高性能MySql进化论(一):数据类型的优化_上
原文地址:http://blog.csdn.net/eric_sunah/article/details/10722285
在数据库的性能调优的过程中会涉及到很多的知识,包括字段的属性设置是否合适,索引的建立是否恰当,表结构涉及是否合理,数据库/操作系统 的设置是否正确…..其中每个topic可能都是一个领域。
在我看来,在数据库性能提升关键技术中,对字段的优化难度相对较低且对性能的影响也非常的大。由于MySQL支持的数据类型比较多,且每个类型都有其独特的特性,但是有时候在选择一个具体的数据类型时,往往都是随意的选择一个能用的类型,而不会考虑到这个类型是否是最优的。在具体的类型描述之前,先来看一些针对数据类型选择的主要原则:
a) 尽量选择占用空间小的类型
因为小的类型无论是在磁盘,还是在内存中占用的空间都是小的,在进行查询或者排序是临时表要求的空间也会相对较少。在数据量比较小的时候可能感觉不到,但是当数据量比较大时,这个原则的重要性可能就会得到显现。
例如,有一张“商品信息”表,记录为2000万条,这张表有个 “剩余商品数量”(COUNT)的字段,一般而言 SMALLINT (len:16 range:0-65535)已经足够表达这个字段,可是如果你在设计的过程中用了BIGINT(len:64 range:0-18446744073709551615)来表达,虽然说程序可能正确的运行,但是这一个字段将会额外的增加大概95M的磁盘存储空间(64-16)/8*20,000,000 Bytes),另外在做数据选择和排序时仅仅这一个字段就会增加你95M的内存消耗,基于以上行为的影响,数据库的Performance必然是会被影响的
这里说的尽量小的前提是确保你将要选择的类型可以满足日后业务发展的需求,因为在数据量比较大的时候做表结构的更新是个非常缓慢而且麻烦的事情。
b) 尽量选择简单/恰当的类型
在对表进行选择以及排序的时候,对于简单的类型往往只需要消耗较少的CPU时钟周期。例如,对于MySql server而言,整数类型值的Compare往往会比字符串类型值的Compare简单且快,所以当你需要对特定的表进行排序时应该尽量选择整数类型作为排序的依据
c) 尽量将字段设置为NOTNULL
一般情况下,如果你没有显示的制定一个字段为NULL,那么这个字段将会被数据库系统认为是NULLABLE, 系统的这种默认行为将会导致以下三个问题
(1) Mysql服务器自身的 查询优化功能将会受影响
(2) Mysql针对null值的字段需要额外的存储空间以及处理
(3) 如果一个null值是索引的一部分,那么索引的效果也会收到影响
由于这个原则对于数据库性能提升的作用不是很大,所以对于已经存在的DB schema,其存在NULLABLE字段或者是索引为NULLABLE的,也不用专门的去修改它,但是对于新设计的DB或者索引需要尽量遵守这个原则。
介绍完了数据类型选择的原则后,接下来将会介绍Mysql中常见的数据类型以及在性能优化方面需要注意的地方。
· 整数
在Mysql 的整数家族成员中主要包括TINYINT(8bit), SMALLINT(16bit), MEDIUMINT(24bit), INT(32bit), or BIGINT(64bit)。
对于有符号整数而言这些类型的存储范围为(-2(n-1) ,2(n-1)-1),对于无符号数而言表达的范围是(0,2n-1),对于数据库而言有符号数和无符号数占用相同的存储空间,所以在选择类型的时候可以只考虑数的区间,而不用考虑是signed还是unsigned
Mysql允许你在定义整数类型时指定他的宽度,例如 INT(10)。INT(10) 对于Client/CMD Line的输出是有区别的,但在Mysql Server看来实际的存储空间/计算消耗/数字范围 INT(10)与INT(32)没有任何的区别。
· 小数
在Mysql中小数家族的数据类型主要包括FLOAT(4Bytes),DOUBLE(8Bytes),从这两种类型的存储空间可以看出小数的存取比整数需要消耗更多的空间,所以除非必须,否则应该尽量避免使用小数的类型
创建小数类型的字段时,你可以使用FLOAT(10,3)的方式来指定小数的精度,>=Mysql 5.0的版本中最大的精度支持到小数点后65位。
由于数据库采用Binary Array String的方式来存储小数点后面的数字,所以你要求的精度越高,存储空间/计算的CPU时钟可能消耗的也就越高。
虽然使用小数可能会消耗更多的存储空间以及CPU资源,而且对于早期的Mysql版本还会出现当两个小数参与计算时精度丢失的情况,但是在很多情况下它又是必须的,例如在金融领域中关于金额的存储。在很多情况下为了减少存储的开销以及保证精度的准确性,往往会把小数扩大至整数存储在数据库中,而在Application中再进行小数的转换以及计算,例如 某个用户的账户余额还剩下999.35元,那么在数据中存储的金额为99935分,银行的处理程序拿到99935分后会先转换成999.35元,然后再进行相应的处理
· 字符串
不管对于哪门语言而言,字符串都是一个比较重要且复杂的类型,这个规律对于MYSQL同样适用
在MYSQL中主要包括VARCHAR以及CHAR两种字符串类型,对于这两种字符串类型在磁盘以及内存中存储方式是由Storage engine决定的,且不同的storage engine可能会有不同的存储方式。一般情况下对于一种storage engine 而言,在磁盘以及内存中的存储方式也是不同的,当数据在磁盘与内存之间转移时,storage engine将会负责把数据进行转换
VARCHAR
首先需要指出的是Mysql是用variable length的方式来来存储VARCHAR,相对于fixed length,这种方式对存储空间采取的策略是“用多少,要多少”,是一种比较节省空间的存储方案,在没有特殊需求的情况下可以作为默认的类型
VARCHAR之所以可以实现定长,是因为每个VARCHAR值都会附加一个 长度为1-2byte 的长度指示器,例如当需要存储“I Love Java”时,底层的存储内容为 “11I Love Java”,其中11(1 Byte)代表长度。当需要存储内容的长度为1000时长度指示器就需要两个字节。因为2bytes的最大值为216,所以当存储的字符串超过这个长度时,会出现不可预料的异常,这时就需要使用CLOB来存储这种超长的字符串。
在MYSQL的不同版本中,针对VARCHAR字段的结尾空格处理也有所不同
Version>=5.0 保留结尾的空格
Version<=4.1 截取空格
以MYSQL 5.6 为例:
▪ 使用VARCHAR(5) 和VARCHAR(200) 存储’hello’的空间开销是一样的。那么使用更短的列有什么优势吗?
事实证明有很大的优势。更大的列会消耗更多的内存,因为MySQL 通常会分配固定大小的内存块来保存内部值。尤其是使用内存临时表进行排序或操作时会特别糟糕。在利用磁盘临时表进行排序时也同样糟糕。
所以最好的策略是只分配真正需要的空间。
CHAR
CHAR类型与VARCHAR类型最大的区别在于它是定长的。同时相比于VARCHAR它主要有以下特点
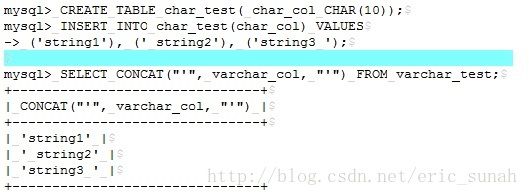
1)在所有的MYSQL版本中,末尾的空格都会被截取

2)对于 一些短的且是长度基本相同的字段是个不错的选择例如MD5,ID Number
3)对于经常需要变更的字段,CHAR类型会更高效
4)对于一些超短的字段,也非常的节约空间。例如你保存“Y”或者是“N”,用CHAR只需要一个字节,而用VARCHAR 的话需要两个字节(1byte length+1 byte value)
对于定长的CHAR,Mysql server会根据其定义的长度采用补空格的方式来分配足够大的存储空间。有一点需要注意的是 VARCHAR/CHAR在进行“补空格”以及“去结尾空格”的操作是由Mysql server来实现的,与Storage engine 无关
DATE/TIMESTAMP, BLOB/CLOB/TEXT, ENUM,BIT 这几种类型会在下篇博客中进行讲解