台湾国立大学机器学习基石.听课笔记(第十一讲):Linear Models of Classification
台湾国立大学机器学习基石.听课笔记(第十一讲)
:Linear Models of Classification
:Linear Models of Classification
在上一讲中,我们了解到线性回归和逻辑斯蒂回归一定程度上都可以用于线性二值分类,因为它们对应的错误衡量(square error, cross-entropy) 都是“0/1 error” 的上界。
1,Linear Models for Bineary Classification(三个模型的比较)
1.1Error Function分析
本质上讲,线性分类(感知机)、线性回归、逻辑斯蒂回归都属于线性模型,因为它们的核心都是一个线性score 函数:
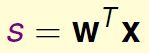
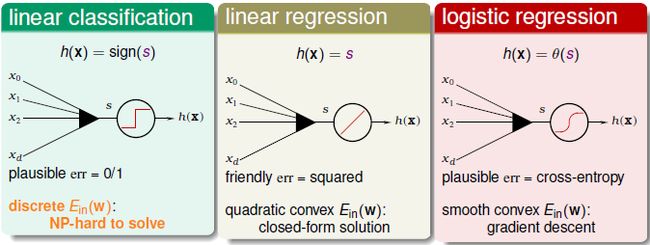
只是三个model 对其做了不同处理:
线性分类对s 取符号;线性回归直接使用s 的值;逻辑斯蒂回归将s 映射到(0,1) 区间。
线性分类对s 取符号;线性回归直接使用s 的值;逻辑斯蒂回归将s 映射到(0,1) 区间。
为了更方便地比较三个model,对其error function 做一定处理:

这样,三个error function 都变成只有y*s 这一项“变量”。
通过曲线来比较三个error function (注意:cross-entropy 变为以2为底的scaled cross-entropy)
通过曲线来比较三个error function (注意:cross-entropy 变为以2为底的scaled cross-entropy)

很容易通过比较三个error function 来得到分类的0/1 error 的上界:
这样,我们就理解了通过逻辑斯蒂回归或线性回归进行分类的意义。
1.2优缺点比较
线性分类(PLA)、线性回归、逻辑斯蒂回归的优缺点比较:(1)PLA
优点:在数据线性可分时高效且准确。
缺点:只有在数据线性可分时才可行,否则需要借助POCKET 算法(没有理论保证)。
(2)线性回归
优点:最简单的优化(直接利用矩阵运算工具)
缺点:y*s 的值较大时,与0/1 error 相差较大(loose bound)。
(3)逻辑斯蒂回归
优点:比较容易优化(梯度下降)
缺点:y*s 是非常小的负数时,与0/1 error 相差较大。
实际中,逻辑斯蒂回归用于分类的效果优于线性回归的方法和POCKET 算法。线性回归得到的结果w 有时作为其他几种算法的初值。
2,随机梯度下降 (Stochastic Gradient Descent)
传统的随机梯度下降更新方法: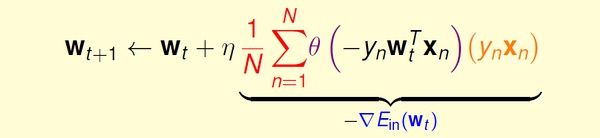
每次更新都需要遍历所有data,当数据量太大或者一次无法获取全部数据时,这种方法并不可行。
我们希望用更高效的方法解决这个问题,基本思路是:只通过一个随机选取的数据(xn,yn) 来获取“梯度”,以此对w 进行更新。这种优化方法叫做随机梯度下降。
我们希望用更高效的方法解决这个问题,基本思路是:只通过一个随机选取的数据(xn,yn) 来获取“梯度”,以此对w 进行更新。这种优化方法叫做随机梯度下降。
这种方法在统计上的意义是:进行足够多的更新后,平均的随机梯度与平均的真实梯度近似相等。
注意:在这种优化方法中,一般设定一个足够大的迭代次数,算法执行这么多的次数时我们就认为已经收敛。(防止不收敛的情况)
注意:在这种优化方法中,一般设定一个足够大的迭代次数,算法执行这么多的次数时我们就认为已经收敛。(防止不收敛的情况)
3,多类别分类(multiclass classification)
与二值分类不同的是,我们的target有多个类别(>2)。一种直观的解决方法是将其转化为多轮的二值分类问题:任意选择一个类作为+1,其他类都看做-1,在此条件下对原数据进行训练,得到w;经过多轮训练之后,得到多个w。对于某个x,将其分到可能性最大的那个类。(例如逻辑斯蒂回归对于x 属于某个类会有一个概率估计)如果target 是k个类标签,我们需要k 轮训练,得到k 个w。
这种方法叫做One-Versus-All (OVA):

它的最大缺点是,目标类很多时,每轮训练面对的数据往往非常不平衡(unbalanced),会严重影响训练准确性。multinomial(‘coupled’)logistic regression 考虑了这个问题,感兴趣的话自学下吧。
4,另一种多值分类方法
这种方法叫做One-Versus-One(OVO),对比上面的OVA 方法。
基本方法:每轮训练时,任取两个类别,一个作为+1,另一个作为-1,其他类别的数据不考虑,这样,同样用二值分类的方法进行训练;目标类有k个时,需要k*(k-1)/2 轮训练,得到 k*(k-1)/2 个分类器。
预测:对于某个x,用训练得到的k*(k-1)/2 个分类器分别对其进行预测,哪个类别被预测的次数最多,就把它作为最终结果。即通过“循环赛”的方式来决定哪个“类”是冠军。
显然,这种方法的优点是每轮训练面对更少、更平衡的数据,而且可以用任意二值分类方法进行训练;缺点是需要的轮数太多(k*(k-1)/2),占用更多的存储空间,而且预测也更慢。
预测:对于某个x,用训练得到的k*(k-1)/2 个分类器分别对其进行预测,哪个类别被预测的次数最多,就把它作为最终结果。即通过“循环赛”的方式来决定哪个“类”是冠军。
显然,这种方法的优点是每轮训练面对更少、更平衡的数据,而且可以用任意二值分类方法进行训练;缺点是需要的轮数太多(k*(k-1)/2),占用更多的存储空间,而且预测也更慢。

OVA和OVO方法的思想都很简单,可以作为以后面对多值分类问题时的备选方案,并且可以为我们提供解决问题的思路。