为数字显示;
格式字符串:年(yyyy),月(mm),日(dd),12小时制时(hh),24小时制时(hh24),分(mi),秒(ss)。
49、
如果在时间数据中存在前导0,如果要消除掉这个0的话,则就可以加入一个“fm”。
to_char 也可以用于数字的格式化上,每个“9”表示以为数字的概念,而不是数字9;
其中的“L”表示“locale”的含义:当前所在语言环境下的货币符号。
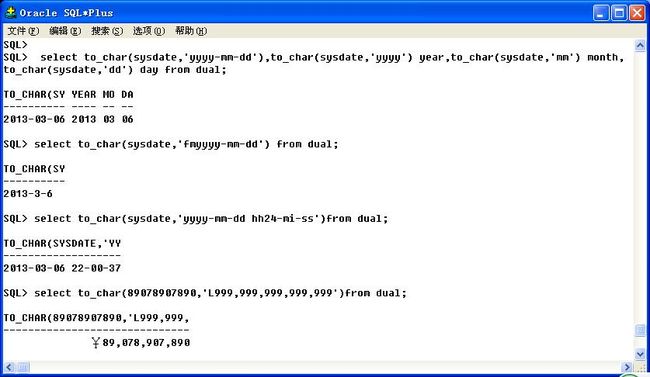
to_date()函数的主要功能是将一个字符串变为date类型。
select to_date('1989-09-12','yyyy-mm-dd')from dual;
to_number()将字符串变为数字。
select to_number('1')+to_number('2')from dual;
但是,Oracle很智能,所以用select '1'+'2' from dual;
50、
nvl函数,处理null。
例如:求雇员的年薪:select ename,sal,comm,(sal+comm)*12 from emp;
这个时候有的年薪就变成了null,原因是comm字段上有的为null,nvl()函数可以使null变成0;
select ename,sal,comm,nvl(comm,0),(sal+nvl(comm,0))*12 from emp;
51、
decode()函数:多数值判断。类似于if..else..,格式为:decode(数值|列,判断值1,显示值1,判断值2,显示值2...);(成对出现)
例如:将职位换成相应的汉字:
select ename,job,decode(job,'CLERK','办事员','MANAGER','经理')from emp;
注意:如果没有找到相应的职位,则会什么都不显示。decode函数式Oracle中最具有特色的函数,一定要掌握。
52、
以年月日的形式显示雇员的被雇的时间。
select ename,hiredate,
trunc(months_between(sysdate,hiredate)/12)year,
trunc(mod(months_between(sysdate,hiredate),12))months,
trunc(sysdate-add_months(hiredate,months_between(sysdate,hiredate)))day from emp;
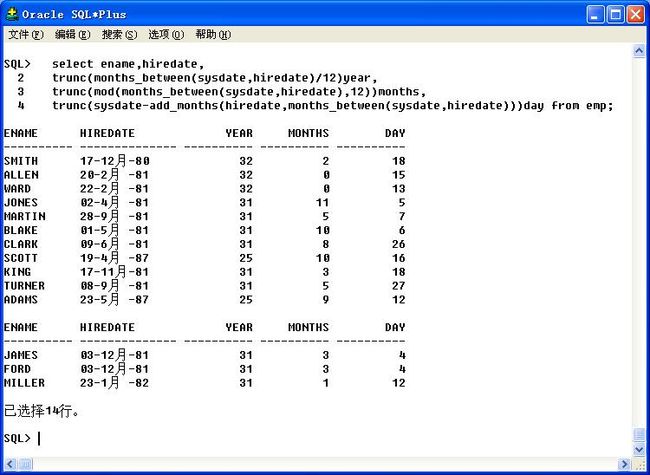
53、
在sqlplus中:
在请输入用户名:后面可以直接这样输入system/manager。
54、
一般表的查询的语法为:
select [distinct]*|列[别名][,列 别名,....]
from 表名 [别名]
[where 条件(s)]
[order by 排序字段 asc|desc [,排序字段 asc|desc]];
多表查询的语法为:
select [distinct]*|列[别名][,列 别名,....]
from 表名 [别名] ,[表名称 [别名],...]
[where 条件(s)]
[order by 排序字段 asc|desc [,排序字段 asc|desc]];
54、
如果表中数据量非常大的话,如果直接查询,容易造成系统死机的现象,所以
在接触到新的数据库和数据表的时候应该查询表中的数据量:select count(*) from 表;
55、
select * from emp,dept;会产生56条记录=雇员表的14条*部门表的4条记录,
主要是因为数据库的查询机制造成的(笛卡尔乘积),这肯定不是
用户所期望的,所以用下边的方法:
select *from emp,dept where emp.deptno=dept.deptno;14行记录,此时虽然
消除了笛卡尔乘积,但是现在只是属于显示上的消除,而真正的笛卡尔积依然存
在,因为数据库的操作机制就是:逐行的进行数据判断!!!
如果两个表的数据量都很大,那么多表查询性能更差,例如如下的语句:
select count(*)from sales s,costs c where s.prod_id=c.prod_id;显示的结果
很慢或者直接卡死。
所以尽量避免多表查询。
56、
查出每位雇员的编号、姓名、职位、部门名称、位置
select e.empno,e.ename,e.job,d.dname,d.loc
from emp e,dept d
where e.deptno=d.deptno;
57、
查询每位雇员的姓名、职位、领导的名字
select e.ename,e.job,m.ename
from emp e,emp m
where e.mgr=m.empno;
由于KING没有领导,没有此人的记录,要想解决这个问题,就需要左右连接的知识了(以后会讲明)。
58、
查询雇员的姓名、领导的名字、部门。
select e.ename,m.ename,d.dname
from emp e,emp m,dept d
where e.mgr=m.empno and e.deptno=d.deptno;
59、
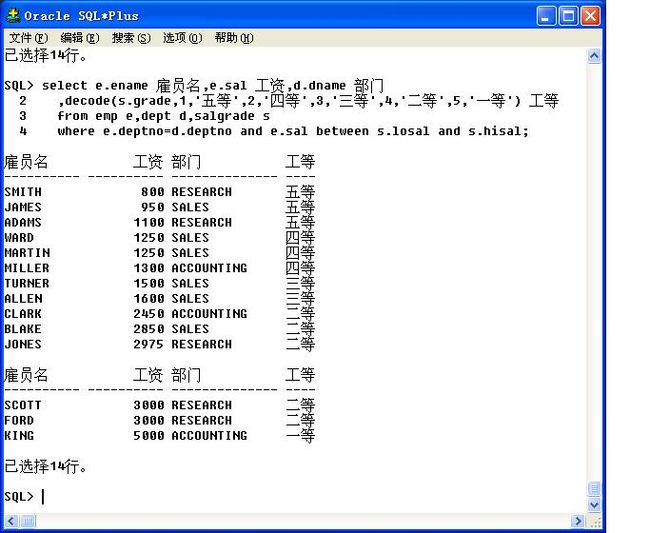
select e.ename 雇员名,e.sal 工资,d.dname 部门
,decode(s.grade,1,'五等',2,'四等',3,'三等',4,'二等',5,'一等') 工等
from emp e,dept d,salgrade s
where e.deptno=d.deptno and e.sal between s.losal and s.hisal;
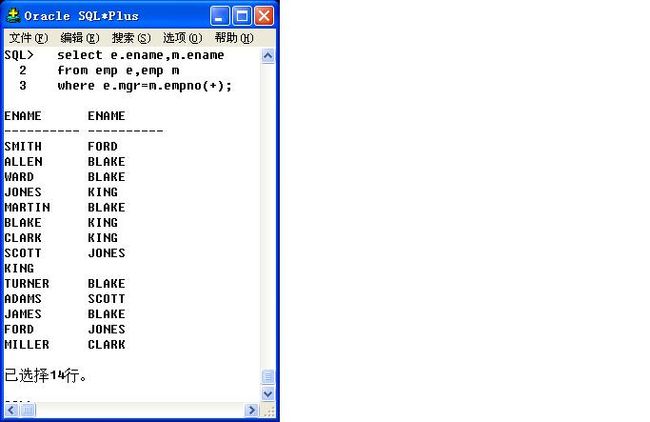
60、
问题57的解决:
=..(+):左连接;
(+)..=:右连接;
但是不要刻意区分是左还是右,根据查询结果而定,如果发现有些需要的数据
没有显示出来,就可以使用此符号更改连接方向。
但是这种数据库是Oracle独有的,其他数据库不能使用。
select e.ename,m.ename
from emp e,emp m
where e.mgr=m.empno(+);
3.1.3 sql:1999语法
除了以上的表连接操作之外,在sql语法中,也提供了另外一套用于表连接的sql,格式如下:
select table1.column,table2.column
from table1[crooss join table2]
|[natural join table2]|
[join table2 using(column_name)]|
[join table2 on(table1.column_name=table2.column_name)]|
[left|right|full outer join table2 on(table1.column_name=table2.column_name)];
以上是多个语法的联合,下面分块说明。
1、交叉连接(cross join):用于产生笛卡尔积
select *from emp cross join dept;
2、自然连接(natural join ):自动找到匹配的关联字段,消除掉笛卡尔积
select *from emp natural join dept;
3、join...using:用户自动指定一个消除笛卡尔积的关联字段
select*from emp join dept using(deptno);
4、join..on :用户自己指定一个可以消除笛卡尔积的关联条件
select*from emp join dept on(emp.deptno=dept=deptno)
5、连接方向的改变:
.左(外)连接:left outer join..on;
.右(外)连接:right outer join..on;
.全(外)连接:full outer join..on;
select *from emp right outer join dept on(emp.deptno=dept.deptno);
说明:在Oracle之外的数据库都使用以上的sql:1999语法操作。
再次强调:多表查询的性能肯定不高,而且性能一定要在大数据量的情况下才能发现。
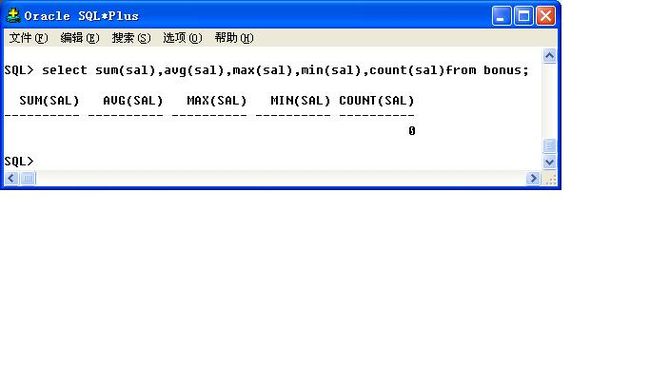
3.2.1、统计函数
count()、avg()、sum()、max()、min()
.范例:统计每个月的平均工资和总工资,最高工资和最低工资。
select count(empno),sum(sal),avg(sal),max(sal),min(sal)from emp;
注意点:如果一张表没有任何记录,则count()也会返回数据“0”,但是其他函数会返回null,count()永远会返回一个具体的数字.
3.2.3、分组统计
分组的情况如下:
. 要求男性一组,女性一组,统计男性和女性的数量;
. 按照年龄分组,18以下一组,18以上一组;
. 按地区分组,北京人一组,南京人一组,上海一组;
共同点:数据的某列上会存在重复的内容,当数据重复的时候分组才有意义。
语法:select [distinct]*|列[别名][,列 别名,....]|统计函数
from 表名 [别名]
[where 条件(s)]
[group by 分组字段1[,分组字段2,...]]
[order by 排序字段 asc|desc [,排序字段 asc|desc]];
.范例:
按照部门编号分组,求出每个部门的人数,平均工资
select deptno,count(empno),avg(sal) from emp group by deptno order by deptno asc;
.范例:按照职位分组,求出每个职位的最高和最低工资
select job,max(sal),min(sal) from emp group by job;
但是一旦分组就会对语法有限制,对于分组有以下要求:
1、分组函数可以在没有分组的时候单独使用,可是不能出现在其他的查询字段
错误的代码:select empno,count(empno)from emp;
2、分组后,则select子句之后,只能出现分组的字段和统计函数,其他的字段不能出现。
正确:select job,count(empno),avg(sal) from emp group by job;job是分组的字段,count和avg是统计函数。
错误:select deptno,job,count(empno),avg(sal) from emp group by job;
3、 分组函数允许嵌套,但是嵌套之后的分组函数查询中不能再出现。
范例:查询出平均工资最高的工资
错误 :select job,max(avg(sal))from emp group by job;
正确:select max(avg(sal))from emp group by job;
范例:
查询出每个部门的名称、部门的人数、平均工资。
第一步:确定所需要的表:
dept表:每个部门的名称
emp表: 统计出部门的人数、平均工资
第二步:确定已知的关联字段:emp.deptno=dept.deptno
第三步:将dept表和emp表的数据关联
select d.dname,e.empno,e.sal
from dept d,emp e
where d.deptno=e.deptno;
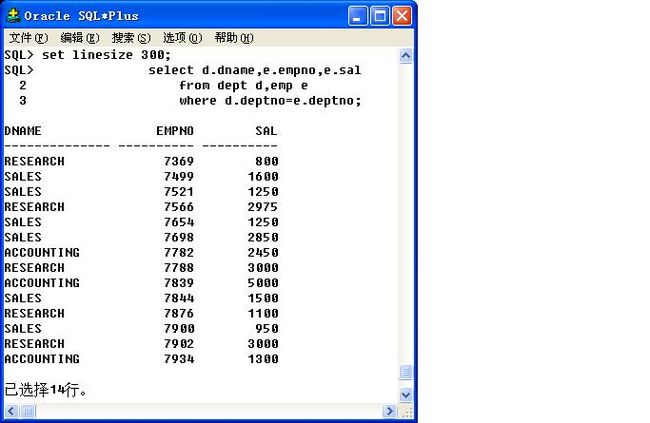
此时的查询结果中,可以发现dname字段有重复内容,那么就可以分组;此时的分组和之前不一样,
之前都是实体表,此时是一张临时的虚拟表,但是不管是实体表还是虚拟表都可以进行分组。
select d.dname,count(e.empno),nvl(avg(e.sal),0)
from dept d,emp e
where d.deptno=e.deptno(+)
group by d.dname;
以上的分组时单字段分组,下面是多字段的分组:
范例:要求显示每个部门的编号、名称、位置、部门的人数、平均工资
具体步骤和上例类似,
将两表的数据关联起来:
select d.deptno,d.loc,d.dname,e.empno,e.sal
from dept d,emp e
where d.deptno=e.deptno(+);
重复数据平均在了三列上(deptno,dname,loc),所以分组上group by上写上上边三个字段:
select d.deptno,d.dname,d.loc,count(e.empno),nvl(avg(e.sal),0)
from dept d,emp e
where d.deptno=e.deptno(+)
group by d.dname,d.deptno,d.loc;
范例:统计每个部门的详细信息,且平均工资高于2000
普通思路是:使用where
select d.deptno,d.dname,d.loc,count(e.empno),nvl(avg(e.sal),0)
from dept d,emp e
where d.deptno=e.deptno(+)and avg(e.sal)>2000
group by d.dname,d.deptno,d.loc;
但是这个是错误的语句,因为在where子句中不能使用统计函数,因为where功能是从全部数据中取出
部分数据。 此时如果要对分组后的数据再次过滤,则使用having子句完成,此时语法如下:
select [distinct]*|列[别名][,列 别名,....]|统计函数
from 表名 [别名]
[where 条件(s)]
[group by 分组字段1[,分组字段2,...]]
[having 分组后的过滤条件(可以使用统计函数)]
[order by 排序字段 asc|desc [,排序字段 asc|desc]];
下面使用having进行过滤。
select d.deptno,d.dname,d.loc,count(e.empno),nvl(avg(e.sal),0)
from dept d,emp e
where d.deptno=e.deptno(+)
group by d.dname,d.deptno,d.loc
having avg(sal)>2000;
注意点:where和having的区别
where:是在执行group by操作之前进行的过滤,表示的是从全部数据中筛选出部分数据,where子句不能使用统计函数;
having:是在group by分组之后的再次过滤 ,可以在having子句中使用统计函数;
范例:显示非销售人员工作名称以及从事同一工作雇员的月工资的总和,且要满足从事同一工作的雇员的月工资合计大于5000,
输出结果按月工资的合计升序排列。
第一步:
查询出所有的非销售人员的信息
select*from emp where job<>'SALESMAN';
第二步:
按照职位进行分组,并且使用sum函数统计
select job,sum(sal)
from emp
where job<>'SALESMAN'
group by job;
第三步:过滤
select job,sum(sal)
from emp
where job<>'SALESMAN'
group by job
having sum(sal)>5000;
第四步:按升序排列
select job,sum(sal) sum
from emp
where job<>'SALESMAN'
group by job
having sum(sal)>5000
order by sum asc ;
sum是sum(sal)的别名。
3.3 子查询(核心重点)
子查询=简单查询+限定查询+多表查询+统计查询的综合体;
多表查询的性能很差,但是子查询能代替多表查询,所以子查询用得较多;
子查询就是在一个查询中嵌套了其他的若干查询;
子查询出现在where和from子句中较多;
where:子查询一般只返回单行单列、多行单列、单行多列的数据;
from :子查询返回的一般是多行多列的数据,当做一张临时表出现;
范例:
查询出工资比SMITH工资高的全部雇员信息
select*from emp where sal>(
select sal from emp where ename='SMITH');
范例:
查出高于公司的平均工资的全部雇员信息
select*from emp where sal>(
select avg(sal) from emp);
以上返回的是单行单列,下面是单行多列(较少):
select *from emp
where (job,sal)=(
select job,sal from emp
where ename='SMITH');
如果子查询返回的是多行单列,就需要使用三种判断符判断:in、any、all;
1、in:和之前的in是一样的,只是里面的范围由子查询指定。
select*from emp where sal in(
select sal from emp where job='MANAGER');
但是在not in中,如果子查询的结果有null的话就不会有任何的结果,原因是
如果查询的内容不是空的话,所有的数据都要显示,则有可能无法浏览或者死
机(如果数据量很大的话),所以直接规定了不会显示任何的结果.
2、any:三种形式
=any:功能与in是完全一样的;
>any:比子查询中返回记录最小的值大的数据;
<any:比子查询中返回记录最大的值小的数据;
select*from emp where sal <any(
select sal from emp where job='MANAGER');
3、all:两种
>all:比子查询中返回记录最大的值还要大的数据;
<all:比子查询中返回记录最小的值还要小的数据;
以上都是在where子句中出现的,下面是from子句,这个子查询返回的是多行多列的数据
,当做一张临时表的方式来处理。
范例:查询每个部门的编号、名称、位置、部门人数、平均工资
以前是多字段分组统计完成的:
select d.deptno,d.dname,d.loc,count(e.empno),nvl(avg(e.sal),0)
from emp e,dept d
where e.deptno(+)=d.deptno
group by d.deptno,d.dname,d.loc;
这个时候有笛卡尔积,一共差生了56条记录;解决方案:通过子查询完成,所有的统计查询
只能在group by中出现,所以在子查询中负责统计数据,而在外部负责将统计数据和dept表
数据的统一。
select d.deptno,d.dname,d.loc,temp.count,temp.avg
from dept d,(
select deptno dno,count(empno) count,avg(sal) avg
from emp
group by deptno)temp
where temp.dno(+)=d.deptno;
3.4数据库的更新操作
在更新emp表之前,先将emp表复制一份,输入下列指令:
create table myemp as select*from emp;
注意:这种语法是oracle中支持的操作,其他数据库不一样!
3.4.1增加
特别注意:在增加date数据的时候有三种方式:
1、可以按照已有的日期字符串格式编写字符串,例如“17-12月-80 ”;
2、用to_date()函数将字符串变为date类型的;
3、如果设置的时间为当前系统时间,用sysdate;
范例:完整性编写
insert into myemp(empno,ename,job,mgr,hiredate,sal,comm,deptno)
values('1','李斯','程序员',7369,to_date('2008-08-23','yyyy-mm-dd'),2223,12,40);
insert into myemp(empno,ename,job,mgr,hiredate,sal,deptno)
values('1','王丽','老总',7369,sysdate,2223,40);
范例:简便语法,不写列名
insert into myemp
values('12','王开','技术总监',7369,to_date('2008-08-23','yyyy-mm-dd'),2223,null,10);
3.4.2 数据修改
将empno=1的人雇佣时间改为今天:update myemp set hiredate=sysdate where empno=1;
工资增加50%:update myemp set sal=sal*1.5;
3.4.3数据删除
把1981年雇佣的人删掉
delete from myemp where to_char(hiredate,'yyyy')=1981;
删除所有数据
delete from myemp;
3.5、事务处理
所有的数据更新一定会受到事务的控制!
在 oracle 中每个连接都会产生一个 Session(比如打开多个sqlplus窗口就是多个session),一个 session 对数据库的修改,
不会立刻反映到数据库的真实数据上,是允许回滚的。只有当提交了,才变成持久数据了。
事务控制主要有两个命令:rollback,commit。
死锁:某个session在更新表的某列时还没有提交事务,其他session是无法更新此列的,必须等待之前的session提交后才可以
。
可能出现死锁的情况
原子性(Atomicity)
一致性(Consistency)
隔离性(Isolation )
持久性(Durability )
原子性和一致性的差别?
原子性:只一个事务中,包含若干个数据操作,这些操作是一个整体,要么一起完成,要么一起不完成,不能只完成其中的一部
分。比
如你去银行转帐,从一个账户转帐到另一个账户,这是一个完整的事务,包括两个操作,从你第一个账户读数,增加到第二个账
户,并
减去第一个账户中的钱,如果这些操作有一个失败了,整个事务都必须还原成最开始的状态。
一致性:是指数据库从一个完整的状态跳到另一个完整的状态,是用于保护数据库的完整性的。比如你修改数据库的某个外键值
,如果
没有和相应的主键对应,就违反了数据库的一致性。另外,还有读一致性,如:你刚写入一个数到数据库中,但还没有提交,这
时候有
人要读这个数,就涉及完整性问题,要保证读取的数据在整个数据库中是处于和其他数据一致的一个状态。
3.6数据伪列
是Oracle自行维护的列,不需要用户处理,有两个:ROWNUM,ROWID。
3.6.1 ROWNUM
是行号的意思,为每一个显示的记录都会自动的随着查询生成行号.
select rownum,empno,ename,job from emp;
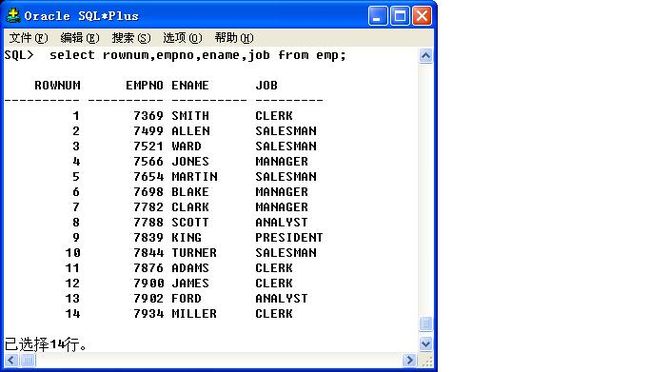
此时的rownum行号并不是永久固定的;
select rownum,empno,ename,job from emp where deptno=30;
是每次动态的重新生成的。
范例:查询前5条记录
select empno,ename,job from emp where rownum<=5;
范例:查询6~10条记录
错误:select empno,ename,job from emp where rownum between 6 and 10;
没有返回任何数据,因为rownum并不是真实的列
正确的思路为:先查询前10条,之后再显示后5条,用子查询。
正确:select*from (
select rownum rn,empno,ename,job from emp
where rownum<=10 )temp
where temp.rn>5;
按照这个思路实现分页:
分页范例:每页5条记录.
第一页:
select*from (
select rownum rn,empno,ename,job from emp
where rownum<=5 )temp
where temp.rn>0;
第二页:
select*from (
select rownum rn,empno,ename,job from emp
where rownum<=10 )temp
where temp.rn>5;
第三页:
select*from (
select rownum rn,empno,ename,job from emp
where rownum<=15 )temp
where temp.rn>10;
3.6.2 ROWID
表示的是每行数据保存的物理地址的编号。
例如:select rowid,empno,ename from emp;
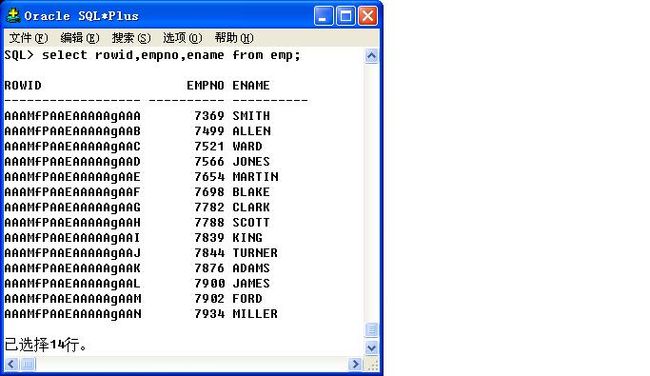
每条记录的rowid不会重复,即使所有列的数据内容都重复了。
例如:AAAMfPAAEAAAAAgAAA
数据对象号:AAAMfP
相对文件号:AAE
数据块号 :AAAAAg
数据行号 :AAA
范例:删除表里的重复记录?
首先,先往dept表里增加数据(除了deptno不一样,其他字段都一样)。
insert into dept values(21,'RESEARCH','DALLAS');
insert into dept values(31,'SALES','CHICAGO');
insert into dept values(32,'SALES','CHICAGO');
insert into dept values(41,'OPERATIONS','BOSTON');
insert into dept values(42,'OPERATIONS','BOSTON');
insert into dept values(43,'OPERATIONS','BOSTON');
commit;
然后查出那些列是 重复的,按照部门名称和位置分组,之后统计个数,如果个数大于1,在表示重复;
select dname,loc,min(rowid)
from dept
group by dname,loc
having count(deptno)>1;
数据插入的越早,rowid就越小,所以下步确定的是不能删除的rowid,若去掉之前的 having count(deptno)>1;
表示按照部门名称和位置分组,取出每一个最的rowid。
select min(rowid)
from dept
group by dname,loc;
最后:删除之前添加的列
delete from dept
where rowid not in(
select min(rowid)
from dept
group by dname,loc
);
commit;
88、列出薪金比“SMITH”或"ALLEN"多的所有员工的编号、姓名、部门名称、其领导姓名。
首先查出“SMITH”和"ALLEN"的薪金,
select e.empno,e.ename,d.dname,m.ename
from emp e,dept d,emp m
where
e.sal>all(
select sal from emp where ename in('SMITH','ALLEN')
)and
e.deptno=d.deptno and e.mgr=m.empno(+);
89、
列出所有员工的编号、姓名及其直接上级的编号、姓名,显示的结果按领导年工资的降序排序。
select e.empno,e.ename,e.mgr,m.ename,(m.sal+nvl(m.comm,0))*12 income
from emp e,emp m
where e.mgr=m.empno(+)
order by income desc;
但是会发现king的工资为null。
可以修改如下:多加了nvl((m.sal+nvl(m.comm,0))*12,0)中的nvl()函数。
select e.empno,e.ename,e.mgr,m.ename,nvl((m.sal+nvl(m.comm,0))*12,0) income
from emp e,emp m
where e.mgr=m.empno(+)
order by income desc;
90、
复习习题讲解2(视频28)
个人总结:任何的分组函数都可以写成子查询(where或者from子句)的形式,这样可以把复杂问题简单化。
91、
下面介绍常用数据类型:
varchar2(n):最多为n位的字符串;
number(n):最多为n位的整数,有时候也用int代替。
number(n,m):m为小数位,n-m为整数位,有时候也用float代替;
date :存放日期-时间。
CLOB(Character Large Object):字符大型数据;字符大对象(CLOB)是变长字符串,最大长度2G。用于存储大的单字节字符集数据。可以存储海量小说。
BLOB:二进制大对象(binary large object),是变长字符串,最大长度2G。主要用来保存非传统数据,如图片、声音及混合媒体等。
92、
表的创建语法:
create table 表名称(
字段1 数据类型 [DEFAULT 默认值],
字段2 数据类型 [DEFAULT 默认值],
.....
字段n 数据类型 [DEFAULT 默认值],
);
例如:
create table s(
name varchar2(50) default '英雄',
age number(3),
birthday date default sysdate,
describe clob
);
插入数据:
insert into s values('小王',22,to_date('1991-07-12','yyyy-mm-dd'),'清华大学毕业的高材生!');
insert into s(age,describe)values(11,'祖国万岁');
结果下图:
93、
表的复制(下面的方法只支持Oracle数据库)
语法:create table 表名称 as 子查询;
范例:复制一张只包含部门号为20的雇员信息的表
create table emp20 as select*from emp where deptno=20;
范例:只将emp表的表结构复制出来,不要数据,方法是:写一个永远满足不了的条件即可。
create table empnull as select*from emp where 1=3;
94、为表重新命名
在Oracle数据库中,所有的数据实际上都是通过数据字典保存的,例如:select*from tab就是一个数据字典,
而在Oracle中,提供了三种类型的数据字典:dba_ 、user_,查询一个user_tables数据字典:select*from user_tables;
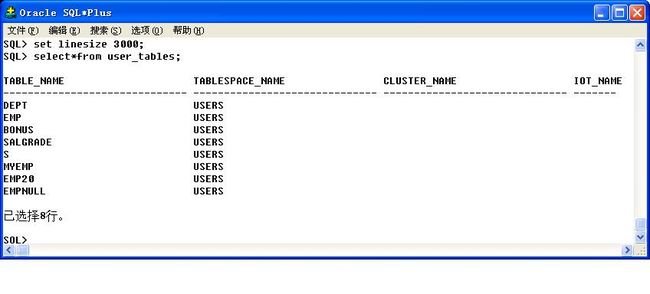
也就是说Oracle中的所有数据都是按照文件保存的,那么所有的内容都会在数据字典中注册,所以修改表名称实际上对于Oracle
来说就相当于修改了一条数据而已,语法如下:
rename 旧的表名称 to 新的表名称;
例如:rename s to ss;
95、截断表
之前的用:delete from emp;的操作有一个特点:可以回滚事务,就是说删除后不会立即释放数据的资源,如果
希望彻底释放一张表所占用的全部资源(表空间、索引等),就可以使用阶截断的语法:
truncate table 表名称;
截断语法是Oracle特有的。
96、表的删除
drop table 表名称;
97、Oracle10g的新特性:闪回技术
在Oracle 10g以后,用户所删除的表默认情况下会在一个回收站中保存,用户可通过回收站进行表的恢复。
此技术称为闪回(FLASHBACK);
查看回收站:show recyclebin;
恢复表 :flashback table 表名称 to before drop;
直接删除回收站中的表:purge table 表名称;purge是清除的意思。
清空回收站:purge recyclebin;
删除表并且不进入回收站:drop table 表名称 purge;
注意:回收站可以存在相同(表结构、表名称等都一样)的表,但是只能恢复一个这样的表,就如同在window下的回收站中
恢复相同文件的错误提示是一样的,如下:
98、修改表结构
增加字段:alter table 表名称 add(列名称 数据类型 [default 默认值],列名称 数据类型 [default 默认值],.....);
修改字段:alter table 表名称 modify(列名称 数据类型 [default 默认值],列名称 数据类型 [default 默认值],.....);
99、
面试题:
现要求建立一张nation表,表中有一个name字段,里面保存四条记录:中国、美国、巴西、荷兰,通过查询实现以下的效果:
中国 美国
中国 巴西
中国 荷兰
美国 巴西
美国 中国
美国 荷兰
剩下的以此类推。
首先建立数据库创建脚本:
1、文件的名称必须是“*.sql”;
2、先删除相应的数据表;
3、编写创建表的语句;
4、增加测试数据;
5、提交事务;
解答的过程最好是这样的:
--1、删除表
drop table nation purge;
--2、创建表
create table nation(
name varchar2(50)
);
--3、测试数据
insert into nation values('中国');
insert into nation values('美国');
insert into nation values('巴西');
insert into nation values('荷兰');
--4、事务提交
commit;
select n1.name ,n2.name
from nation n1, nation n2
where n1.name<>n2.name;
100、
约束:非空约束(not null)、唯一约束(unique)、主键约束、检查约束、外键约束。
101、
非空约束
--1、删除表
drop table nation purge;
--2、创建表
create table nation(
id number,
name varchar2(50) not null
);
范例:插入正确的数据
insert into nation(id,name)values(1,'张三');
insert into nation(id,name)values(null,'王五');
insert into nation(name)values('李四');
范例:插入错误的数据
insert into nation(id,name)values(5,null);
insert into nation(id)values(10);
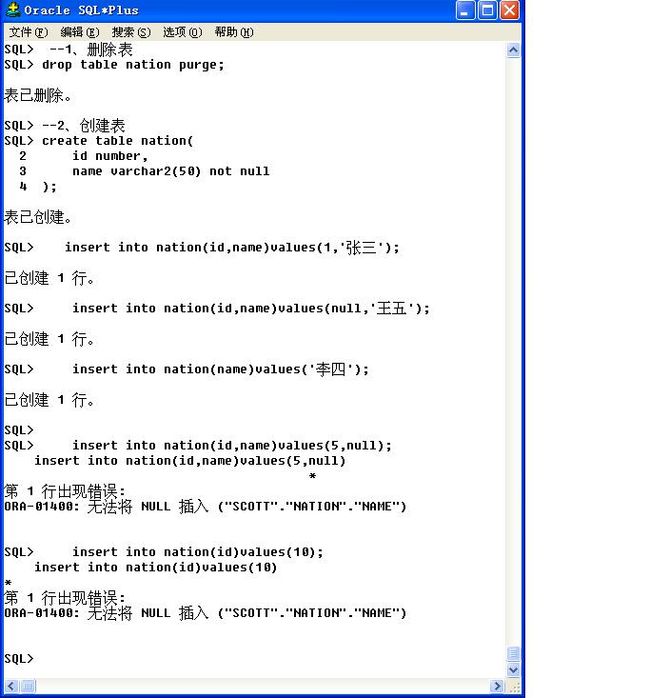
发现有错误提示:ORA-01400: 无法将 NULL 插入 ("SCOTT"."NATION"."NAME")
直接给出了“用户”,“表名称”,“字段”出现了错误。
102、
唯一约束
--1、删除表
drop table nation purge;
--2、创建表
create table nation(
id number,
name varchar2(50) not null,
email varchar2(50) unique
);
范例:插入正确的数据
insert into nation(id,name,email)values(1,'张三','[email protected]');
insert into nation(id,name,email)values(null,'王五',null);
范例:插入错误的数据
insert into nation values(10,'李四','[email protected]');
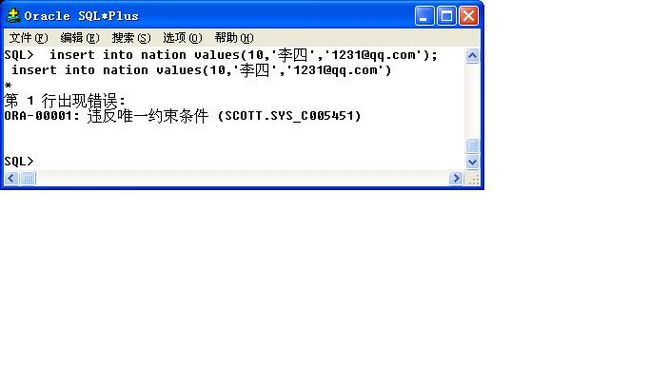
此时会有错误的提示:ORA-00001: 违反唯一约束条件 (SCOTT.SYS_C005451)
但是此错误提示与之前的非空约束相比并不完善,只是给出了一个代号,这是因为
在定义约束的时候没有为约束指定一个名字,所以由系统默认分配了,而且约束的
名字建议的格式是"约束类型_字段", 例如:UK_email。指定约束名称使用constraint
完成。如下:
drop table nation purge;
--2、创建表
create table nation(
id number,
name varchar2(50) not null,
email varchar2(50) ,
constraint UK_email unique(email)
);
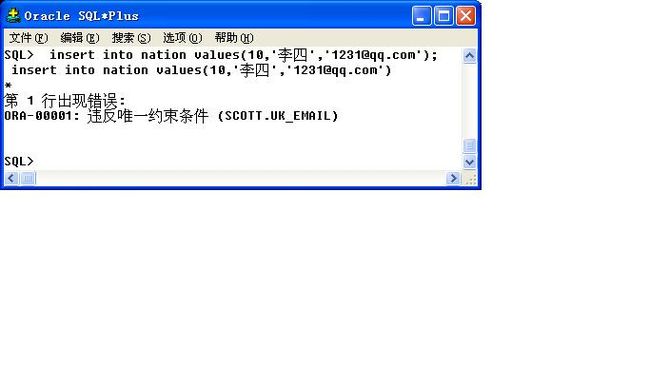
有图可知,提示信息为:ORA-00001: 违反唯一约束条件 (SCOTT.UK_EMAIL)
已经非常明显的提示了错误的位置。
103、
主键约束=非空约束+唯一约束
a.如果错误时由于输入空值引起的,那么错误提示和非空约束是一样的;
b.如果重复插入数据,则错误提示和唯一约束是一样的;
所以在定义表的时候这样写:
create table nation(
id number,
name varchar2(50) not null,
constraint PK_ID primary key(id)
);
此时如果重复插入数据了,提示错误信息如下:
ORA-00001: 违反唯一约束条件 (SCOTT.PK_ID)
也可以设置复合主键,例如:
create table nation(
id number,
name varchar2(50) not null,
constraint PK_ID_name primary key(id,name)
);
104、
检查约束(Check):CK
检查约束指的是为表中的数据增加一些过滤条件,例如:
.设置年龄的范围:0~120
.设置性别 :男、女
例如下表:
drop table nation purge;
create table nation(
id number,
name varchar2(50) not null,
sex varchar2(19) not null,
age number(3),
constraint PK_ID_name primary key(id,name),
constraint ck_sex check(sex in('男','女')),
constraint ck_age check(age between 0 and 120)
);
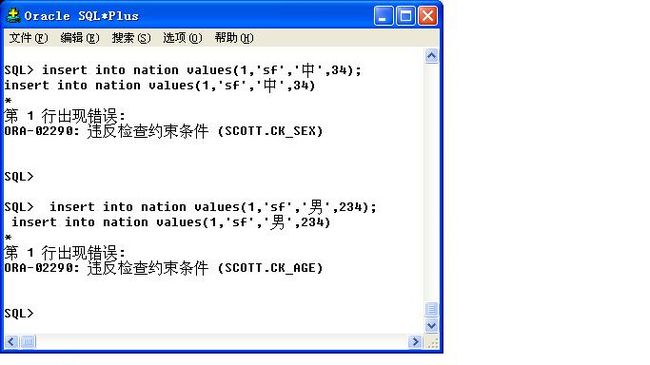
ORA-02290: 违反检查约束条件 (SCOTT.CK_AGE)
ORA-02290: 违反检查约束条件 (SCOTT.CK_SEX)
105、
主-外键约束(fk)
例如下表:
create table book(
id number,
title varchar2(33) not null,
pid number,
constraint pk_id primary key(id),
constraint fk_pid foreign key(pid) references person(id)
);
其中person是父表,book是子表,一个人可以拥有多本书。
但是外键约束带了很多的问题:
a、删除主表数据的时候,如果主表中的数据有对应的子表数据,则无法删除,
但是问题可以通过增加级联删除的功能来解决。
create table book(
id number,
title varchar2(33) not null,
pid number,
constraint pk_id primary key(id),
constraint fk_pid foreign key(pid) references person(id) on delete cascade
);
但是级联删除会删除掉子表的数据,这往往是我们不希望看到的,
所以可以先设置子表所对应的数据为null,然后再删除父表中的数据,如下:
create table book(
id number,
title varchar2(33) not null,
pid number,
constraint pk_id primary key(id),
constraint fk_pid foreign key(pid) references person(id) on delete set null
);
b、删除父表之前必须首先删除子表,否则无法删除
但是Oracle专门提供了一个强制性删除的操作:在删除的时候加上:cascade constraint;
例如:drop table person cascade constraint [purge];
此时不关心子表是否存在,直接强制性删除父表。
106、 修改约束 (但是非空约束作为一个特殊的约束无法操作。)
a、增加约束
alter table 表名称 add constraint 约束名称 约束类型(字段);
例如:alter table person add constraint pk_id primary key(id);
例如:alter table person add constraint ck_age check(age between 0 and 122);
但是如果表中已经存在了违反约束的数据,则无法更加约束。
b、删除约束
alter table 表名称 drop constraint 约束名称;
例如:alter table person drop constraint ck_age;
107、查询约束
在Oracle中所有的对象都会在数据字典中保存,约束也是,可以直接查看“user_constraints”数据字典
就可以知道有哪些约束。
select*from user_constraints;
select OWNER,CONSTRAINT_NAME ,TABLE_NAME from user_constraints;
但是只是查询了约束的名字,没有告诉在哪个字段上有此约束,但是有另外一张数据字典“user_cons_columns”;
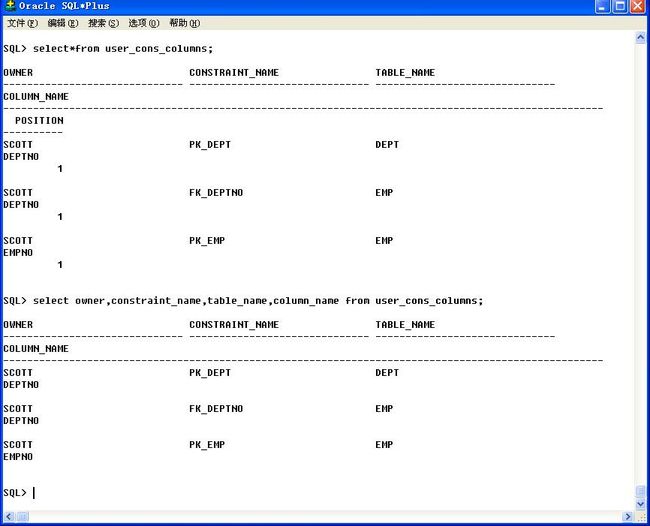
但是由于 OWNER、CONSTRAINT_NAME、TABLE_NAME、COLUMN_NAME所占太长,所以出现折行问题,解决如下:
col OWNER for A15;
col CONSTRAINT_NAME for A15;
col TABLE_NAME for A15;
col COLUMN_NAME for A15;

108、
集合操作
在数学中,存在交、差、并、补的概念,在数据的查询中也存在此概念,有如下的连接符:
. union:连接两个查询,相同的部分不显示;
. union all:连接两个查询,相同的部分显示;
. intersect:返回两个查询中的相同部分;
. minus: 返回两个查询中的不同部分;
现创建一张只包含20部门雇员信息的表:
create table emp20 as select*from emp where deptno=20;
范例:验证union
select*from emp
union
select*from emp20;
范例:验证union all
select*from emp
union all
select*from emp20;
范例:验证 intersect
select*from emp
intersect
select*from emp20;
范例:验证 minus
select*from emp
minus
select*from emp20;
范例:所有领取奖金的人求出平均工资,所有不领取工资的人的平均工资。
select 'uncomm',avg(sal)from emp where comm is null
union
select 'comm',avg(sal)from emp where comm is not null ;
109、序列
在各个数据库之中都存在了一种称为自动增长列的类型,但是在Oracle之中并没有提供这种自动完成的增长列操作,而只是提供了一个可以手工控制的序列(sequence),所以要实现这功能那么就必须首先清楚序列的作用,序列创建语法:
| CREATE SEQUENCE序列名称 [INCREMENT BY 步长] [START WITH开始值] [MAXVALUE 最大值 | NOMAXVALUE] [MINVALUE 最大值 | NOMINVALUE] [CYCLE | NOCYCLE] [CACHE 缓存大小 | NOCACHE] ; |
既然在序列的创建上存在了CREATE,则序列就表示一个数据库对象。
范例:创建一个基本的序列
| CREATE SEQUENCE myseq ; |
序列创建成功之后,可以通过“user_sequences”这个数据字典查看所有的序列对象。
| SELECT * FROM user_sequences ; |
在这个myseq序列之中,可以发现包含以下几个内容:
· SEQUENCE_NAME:表示的是序列的名称;
· MIN_VALUE:最小值,默认是1;
· MAX_VALUE:最大值,它也只是定义了一个很大的数字而已;
· INCREMENT BY:步长,表示的是每次序列增长的内容;
· C:表示是否是循环序列,默认为N;
· O:表示是在进行分布式数据库序列增长操作中使用;
· CACHE_SIZE:每次缓存20个序列内容;
· LAST_NUMBER:最后一次增长的数据;
序列创建完成之后,本身并不能直接使用,必须依靠其两个伪列完成操作:
· NEXTVAL:表示使用下一个序列的内容;
· CURRVAL:表示获得当前序列的内容,不增长,调用此操作前至少要调用一次nextval;
| SELECT myseq.currval FROM dual ; SELECT myseq.nextval FROM dual ; SELECT * FROM user_sequences ; |
在进行序列操作的时候,会存在一个缓冲的问题,所谓的缓冲指的是为了方便用户操作,所以会默认为用户计算好一系列已经增长好的序列内容,如果用户操作的序列值在此范围之中,则在每次使用时不用再动态生成,而直接使用已经生成好的序列内容,这样做性能会高一些,但是会有另外一个问题出现。如果说现在因为某些原因数据库完蛋了,那么这些在缓冲中已经生成的序列内容就不在了,那么就会出现跳号问题,为了防止跳号,可以直接将缓存设置为NOCACHE。
清楚了序列的基本概念之后,那么下面就要动手去使用序列,在开发之中,序列使用最多的情况就是nextval,例如,现在有如下一张数据表。
| DROP TABLE member PURGE ; CREATE TABLE member ( mid NUMBER PRIMARY KEY , name VARCHAR2(20) ) ; |
而后,现在希望mid字段的内容可以受到序列的控制自动增长,所以在增加数据时就需要按照如下方式编写:
| INSERT INTO member(mid,name) VALUES (myseq.nextval,'张三') ; |
清楚了序列的基本概念之后,那么下面就可以根据自己的需要创建一些有意义的序列。
1、 修改序列的开始值:START WITH
| DROP SEQUENCE myseq ; CREATE SEQUENCE myseq START WITH 100 ; |
2、 修改序列的步长:INCREMENT BY
| DROP SEQUENCE myseq ; CREATE SEQUENCE myseq START WITH 1 INCREMENT BY 2 ; |
3、 定义循环序列:希望序列的内容可以在1、3、5、7、9之间循环使用。
| DROP SEQUENCE myseq ; CREATE SEQUENCE myseq START WITH 1 INCREMENT BY 2 CYCLE MINVALUE 1 MAXVALUE 10 CACHE 5 ; |
一定要记住,现在的CACHE的内容默认是20个长度,那么如果序列最大值是10,则肯定超过这个范围,所以必须修改CACHE的内容。
110、
视图
在之前讲解SQL语句的时候,查询操作是最麻烦的,所以在开发之中为了明确的分工开发人员和数据库人员的职位,所以专门提供了一种机制——视图,视图 =一条复杂的SQL语句,视图的创建语法如下:
| CREATE [OR REPLACE] VIEW 视图名称 AS子查询; |
范例:创建一张视图
| CREATE VIEW myview AS SELECT d.deptno,d.dname,d.loc,temp.count,temp.avg FROM dept d,( SELECT deptno dno,COUNT(empno) count,AVG(sal) avg FROM emp GROUP BY deptno) temp WHERE d.deptno=temp.dno(+) ; |
而视图创建完成之后,只需要查询视图,就可以得到与复杂查询同样的结果。
| SELECT * FROM myview ; |
那么如果说现在一个数据库设计人员帮助开发人员提供了这一系列的视图,那么所谓的复杂查询的编写问题就相当于转移出去了,所以在开发之中一个优秀的数据库设计人员,一定要提供好若干个视图(理想状态,现实很残酷)。
既然视图本身属于DDL的范畴,属于数据库的对象,所以要想删除视图,就可以使用DROP语句完成。
| DROP VIEW myview ; CREATE VIEW myview AS SELECT * FROM emp WHERE deptno=10 ; |
可是在开发之中,由于业务会经常的变更,那么所以视图也必须进行及时的更新,所以很多时候如果要修改视图的时候也可以使用替换的方式。
| CREATE OR REPLACE VIEW myview AS SELECT * FROM emp WHERE deptno=10 ; |
如果视图不存在则创建一个新的,如果视图存在了,则使用新的SQL替换掉已有的视图。
既然视图里面包含的都是查询语句,那么视图里的数据肯定不是真实存在的,是一种实体表数据的映射,但是在默认情况下创建的视图就可能会存在两个问题。
问题一:更新视图创建条件。
以上面的视图为例,现在的视图创建条件是“WHERE deptno=10”,那么既然视图里面的数据都不是真实的数据,而现在如果更新了视图中的某一条记录中的deptno会如何呢?
| UPDATE myview SET deptno=30 WHERE empno=7782 ; |
这个时候已经更新成功了,而且视图之中已经找不到此数据了,而真实的数据表之中的数据也被更新了,所以可以发现在默认情况下,对视图的更新实际上就相当于对真实表的更新,但是这里有一个问题,既然deptno字段为创建视图的条件,那么用户如果直接去更新视图,这样做是否合理?既然视图中的内容都是让用户浏览的,那么现在更新视图的创建条件肯定是不合理的,为了解决这个问题,可以使用一个WITH CHECK OPTION选项完成。
| CREATE OR REPLACE VIEW myview AS SELECT * FROM emp WHERE deptno=10 WITH CHECK OPTION; |
此时,重复执行以上的更新操作,出现以下的错误提示信息:
| ORA-01402: 视图 WITH CHECK OPTIDN where子句违规 |
明确的表示了,现在的视图中的deptno字段为创建条件,无法进行更新。
问题二:更新视图里的非创建条件
既然现在的视图里面都是虚拟的数据,那么理论上而言,也不应该具备可以更新的功能,可是下面观察一下。
| UPDATE myview SET sal=9000 WHERE empno=7782 ; |
现在更新的不再是创建条件,但是现在依然可以进行更新操作,所以很明显,这样做又不符合于视图的要求,所以为了保证视图无法更新,那么可以使用WITH READ ONLY选项完成。
| CREATE OR REPLACE VIEW myview AS SELECT * FROM emp WHERE deptno=10 WITH READ ONLY; |
这时错误提示:“ORA-01733:此处不允许虚拟列”。因为视图就是查询语句,无法对查询语句进行更新。
在实际的开发之中,查询的功能肯定要比数据表更多,那么如果严格的按照数据库的开发标准来定的话,则视图的数量应该远远大于数据表的数量。
111、
同义词
同义词在中国被成为近义词,在之前一直遇见过这样一种查询:
| SELECT SYSDATE FROM dual ; |
在之前强调了,dual是一张虚拟表,但是问题是这张虚拟表是属于那个用户的呢?
| SELECT * FROM tab WHERE tname='DUAL' ; |
经过验证,此张表属于sys用户,但是这个时候有一个问题出现了。调用其他用户对象的时候应该是“用户名.表名称”,但是这个时候为什么没有使用sys.dual,而只是用了dual呢?而这就是同义词的作用,即:dual表示的sys.dual的同义词,而如果用户要想创建同义词的话,可以采用如下的语法完成:
| CREATE [PUBLIC] SONYNOM 同义词的名称 FOR用户名.表名称; |
范例:将scott.emp的表定义为emp的同义词——只能在具备管理员权限的用户下进行
| CREATE SYNONYM emp FOR scott.emp ; |
同义词创建完成之后,那么以后就可以通过emp进行访问了,但是这个时候所创建的同义词并不能被其他用户所访问,例如:现在使用system用户登录,就无法访问了,因为默认情况下创建的同义词并不是公共同义词,所以在创建同义词的时候应该加上一个public选项。
| DROP SYNONYM emp ; CREATE PUBLIC SYNONYM emp FOR scott.emp ; |
但是,同义词这个概念本身是属于oracle自己的应用,所以知道就行了,用处不大。
112、索引
在数据库之中,索引是一种提升数据库操作性能的手段。
索引的操作实际上也是基于ROWID(物理地址)的一种应用,由于索引属于分析范畴的内容,所以下面首先对之前的若干查询做一些性能上的分析,例如,现在要求查询出所有工资小于1600的雇员信息;
| SELECT * FROM emp WHERE sal<1600 ; |
但是在默认情况下,所有的数据都将采用逐行扫描的方式完成,即:如果说现在一张数据表中有50W条记录,那么这个过滤条件就要过滤50W次,而此时会出现这样一个问题,如果假设说现在只有前30W条数据会满足这样的查询要求,但是后面的20W条不再有满足此条件的数据存在,那么这种查询肯定就有问题了。
现在的工资数据:1600、1250、1250、2850、2975、1500、3000、1300、950、800、3000、9000、5000、1100。
BT(Binary Tree,二叉树),如果把这些数据作为树的形式出现呢?树的形成规律:取第一个数据作为根节点,比根节点小的数据放在左子树,比根节点大的数据放在右子树,所以按照这个规律来讲,以上的数据可以形成如下的树。
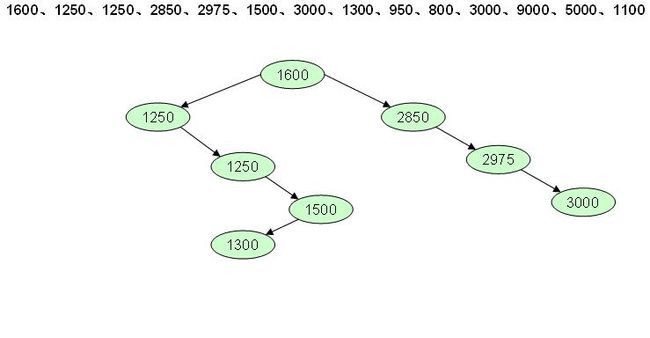
而要想实现这样的功能,那么就可以通过索引的建立完成。
范例:在sal字段上定义一个索引:emp_sal_ind。
| CREATE INDEX emp_sal_ind ON emp(sal) ; |
如果不使用这种方式来创建索引的话,那么如果一个字段上设置了主键或者是唯一约束的话,也会帮助用户自动的进行索引的创建。
在本程序之中,这棵在数据库之中自动形成的树就变为了整个程序的操作命脉,如果要想实现性能的提升,必须时刻将这棵树的内容进行维护,那么如果说现在一张数据表的SAL字段需要被频繁的修改的话呢?就意味着树的关系始终要变化着,那么反而会造成性能的降低,所以索引只是一种相对提升性能的手段,面对大数据量的时候没有什么特别好的方法可以准确的提升性能。
但是在Oracle之中提供了十多种索引,本次所讲解的只是一种最为简单的B*Tree索引,还有像反向索引、位图索引、函数索引等等。
113、用户管理
SQL语法之中的最后一个部分就是DCL,属于数据库控制语言,但是这个控制语言主要定义的是进行权限的分配,即:在DCL之中只存在两种语法GRANT(授予)、REVOKE(回收),但是如果要想操作这两个命令,必须首先要定义出用户,因为如果没有用户,则授权也没有意义了。
而用户的部分在oracle之中也被称为一个对象,即,所谓的用户管理,实际上还是DDL有关,但是这部分的操作绝对是由DBA负责的,所以要想完成全部的功能必须使用超级管理员或具备同等权限的管理员system登录;
| CONN sys/change_on_install AS SYSDBA ; |
范例:现在创建一个新的用户:dog/wangwang
| CREATE USER dog IDENTIFIED BY wangwang ; |
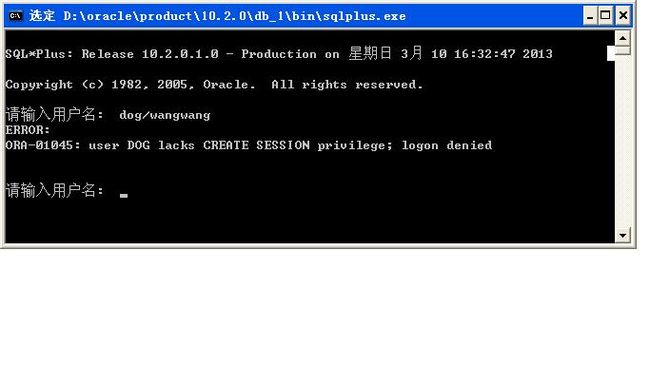
现在一个新的用户就创建完成了,而后使用此用户登录一个新的sqlplus,但是此时会提示dog用户说是没有“CREATE SESSION”,创建SESSION的权限,在Oracle之中每一个连接到数据库上的用户都使用一个SESSION表示,所以如果没有创建SESSION的权限就表示无法进行数据库登录。
范例:为dog用户授予可以创建SESSION的权限
| GRANT CREATE SESSION TO dog ; |
现在的dog用户已经可以进行登录操作了,但是登之后最基本的是要创建一张数据表。
范例:使用dog用户创建一个序列和一张数据表
| DROP TABLE member ; DROP SEQUENCE myseq ; CREATE SEQUENCE myseq ; CREATE TABLE member( mid NUMBER PRIMARY KEY , name VARCHAR2(50) ) ; |
现在给出的提示是权限不足,无法创建,那么只能继续授权,既然是创建表和创建序列,那么:
| GRANT CREATE SEQUENCE TO dog ; |
| GRANT CREATE TABLE TO dog ; |
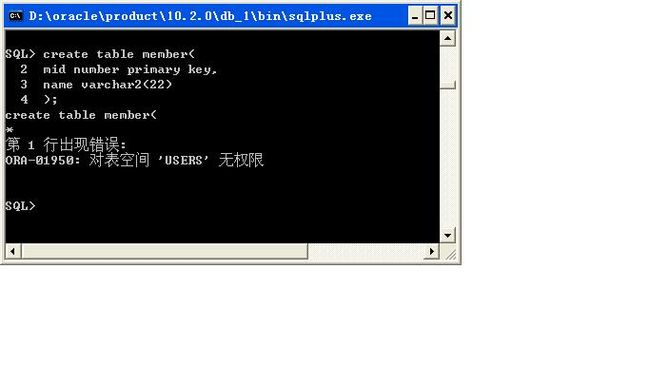
但是此时发现又出现了一个表空间的问题,
在Oracle中所有的数据表都是保存在硬盘上,但是不是每张数据表都保存在硬盘上,而是表空间保存在硬盘上,而数据表保存在表空间中;
如果把硬盘比作一间屋子的话,那么表空间就是每一个书柜,每张表就表示柜子上的一本书。
所谓的表空间指的是保存表的数据区,在一个数据库里面有多个表空间,可以把这个表空间理解为图书馆中的每一个书柜,而每一本书都表示一张数据表,所以数据表是受到表空间的管理。因为没有把表空间的操作权限给dog用户,所以用户仍然无法创建表,因为没有地方可以保存。在之前所有的表空间都默认设置到了USERS之中,所以如果没有表空间的权限,那么一定就没有数据表的创建权限,但是这样一来就会出现一个问题:每次操作之前都要去申请权限太麻烦了,所以在Oracle之中为了简化这样的操作,专门提供了两个角色:RESOURCE、CONNECT,每种角色里面包含若干种权限,简单的操作就可以将这两个角色授予用户。
| GRANT RESOURCE,CONNECT TO dog ; |
此时dog用户就已经可以使用了。但是一旦有了用户的问题,那么一些麻烦事也就该来了。一般而言,在一个系统之中,只要是存在了用户的操作,那么一定会有一个与之匹配的用户管理系统。
范例:dog用户的密码丢了,肯定希望管理员可以重置一个,这种修改用户的操作肯定使用ALTER指令完成。
| ALTER USER dog IDENTIFIED BY miaomiao ; |
但是,既然要重置密码,那么这个密码肯定不是用户所熟悉的,往往用户第一次登录之后都要求修改密码,所以可以使用密码失效的方式完成。
范例:让dog的密码失效,之后dog用户再次登录的时候会提示更改口令
| ALTER USER dog PASSWORD EXPIRE ; |
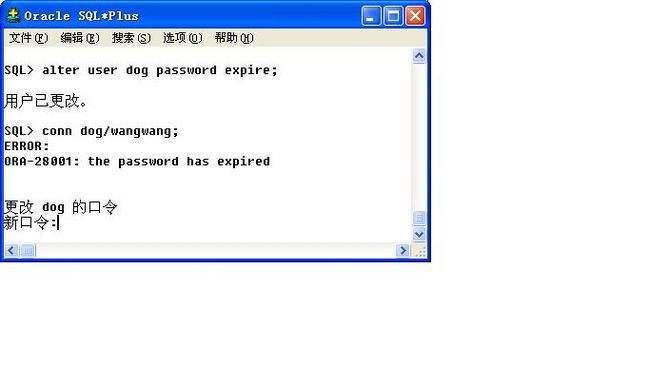
而后也可以通过以下两个指令来锁定用户:
| ALTER USER dog ACCOUNT LOCK ; |
| ALTER USER dog ACCOUNT UNLOCK ; |
在之前说过,不同的用户可以互相进行数据表的访问,那么现在希望dog用户可以去访问scott.emp表数据。
范例:使用dog用户查询scott.emp
| SELECT * FROM scott.emp ; |
但是发现这个时候并不能够访问scott.emp表,如果现在一个用户要想访问其他用户的数据表,则必须为此用户进行授权的操作,而权限主要有四种:INSERT、DELETE、UPDATE、SELECT,CRUD(增删改查)。
范例:将scott.emp表中的SELECT、INSERT两个权限授予dog用户
| GRANT SELECT,INSERT ON scott.emp TO dog ; |
范例:从dog用户之中回收权限
| REVOKE SELECT,INSERT ON scott.emp FROM dog ; |
| REVOKE CREATE SESSION,CREATE TABLE,CREATE SEQUENCE FROM dog ; |
| REVOKE CONNECT,RESOURCE FROM dog ; |
权限回收之后,dog用户基本上就没用了,删除用户肯定使用DROP语句完成。
| DROP USER dog CASCADE ; |
118、数据库备份
3.6.1、数据导出和导入
数据的导出和导入指的是一个用户下的所有数据,下面分步完成。
1、 数据的导出
·如果要想导出数据,那么肯定要设置一个路径,现在在d盘下建立一个backup的文件夹,md backup;
·进入到此目录之中:cd backup;
·输入exp指令,表示要进行数据的导出;
·输入用户名和密码;(一直按回车)
·输入导出文件名称,默认是:EXPDAT.DMP;
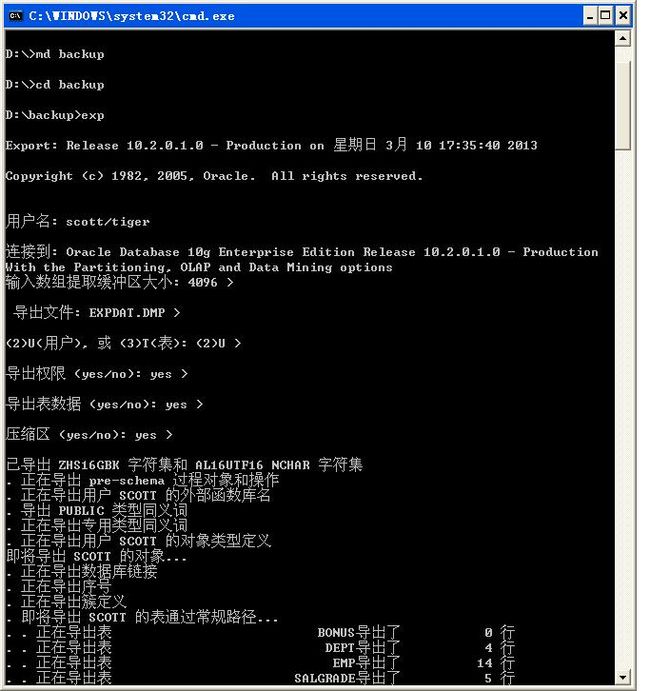
2、 数据的导入
·进入到备份文件所在的目录:d:\backup;
·输入imp指令;
·导入文件,默认名称是:EXPDAT.DMP;
·导入整个导出文件 (yes/no): no > yes;
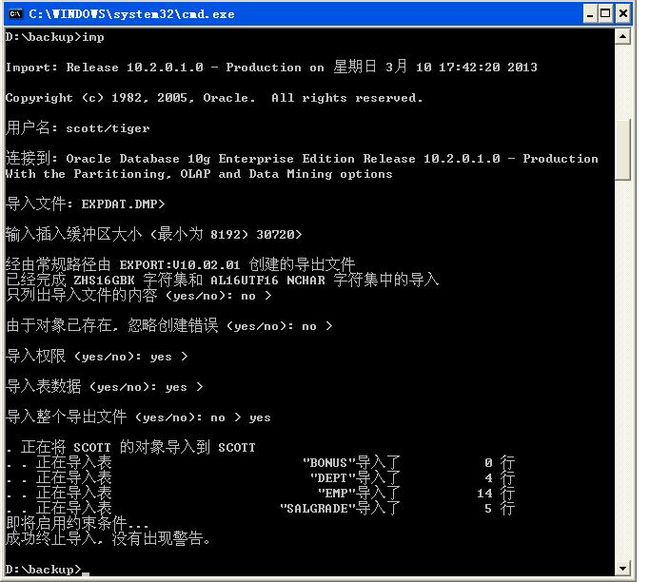
这种操作最大的问题是在于要将每一条数据都保存在文件之中,如果说现在一个用户下的数据表内容较大,这种方式必定要耗费很长的时间,而且在这段时间内用户绝对不允许操作,事务处理。为了解决这个问题,可以在夜深人静时进行,或者是进行分区备份。
3.6.2、数据库的冷备份
在数据操作中,有可能有些用户不会进行事务的提交,那么在这种情况下很有可能无法进行完整的备份操作(用户没有提交的事务不会备份),所谓的冷备份指的是在关闭数据库实例的情况下进行数据库备份的操作的实现。
比如:网游公司维护网游的时候用户无法登陆,这时就是在进行数据的冷备份。
所谓的冷备份严格来讲称为归档备份,也是在公司内部的企业项目使用最多的一种形式,要求将数据库的实例关闭。
数据库的冷备份严格来讲所备份的内容是数据库的以下几个核心文件:
·控制文件,控制整个oracle数据库的实例服务的核心文件,可以通过“v$controlfile”找到;
·重做日志文件,当出现灾难时,可以进行及时的数据恢复,通过“v$logfile”找到;
·数据文件,所有的数据文件都在表空间里,通过“v$datafile”、“v$tablespace”;
·每一个数据库的pfile文件,通过SHOW PARAMETER pfile找到;
从实际的Oracle部署来讲,所以的文件为了达到IO的平衡操作,要分别保存到不同的硬盘上。
之所以要通过数据字典查找这些文件的路径,主要的原因是在实际的数据库运行之中,都是采用磁盘阵列的方式进行数据存储的,但是要想操作必须具备超级管理员权限,只有sys用户,所以下面可以按照如下的步骤进行。
第一步:使用超级管理员登录
| CONN sys/change_on_install AS SYSDBA ; |
第二步:查找所有控制文件的路径
| SELECT * FROM v$controlfile ; |
第三步:找到重做日志文件
| SELECT * FROM v$logfile ; |
第四步:找到表空间文件
| SELECT * FROM v$datafile ; |
| SELECT * FROM v$tablespace ; |
第五步:找到pfile文件(指的是Oracle的启动文件),用笔记本打开如下:
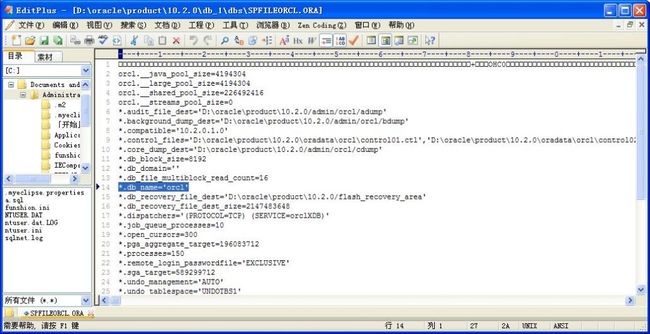
| SHOW PARAMETER pfile ; |
第六步:停止数据库的实例运行(强制停止)
| SHUTDOWN IMMEDIATE |
第七步:将所有的文件拷贝到一个备份目录之中保存
第八步:恢复执行
| STARTUP |
但是在有些情况下,不能关闭的数据库也是有的,例如:银行、电信,这种操作称为7*24运行的备份为热备份。
3.7、数据库设计范式(重点理解)
对于数据库而言,在开发之中其所承担的功能就是进行数据的存储,而如何有效的进行存储,并且如何可以方便的进行数据表的维护,就需要遵守一些标准的设计范式,但是对于设计范式更多的只是参考,而实际的开发之中,如果数据量较大的情况下,优先考虑的避免多表查询。
3.7.1、第一范式
第一范式的特点就是:数据表中的每个字段的内容不可再分。
| CREATE TABLE member ( mid NUMBER PRIMARY KEY , name VARCHAR2(50) NOT NULL , contact VARCHAR2(200) ) ; |
contact表示的是一个成员的联系方式,但是每一个人的联系方式都应该包含:邮政编码、地址、城市、城区、手机、固话、qq、email等等。所以现在这个字段发现可以继续再分,所以不满足于第一范式,那么下面应该做出如下的调整。
| CREATE TABLE member ( mid NUMBER PRIMARY KEY , name VARCHAR2(50) NOT NULL , address VARCHAR2(200) , zipcode VARCHAR2(8) , qq VARCHAR2(20) , mobile VARCHAR2(50) ) ; |
现在的设计符合于第一设计范式,因为每个字段的内容不可再分了,但是,从另外一点也需要注意一下问题。
·在中国姓名是不拆分的,但是在国外是first name、last name,这个要根据国情;
·在设计一个人生日的时候,不能分为:生日年、生日月、生日天;
| CREATE TABLE member ( mid NUMBER PRIMARY KEY , name VARCHAR2(50) NOT NULL , birthday_year NUMBER , birthday_months NUMBER , birthday_day NUMBER) ; |
因为在数据库之中,已经提供了专门的DATE数据类型,所以在使用的时候一切的操作要以数据库所支持的数据类型为主。
3.7.2、第二范式:多对多关系
所谓的第二范式,表中不存在非关键字段对任意一侯选关键字段的部分函数依赖;它应该主要分为两种情况。
情况一:函数依赖关系
例如,现在要设计一张定单表,如果现在按照如下的方式设计:
| CREATE TABLE orders ( oid NUMBER PRIMARY KEY , product VARCHAR2(60) , unitprice NUMBER , amonut NUMBER , allprice NUMBER ) ; |
这个时候很明显字段之间有了函数关系:allprice = unitprice * amount;
情况二:字段依赖关系
例如,现在要求设计一个数据库,具体描述如下:定义一个学生选课的操作,每个学生针对于每个课程有自己的成绩(一个学生可以参加多门课程,一门课程可以有多个学生参加),则现在如果按照第一范式的要求,设计如下。
| CREATE TABLE studentcourse( stuid NUMBER PRIMARY KEY , stuname VARCHAR2(50) NOT NULL , cname VARCHAR2(50) NOT NULL , credit NUMBER , score NUMBER ) ; |
本张表设计现在符合于第一设计范式,但是也有问题,为了帮助大家理解,下面编写几个测试数据。
| INSERT INTO studentcourse(stuid,stuname,cname,credit,score) VALUES (1,'张三','java',2,80) ; INSERT INTO studentcourse(stuid,stuname,cname,credit,score) VALUES (2,'李四','java',2,90) ; INSERT INTO studentcourse(stuid,stuname,cname,credit,score) VALUES (1,'张三','Oracle',3,89) ; |
·既然每一个学生可以参加多门课程,则在编写数据的时候,肯定始终学生的信息要完整,那么主键的设置?
·学生或课程的数据重复,如果说现在某一门课的学分修改了,而经过常年的积累,这门课已经有5W个学生参加,这更新要浪费大量的资源;
·如果一门课程没有一个学生参加,那么意味着这门课程就彻底消失了。
所以,第一范式,现在根本就无法满足于本次的操作要求,所以要使用第二范式,让彼此的字段的依赖最少。
| CREATE TABLE student ( stuid NUMBER PRIMARY KEY , stuname VARCHAR2(50) NOT NULL ) ; CREATE TABLE course ( cid NUMBER PRIMARY KEY , cname VARCHAR2(50) NOT NULL , credit NUMBER ) ; CREATE TABLE studentcourse( stuid NUMBER REFERENCES student(stuid) ON DELETE CASCADE , cid NUMBER REFERENCES course(cid) ON DELETE CASCADE , score NUMBER ) ; |
这样一来在进行更新的时候或者是查找的时候就不会受到数据的限制。
3.7.3、第三范式 一对多
例如,现在要完成这样的一个要求:一个学校有多个学生,每个学生只能在一个学校学习,如果现在使用第一范式,则设计如下:
| CREATE TABLE schoolstudent( stuid NUMBER PRIMARY KEY , stuname VARCHAR2(50) NOT NULL , school VARCHAR2(50) NOT NULL , ... 一系列的学校信息 ) ; |
本操作符合于第一设计范式,但是会存在如下问题:
·学校信息重复了,则在更新记录的时候麻烦;
·如果一个学校没有一个学生,这个学校就消失了。
所以,现在第一设计范式无法解决问题,那么如果采用第二范式可以满足于这种要求,但是第二范式会附加一个新功能:一个学生可以同时在多个学校学习,这样又不符合于设计的要求,那么在这种情况下就可以使用第三范式。
| CREATE TABLE school( sid NUMBER PRIMARY KEY , name VARCHAR2(50) ) ; CREATE TABLE student( stuid NUMBER PRIMARY KEY , stuname VARCHAR2(50) NOT NULL , sid NUMBER REFERENCES school(sid) ) ; |
在之前所学习的dept-emp就属于第三范式的范畴,而且从开发的角度而言,第三范式使用的是最多的。
以上的三种范式都只是参考,这种设计可以方便的进行数据表的维护,但是开发中不管多好的设计,如果碰到了海量数据,那么一样没戏。
3.8、数据库设计工具(重点)
对于数据库的设计而言,往往会使用一些设计工具完成。其中比较著名的:Sybase PowerDesigner,现在的版本是15。
在数据库领域,最早的时候有两个数据库:Sybase、Informix,在当时都属于大型数据库成员,但是后来这两家公司分别被Microsoft和IBM收购,而后根据这两个数据库衍生出了今天的两个数据库:SQL Server、DB2;
但是在数据库的设计领域,Sybase工具一直很好使用,而且包括oracle虽然它也提供了设计工具,但是一般使用来讲比较少一些。
打开Power Designer工具之后,那么首先要建立一个物理数据模型。
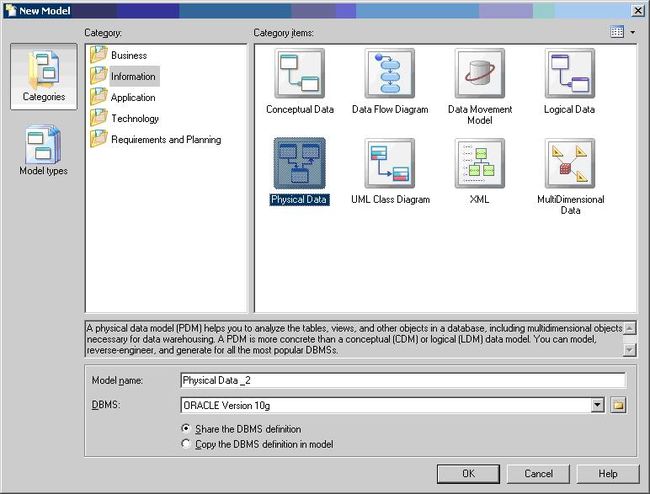
而且使用这种工具设计数据库的最大好处在于,可以方便的生成数据库创建脚本。CTRL + G;
建议,以后如果是使用此工具动态生成的数据库脚本,一定要修改为简便的形式,之前讲解的样子。
但是,此工具为了方便用户的时候,也提供了另外一个功能,可以直接导入已有数据库的数据表的模型,而要想实现这一操作就必须利用Windows的ODBC技术完成。
而要配置ODBC数据源,则必须保证数据库服务的监听服务和数据库的实例服务打开。
配置过程:【管理工具】è【ODBC数据源】è【配置系统DSN】è添加。
在添加Oracle数据源的时候,要先给出数据库的驱动程序,在oracle安装完成之后,此驱动程序会自动的到ODBC之中进行注册。
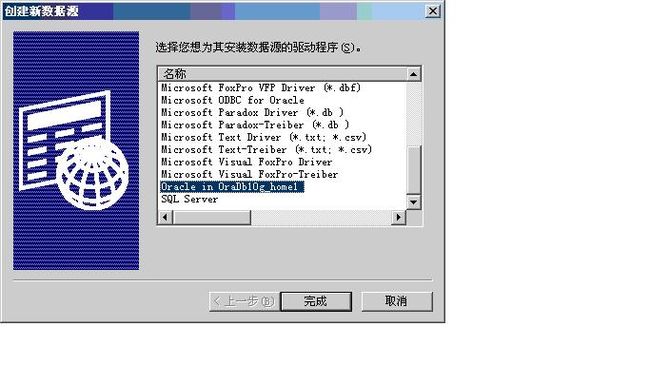
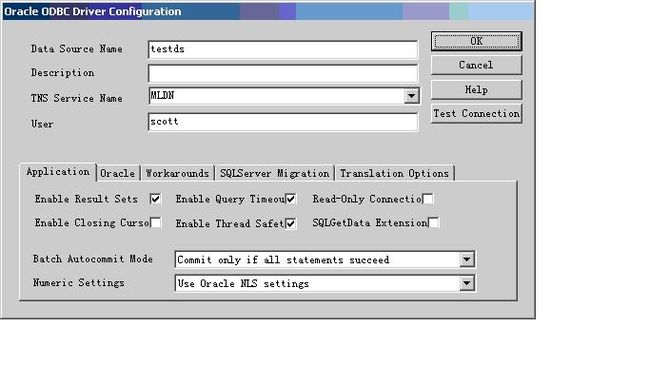
配置完成之后,直接利用PowerDesigner中的工具进行ODBC的连接。
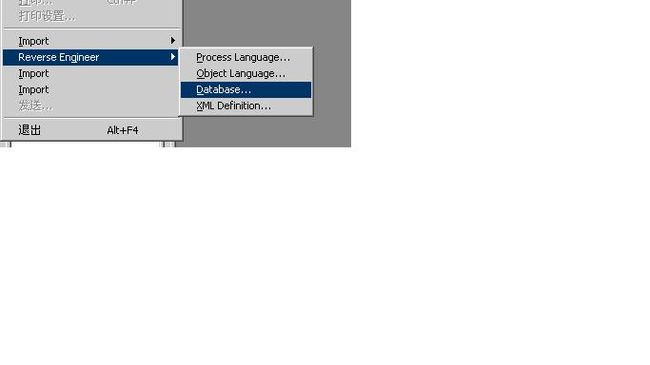
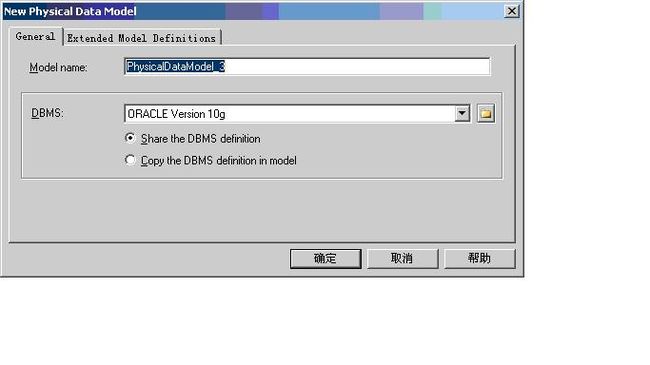
此时会列出所有允许导入的数据表。