1亿qq在线背后的技术
摘要: 众所周知,海量互联网服务能力是世界公认的技术难题。经过十多年的发展,腾讯在海量互联网服务方面已有不少技术积累。以QQ IM后台服务为例,重现了QQ在线用户从百万级到亿级的整个过程中遇到的技术挑战,并分享了众多在海量互联网后台服务研发运营方面不为人知的秘密。

庄泗华:腾讯通平台部高级技术总监、腾讯T4级技术专家、腾讯软件开发通道分会会长。中科院计算技术研究所硕士,2004年毕业加入腾讯,是腾讯培养出的第一位T4专家级毕业生。一直致力于QQ IM后台海量服务系统的研发和运营工作,负责过QQ群聊系统、QQ接入与基础通信服务系统等后台系统的研发和运营,见证了QQ在线从800万到1.4亿的整个过程。
QQ现在面临7亿活跃账户,每日1.4亿用户同时在线。QQ过万台IM服务器和百亿级的关系链对数每天接受千亿级的服务请求考验。在这些苛刻的数字面前腾讯要保证99.99%的可用性。当然团队在QQ在线从10万到1.4亿的整个过程也经历了很多破折,同时从十万级、百万级、千万级最终到亿级在线腾讯也吸取了很多教训。这也说明了腾讯对海量服务的理解是长期积累的结果。
第一代架构:难以支持百万级在线
腾讯QQ的第一代架构,当达到一百万在线时,老架构会有各方面的瓶颈出现。以接入服务器的内存为例,单个在线用户的存储量约为2KB,索引和在线状态50字节。好友表400个好友 * 5字节/好友等于2000字节。大致来说,2G内存只能支持一百万在线用户。与此同时,还有CPU/网卡包量和流量/交换机流量等瓶颈,其他服务器也面临类似情况,单台服务器支撑不下所有在线用户/注册用户,第一代架构已无以为继。
庄泗华认为十万级到百万级在线的关键技术是高性能和实现7乘24小时连续服务。实现高性能的关键因素包括绝不使用企业级解决方案、逻辑层多进程、万有一失的无锁设计、用户态IPC、MySQL分库分表以及好友表自写文件存储。而通过大系统小做、平滑重构、核心数据放入共享内存、接入层与逻辑层分离以及命令分发动态配置化可保证QQ后台实现7乘24小时连续服务。

第二代架构:难以支持千万级在线
同样第二代架构也存在一些问题。包括同步流量太大、状态同步服务器遇到单机瓶颈、所有在线用户的在线状态信息量太大、单台接入服务器存不下等问题。并且当在线数进一步增加,单台状态同步服务器不能满足需求,单台状态同步服务器支撑不了所有在线用户,单台接入服务器也支撑不了所有在线用户的在线状态信息。
通过深入分析,腾讯发现后台机器越来越多,单机死机/故障就会经常出现。同时每周新代码的发布也导致BUG不断出现,严重影响服务。监控机制的相对原始导致报警设置不全。最后当运维操作通过vim或者mysql进行时也非常容易失误。
庄泗华表示想要解决这些问题就需要对现有架构进行改造。这包括对外提供高可用性的服务、对内提供高可运维性的系统。同时灰度发布、运营监控、容灾以及运维自动化/半自动化也是解决千万级在线所面临问题的关键技术。
第三代架构:亿级在线时代的到来
随着亿时代在线到来,腾讯也面临了新的问题。通过对原有系统持续完善已经很难支撑亿级在线。
庄泗华表示亿时代在线的四个关键特性:高性能、高可用性、高可运维性和高灵活性
由于互联网行业要求每个月出一个新版本。所以必须提供高灵活性的业务支持。作为硬件层面来说,高可运维性则需要物理架构详细到机架、并具备故障分析智能化、运维操作组件化和负载自动转移等特性的支持。而要保证系统的高性能,自写存储层是至关重要的因素。庄泗华还表示:在线量每提升一个量级,技术难度也会提升一个量级
最后,庄泗华认为互联网行业有自己的技术规律,需要做自己的技术积累。而腾讯IM服务的未来战略就是全球化分布、高效率的研发以及监控告警的智能化。
本文转自: 腾讯1亿用户在线背后的技术挑战
----------------------------------------------------------
QQ基础数据库架构演变史
QQ基础数据库,作为腾讯最核心最基础的后台服务之一,是存储QQ用户帐户信息和关系链信息的海量集群,它承载了百万级每秒的访问量、十亿级的账户数、百亿级关系链。如此大规模的集群,它是如何从300万的数量级一步一步演变而来?在它数据量不断增长的过程中,它经历了哪些困难,又是如何解决的?如今,它的架构是怎么样的?
QQ Basic DB是什么?是QQ用户帐号(用户密码与资料)与关系链等基础数据的分布式海量存储集群。是QQ IM业务的后台DB;是腾讯几乎所有其他业务的基础,提供用户帐号和关系链服务。它与QQ IM 集群并列为腾讯最核心、历史最久的两大集群。
早期的难题
在2000年,QQ Basic DB将每300万连续QQ号码存储在一个机器上。碰到的最大问题是在登录比较频繁的情况下,磁盘非常忙,登录超时。找到了影响磁盘随机寻址能力的因素,我们提出了解决方案在进程空间内,动态分配一些内存,将用户热点数据cache到内存中。使得处理能力显著提升,单机能够处理1-2千次每秒的请求。
时间进入2002年,随着机器台数增多,死机是家常便饭。QQ Basic DB通过IDC级容灾、数据复制等方法将(500+)*2台机器;数百亿的关系链,数十亿的账户数;每秒百万次读,数万次写的数据库的全年可用性做到了99.99%。
如何做到高可用?
1、IDC级的容灾
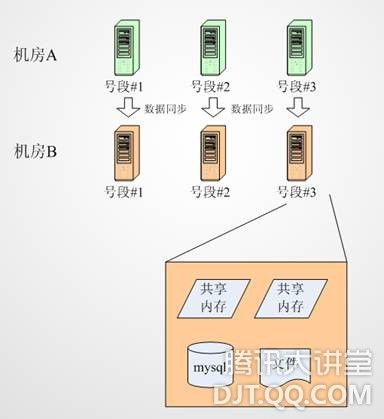
2、灰度发布

3、强监控,及时处理
Bison提到,随着时代的变迁,需求不断增加,QQ Basic DB走入了V2.0。当前的需求与DB能力的脱节;一地的机房已饱和,异地部署逼在眉睫!新增一个帐号相关字段,需要2个月,把内存全部重新load一遍,风险极高。老的架构不能很好的支持异地部署,因此QQ Basic DB V2.0应运而生。
在演讲中Bison特别强调,要做到产品特性灵活扩展,最关键的是用户数据结构的灵活性!QQ Basic DB在V2.0版本中,对数据结构扩展性上进行了大量优化。现场Bison例举了一个很简单的例子:采用XML开式存储用户数据的优劣性。存储海量数据的QQ Basic DB,不适宜采用类似XML方式进行存储,原因是当存储量超过亿级时,冗余信息将极大占用通讯带宽!QQ团队通过tag整数化、必选的定长字段共用一个tag等手段(tag-length-value,TLV),最终让DB有效载荷相对XML模式提升了 10倍,pack/unpack效率提升了100倍!

Bison列举的一个简单XML存储例子
在下一个部分,Bison主要提到了大家比较关心的QQ Basic DB安全性问题,其中一个非常重要的点就是异地部署。他特别强调,数据安全最关键的是有一套简单健壮、适应窄带化的数据复制机制。QQ Basic DBV2.0通过类似mysql复制机制做到了简单健壮,带宽占用窄带化,在专线故障情况下,流量可以在内外网灵活切换。目前在全国各地都有部署。

接下来,廖念波先生给大家介绍了优化了分片(sharding)方式、超长关系链解决方法、过载保护等方面的内容,给大家全面展示了腾讯的一些技术积累和总结。

本文转自 : 窥探QQ基础数据库架构演变史
参考推荐:
1.4亿在线背后-QQ IM后台架构的演化与启示
来源:http://blog.csdn.net/sunboy_2050/article/details/8573961