汉字转拼音的Oracle函数
前言:
最近处理一个特殊的问题,需要用到汉字自动转换拼音的功能。
解决:
在这里找了不少资料,都是有所缺陷,而且也好像很绕。其实是一个很简单的东东。后来还是自己写了一个函数获取。分享出来,给有需要的XD了。
-------------
这是一个比较简单的汉字转拼音的 Oracle函数写法。
原理是,先将汉字对应的拼音存入一个表格。
然后对这个表格对应的存在的汉字找出其拼音,然后输出。
这样子做,容易维护,而且也容易扩展。如果万一发现哪个字少了,直接增加表格记录即可。
步骤如下:
----建立汉字拼音对照表_表格。
---接着要用Toad工具导入对应的拼音汉字对照表(汉字拼音对照表_IMPORT.xls)。
---Excel文档以及相关资料下载: http://download.csdn.net/detail/samt007/5165175
---PS:用Pl/SQL Developer工具导入好像会报错:ora-01480 trailing null missing from str bind value
---样例:
---后期数据的整理:
---因为存在一个字多个拼音,这个拼音如何抓取的问题。目前抓取的逻辑是抓最大ID的对应的拼音。
----汉字博大精深啊。
---将一些重复的字的拿掉。例如,信=xin。别的拿掉。如果你觉得有需要。
---------------------我是美丽的分隔符-------------------------
函数部分:
最近处理一个特殊的问题,需要用到汉字自动转换拼音的功能。
解决:
在这里找了不少资料,都是有所缺陷,而且也好像很绕。其实是一个很简单的东东。后来还是自己写了一个函数获取。分享出来,给有需要的XD了。
-------------
这是一个比较简单的汉字转拼音的 Oracle函数写法。
原理是,先将汉字对应的拼音存入一个表格。
然后对这个表格对应的存在的汉字找出其拼音,然后输出。
这样子做,容易维护,而且也容易扩展。如果万一发现哪个字少了,直接增加表格记录即可。
步骤如下:
----建立汉字拼音对照表_表格。
CREATE TABLE XYG.XYG_chinese_Spell( chinese_Spell_ID NUMBER NOT NULL,--表格ID chinese_Spell VARCHAR2(50) NOT NULL, -- 汉语拼音 chinese_Word VARCHAR2(4000) NOT NULL -- 汉字堆 ---5 who ,CREATED_BY NUMBER DEFAULT -1 NOT NULL --创建者 ,CREATION_DATE DATE DEFAULT SYSDATE NOT NULL --创建日期 ,LAST_UPDATED_BY NUMBER DEFAULT -1NOT NULL --最后更新人 ,LAST_UPDATE_DATE DATE DEFAULT SYSDATE NOT NULL --最后更新日期 ,LAST_UPDATE_LOGIN NUMBER DEFAULT -1NOT NULL --最后登陆人 ,ATTRIBUTE_CATEGORY VARCHAR2(30) ,ATTRIBUTE1 VARCHAR2(240) ,ATTRIBUTE2 VARCHAR2(240) ,ATTRIBUTE3 VARCHAR2(240) ,ATTRIBUTE4 VARCHAR2(240) ,ATTRIBUTE5 VARCHAR2(240) ,ATTRIBUTE6 VARCHAR2(240) ,ATTRIBUTE7 VARCHAR2(240) ,ATTRIBUTE8 VARCHAR2(240) ,ATTRIBUTE9 VARCHAR2(240) ,ATTRIBUTE10 VARCHAR2(240) ,ATTRIBUTE11 VARCHAR2(240) ,ATTRIBUTE12 VARCHAR2(240) ,ATTRIBUTE13 VARCHAR2(240) ,ATTRIBUTE14 VARCHAR2(240) ,ATTRIBUTE15 VARCHAR2(240) ,CONSTRAINT PK_chinese_Spell PRIMARY KEY(chinese_Spell_ID) ) TABLESPACE XYG_DATA ; COMMENT ON TABLE XYG.XYG_chinese_Spell IS 'XYG_汉字对应拼音'; CREATE SYNONYM APPS.XYG_chinese_Spell FOR XYG.XYG_chinese_Spell; CREATE SEQUENCE XYG.XYG_chinese_Spell_S NOMAXVALUE MINVALUE 1; --DROP SYNONYM APPS.XYG_chinese_Spell_S; CREATE SYNONYM APPS.XYG_chinese_Spell_S FOR XYG.XYG_chinese_Spell_S; CREATE UNIQUE INDEX XYG.XYG_chinese_Spell_U1 ON XYG.XYG_chinese_Spell(chinese_Word) TABLESPACE XYG_IDX; --DROP TABLE XYG_chinese_Spell_TEMP; ---创建临时表,要将Excel的数据导入到这个表格。 CREATE TABLE XYG_chinese_Spell_TEMP( chinese_Spell VARCHAR2(500), -- 汉语拼音 chinese_Word VARCHAR2(4000) -- 汉字堆 );
---接着要用Toad工具导入对应的拼音汉字对照表(汉字拼音对照表_IMPORT.xls)。
---Excel文档以及相关资料下载: http://download.csdn.net/detail/samt007/5165175
---PS:用Pl/SQL Developer工具导入好像会报错:ora-01480 trailing null missing from str bind value
SELECT * FROM XYG_chinese_Spell_TEMP;
---去掉分号
UPDATE XYG_chinese_Spell_TEMP
SET CHINESE_WORD = REPLACE(CHINESE_WORD,'''',NULL);
---去掉逗号
UPDATE XYG_chinese_Spell_TEMP
SET CHINESE_WORD = REPLACE(CHINESE_WORD,',',NULL);
---去掉空格
UPDATE XYG_chinese_Spell_TEMP
SET CHINESE_WORD = LTRIM(TRIM(CHINESE_WORD));
UPDATE XYG_chinese_Spell_TEMP
SET CHINESE_SPELL = LTRIM(TRIM(CHINESE_SPELL));
COMMIT;
---向正式表格塞入:
INSERT INTO XYG_chinese_Spell(chinese_Spell_ID,CHINESE_SPELL,CHINESE_WORD)
SELECT XYG_chinese_Spell_S.NEXTVAL
,CHINESE_SPELL
,CHINESE_WORD
FROM XYG_chinese_Spell_TEMP;
COMMIT;
SELECT * FROM XYG_chinese_Spell
WHERE CHINESE_WORD LIKE '%你%'
---检查数据没问题,则可以dorp掉临时表
DROP TABLE XYG_chinese_Spell_TEMP;
----接着建立函数:
---get_chinese_Spell ;函数内容下面有。
---注意函数的输入参数。可以任意输出想要的格式~
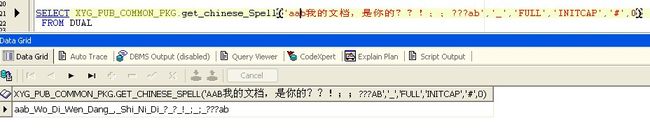
SELECT XYG_PUB_COMMON_PKG.get_chinese_Spell('我的文档','_','FULL','INITCAP','#',0) FROM DUAL
---样例:
---后期数据的整理:
---因为存在一个字多个拼音,这个拼音如何抓取的问题。目前抓取的逻辑是抓最大ID的对应的拼音。
----汉字博大精深啊。
---将一些重复的字的拿掉。例如,信=xin。别的拿掉。如果你觉得有需要。
UPDATE XYG_chinese_Spell SET CHINESE_WORD = REPLACE(CHINESE_WORD,'信',NULL) WHERE chinese_Spell_ID = 450; UPDATE XYG_chinese_Spell SET CHINESE_WORD = REPLACE(CHINESE_WORD,'查',NULL) WHERE chinese_Spell_ID IN (69,133); UPDATE XYG_chinese_Spell SET CHINESE_WORD = REPLACE(CHINESE_WORD,'掉',NULL) WHERE chinese_Spell_ID IN (367); UPDATE XYG_chinese_Spell SET CHINESE_WORD = REPLACE(CHINESE_WORD,'数',NULL) WHERE chinese_Spell_ID IN (461); UPDATE XYG_chinese_Spell SET CHINESE_WORD = REPLACE(CHINESE_WORD,'题',NULL) WHERE chinese_Spell_ID IN (170); UPDATE XYG_chinese_Spell SET CHINESE_WORD = REPLACE(CHINESE_WORD,'精',NULL) WHERE CHINESE_CODE_ID IN (407); UPDATE XYG_chinese_Spell SET CHINESE_WORD = REPLACE(CHINESE_WORD,'以',NULL) WHERE chinese_Spell_ID IN (463);
---------------------我是美丽的分隔符-------------------------
函数部分:
--SELECT XYG_PUB_COMMON_PKG.get_chinese_Spell('我的文档(东镀囧)001','_','FULL','INITCAP','#',0) FROM DUAL
function get_chinese_Spell(p_cnStr In varchar2
,P_SEPARATOR In varchar2 Default Null--输出汉字的分隔符
,p_output_type In varchar2 Default Null--输出格式,是首字大写FIRST还是全部FULL
,P_CASE_TYPE IN VARCHAR2 DEFAULT 'LOWER'---输出汉字的拼音的格式,小写,大写还是首字母大写INITCAP。
,P_UNKNOW_SPELL VARCHAR2 DEFAULT '#'---识别不了的用哪个字符显示
,P_RAISE IN NUMBER DEFAULT XYG_PUB_CONST_PKG.C_TRUE) return varchar2
as
lv_spell varchar2(3000);
lv_temp Varchar2(100);
lv_char varchar2(100);
---
lv_exists_cn boolean;--是否存在汉字的
---获取单个的拼音
Function get_signle_spell(P_SIGNLE_CHINESE IN VARCHAR2) return VARCHAR2
is
l_return XYG_chinese_Spell.CHINESE_SPELL%TYPE;
begin
SELECT XCS1.CHINESE_SPELL
INTO l_return
FROM XYG_chinese_Spell XCS1
WHERE XCS1.CHINESE_Spell_ID =
(SELECT MAX(XCS2.CHINESE_Spell_ID)
FROM XYG_chinese_Spell XCS2
WHERE XCS2.CHINESE_WORD LIKE '%'||P_SIGNLE_CHINESE||'%');
RETURN l_return;
EXCEPTION
WHEN OTHERS THEN
RETURN P_UNKNOW_SPELL;
end;
begin
if p_cnStr is null then
return '';
end if;
lv_exists_cn := false;
for i In 1..length(p_cnStr) loop
lv_char:=substr(p_cnStr,i,1);
if lengthb(lv_char) = 1 then
if lv_exists_cn then
lv_spell:=lv_spell||P_SEPARATOR||lv_char;
lv_exists_cn := false;
else
lv_spell:=lv_spell||lv_char;
end if;
else--汉字:
----如果是常用的符号,也要转换。只是单对单的转换。
if lv_char = ',' then--逗号
lv_temp := ',';
elsif lv_char = '。' then--句号
lv_temp := '.';
elsif lv_char = '?' then--问号
lv_temp := '?';
elsif lv_char = '!' then--感叹号
lv_temp := '!';
elsif lv_char = '‘' then--单引号
lv_temp := '''';
elsif lv_char = '“' then--双引号
lv_temp := '"';
elsif lv_char = ';' then--分号
lv_temp := ';';
elsif lv_char = ':' then--冒号
lv_temp := ':';
else
lv_exists_cn := true;
lv_temp := get_signle_spell(lv_char);
IF P_CASE_TYPE = 'LOWER' THEN
lv_temp := LOWER(lv_temp);
ELSIF P_CASE_TYPE = 'UPPER' THEN
lv_temp := UPPER(lv_temp);
ELSIF P_CASE_TYPE = 'INITCAP' THEN
lv_temp := INITCAP(lv_temp);
ELSE
NULL;
END IF;
end if;
if p_output_type = 'FIRST' then
lv_spell:=lv_spell||P_SEPARATOR||substr(lv_temp,1,1);
else
lv_spell:=lv_spell||P_SEPARATOR||lv_temp;
end if;
end if;
end loop;
---将左边的分隔符去掉
IF P_SEPARATOR IS NOT NULL THEN
lv_spell := LTRIM(lv_spell,P_SEPARATOR);
END IF;
return lv_spell;
end;
来自:http://www.itpub.net/thread-1774405-1-8.html