RCNN系列实验的PASCAL VOC数据集格式设置
我们在做RCNN系列的实验时,往往需要把数据集的格式设置为和PASCAL VOC数据集一样的格式,其实当然也可以修改读取数据的代码,只是这样更为麻烦,自己的数据格式变了又得修改。
首先以VOC2008为例,先看一下VOCdevkit的文件夹结构:
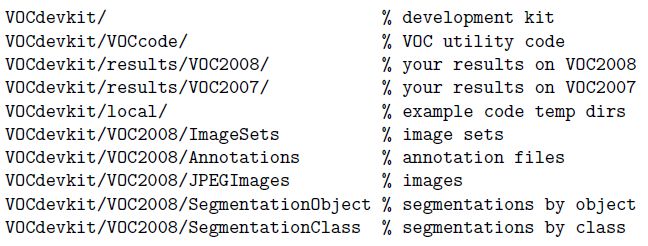
VOCdevkit中还有一个devkit_doc.pdf文件,关于PASCAL VOC数据集的所有信息都可以在里面找到。
我们也按照这样的树形结构建好文件夹,把VOC2007和VOC2008换成自己数据集的名字(保留一个即可),local下面也建一个自己数据集的名字的文件夹。SegmentationObject和SegmentationClass就不需要了。
我们检测任务所用的数据集只需要JPEGImages、Annotations、ImageSets文件夹。前提是自己要有数据,即图片和标注好的类别名与坐标。
JPEGImages
把自己所有类别的图片放到JPEGImages文件夹下,图片名按类似于000001.jpg、000002.jpg…的格式,不一定非要按数字顺序,但是一定不要重名,最好归一化一下图片的尺寸。
Annotations
VOCcode中的代码已经提供了写注释文件的东西,我的writexml是仿照VOCdevkit中的VOCwritexml来写的。假设我的标注都写到了txt文件里面,且txt文件与相应的图片同名,形如:
第一行是类别名,第二行是目标的坐标(这里每张图像只包含一个目标,多目标的标注是差不多的)。下面是写Annotations的代码
%writeanno.m
path_image='JPEGImages/';
path_label='labels/';%txt文件存放路径
files_all=dir(path_image);
for i = 3:length(files_all)
msg = textread(strcat(path_label, files_all(i).name(1:end-4),'.txt'),'%s');
clear rec;
path = ['./Annotations/' files_all(i).name(1:end-4) '.xml'];
fid=fopen(path,'w');
rec.annotation.folder = 'lml';%数据集名
rec.annotation.filename = files_all(i).name(1:end-4);%图片名
rec.annotation.source.database = 'The lmls Database';%随便写
rec.annotation.source.annotation = 'The lmls Database';%随便写
rec.annotation.source.image = 'lml';%随便写
rec.annotation.source.flickrid = '0';%随便写
rec.annotation.owner.flickrid = 'I do not know';%随便写
rec.annotation.owner.name = 'I do not know';%随便写
img = imread(['./JPEGImages/' files_all(i).name]);
rec.annotation.size.width = int2str(size(img,2));
rec.annotation.size.height = int2str(size(img,1));
rec.annotation.size.depth = int2str(size(img,3));
rec.annotation.segmented = '0';%不用于分割
rec.annotation.object.name = msg{1};%类别名
rec.annotation.object.pose = 'Unspecified';%不指定姿态
rec.annotation.object.truncated = '0';%没有被删节
rec.annotation.object.difficult = '0';%不是难以识别的目标
rec.annotation.object.bndbox.xmin = msg{2};%坐标x1
rec.annotation.object.bndbox.ymin = msg{3};%坐标y1
rec.annotation.object.bndbox.xmax = msg{4};%坐标x2
rec.annotation.object.bndbox.ymax = msg{5};%坐标y2
writexml(fid,rec,0);
fclose(fid);
end%writexml.m
function xml = writexml(fid,rec,depth)
fn=fieldnames(rec);
for i=1:length(fn)
f=rec.(fn{i});
if ~isempty(f)
if isstruct(f)
for j=1:length(f)
fprintf(fid,'%s',repmat(char(9),1,depth));
a=repmat(char(9),1,depth);
fprintf(fid,'<%s>\n',fn{i});
writexml(fid,rec.(fn{i})(j),depth+1);
fprintf(fid,'%s',repmat(char(9),1,depth));
fprintf(fid,'</%s>\n',fn{i});
end
else
if ~iscell(f)
f={f};
end
for j=1:length(f)
fprintf(fid,'%s',repmat(char(9),1,depth));
fprintf(fid,'<%s>',fn{i});
if ischar(f{j})
fprintf(fid,'%s',f{j});
elseif isnumeric(f{j})&&numel(f{j})==1
fprintf(fid,'%s',num2str(f{j}));
else
error('unsupported type');
end
fprintf(fid,'</%s>\n',fn{i});
end
end
end
endImageSets
ImageSets里只需要用到Main文件夹,而在Main中,主要用到4个文件:
- train.txt 是用来训练的图片文件的文件名列表
- trianval.txt是用来训练和验证的图片文件的文件名列表
- val.txt是用来验证的图片文件的文件名列表
- test.txt 是用来测试的图片文件的文件名列表
我们希望训练集、验证集、测试集的分别是随机的,下面是实现随机选取样本集合与写txt文件的代码:
%writetxt.m
file = dir('Annotations');
len = length(file)-2;
num_trainval=sort(randperm(len, floor(9*len/10)));%trainval集占所有数据的9/10,可以根据需要设置
num_train=sort(num_trainval(randperm(length(num_trainval), floor(5*length(num_trainval)/6))));%train集占trainval集的5/6,可以根据需要设置
num_val=setdiff(num_trainval,num_train);%trainval集剩下的作为val集
num_test=setdiff(1:len,num_trainval);%所有数据中剩下的作为test集
path = 'ImageSets\Main\'; fid=fopen(strcat(path, 'trainval.txt'),'a+');
for i=1:length(num_trainval)
s = sprintf('%s',file(num_trainval(i)+2).name);
fprintf(fid,[s(1:length(s)-4) '\n']);
end
fclose(fid);
fid=fopen(strcat(path, 'train.txt'),'a+');
for i=1:length(num_train)
s = sprintf('%s',file(num_train(i)+2).name);
fprintf(fid,[s(1:length(s)-4) '\n']);
end
fclose(fid);
fid=fopen(strcat(path, 'val.txt'),'a+');
for i=1:length(num_val)
s = sprintf('%s',file(num_val(i)+2).name);
fprintf(fid,[s(1:length(s)-4) '\n']);
end
fclose(fid);
fid=fopen(strcat(path, 'test.txt'),'a+');
for i=1:length(num_test)
s = sprintf('%s',file(num_test(i)+2).name);
fprintf(fid,[s(1:length(s)-4) '\n']);
end
fclose(fid);最后,在训练时要把VOCCode/VOCinit.m中的VOCopts.dataset即数据集名改为自己的数据集名字,VOCopts.classes即类别名改为自己的类别名字。
此外多说一个RCNN系列实验使用数据集的问题,有时候测试的AP值总显示results为0,发现问题在imdb_eval_voc.m中,改了数据集名字后得不到它想要的年份信息,就不会算AP值,因此也做了一点修改:

代码风格不好,请高手们尽情鄙视。