IR的设计
课程概要
- 布尔查询
- 词项分割与去停用词
- 倒排索引的构建与词典
- 输入纠错与编辑距离
- 索引压缩
- 向量空间模型与tf-idf权重计算
- 检索系统的评价
- 检索模型的介绍
- Web采集与链接分析
课程设计
任务内容
Part 1:
基本要求:构建词典和倒排索引
* 实现 Single-pass In-memory Indexing
* 实现倒排索引的 Gamma 编码压缩 / 解压
* 实现词典的单一字符串形式压缩 / 解压,任意数据结构(如哈希表、 B 树等)
* 实现关键字的查找,命令行中 Print 给定关键字的倒排记录表
* 给出以下语料统计量:词项数量,文档数量,词条数量,文档平均长度(词条数量)
* 对停用词去除、词干还原等无要求,但应实现最基本的词条化功能 例如:将所有非字母和非数字字符转换为空格,不考虑纯数字词项
Test Data
解压命令: tar zxvf shakespear-merchant.trec.tgz
Part 2:
采用类似 TREC 竞赛的形式
* 以小组形式在给定数据上进行实验
* 鼓励创新思维
– 评分:综合考虑实验结果和使用的新方法、提出的新思路
任务设计思路
第一部分是对我们课上学习内容的实现,通过实现任务一,对于加深对课程学习的立即是很有帮助的
主要涉及:
1. 词项归一化(选择哪种归一化方法?)与去停用词(哪些是停用词?)和词条化
2. 字符串压缩与解码
3. 倒排索引的构建
4. 语料的读取与分词
5. 统计分析词项数量与文档数量、文档长度(词条数目),词条数量
第二部分是research能力与开发能力并重的,可以使用开源软件提升检索能力,也可以自己实现检索器
实现
It’s preferred to use Python and with python package unittest for unit test to imply the part one while C++ implement is optional.
关于TREC数据集合构建索引查询分析的实验
调研
- TREC Terabyte Track
开源搜索引擎
参考博文
开源搜索引擎性能比较研究
简要介绍
ht://Dig, 提供一组工具可以索引和搜索一个站点。提供有一个命令行工具和CGI界面来执行搜索。
尽管已经有了更新的版本了, 但是根据项目的网站, 3.1.6版是最快的版本了。IXE Toolkit, 是模块化C++类集合, 有一组工具完成索引和查询。Tiscali(来自意大利)提供有商业版本, 同时提供了一个非商业版本仅用于科学研究。
Indri,是基于Lemur的搜索引擎。Lemur是用来研究语言模型和信息检索的工具。这个项目是马萨诸塞大学和CMU的合作项目的产物。
Lucene, 是Apache 软件基金会的一个文本搜索引擎库。由于它是一个库,所以很多项目基于这个库,例如Nutch项目。
在目前,它捆绑自带的最简单的应用是索引文档集合。MG4J(管理前兆数据Java语言)是针对大文本集合的一个全文索引工具。由米兰大学开发。他们提供了通用的字符串和位级别的I/O的优化的类库作为副产物。
Omega, 基于Xapian的应用。Xapian是开源的统计信息检索库,由C++开 发,但是被移植到了Python Perl php Java Tcl C#等多种语言。
IBM Omnifind Yahoo! Edition, 非常适合内网 搜索的搜索软件。 他结合了基于Lucene索引的内网搜索,和利用Yahoo 实现的外网搜索。
SWISH-E(简单网页索引系统—增强版), 是开源的索引和检索引擎。是Kevin Hughes 开发的SWISH的增强版。
SWISH++是基于SWISH-E的索引和检索工具。尽管经过C++全部重写, 但是 没有实现SWISH-E的全部功能。
Terrier(太字节检索), 由苏格兰的格拉斯哥大学开发的,模块化的平台,能够快速的构架互联网,内网,和 桌面的搜索引擎。它附带了索引,查询和评估标准TREC集合的功能。
XMLSearch, C++开发的索引和检索的一组类。利用文本操作(相等,前缀,后缀,分段)来扩展了查询能力。 Barcino(来自智利)提供了一个商 业版, 同时也有个供学术研究的非商业版。
Zettair,(先前称为Lucy),由皇家墨尔本理工大学的搜索引擎小组开发的文本检索引擎。
主要特征是能够处理超大量的文本。支持Html和TREC数据zettair
实验结果:
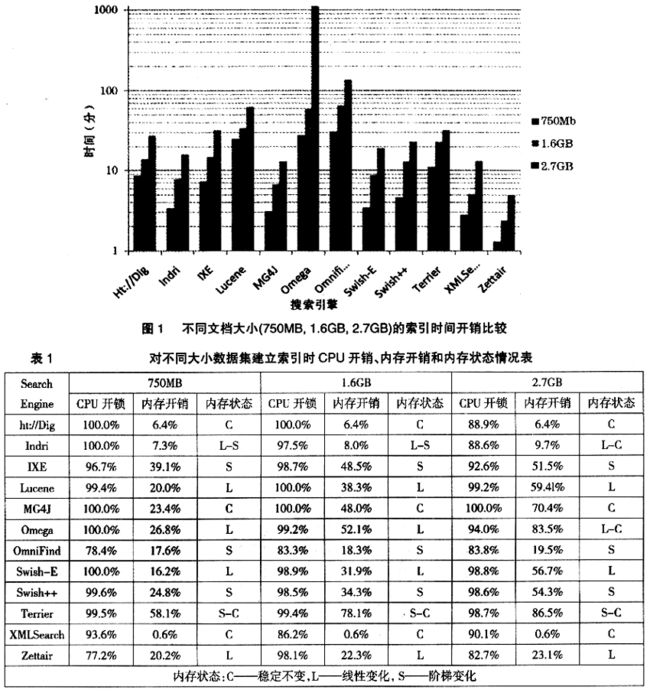
1. ht://Dig, Lucene和XMLSearch会有固定大小的内存开销,并且前两者的内存开销与数据集的大小没有关系(30MB~120MB);IXE,MG4J,Swish-E, Swish++ 和Terrier内存开销大,呈现线性增长;针对大的数据集合要1G以上的内存开销。
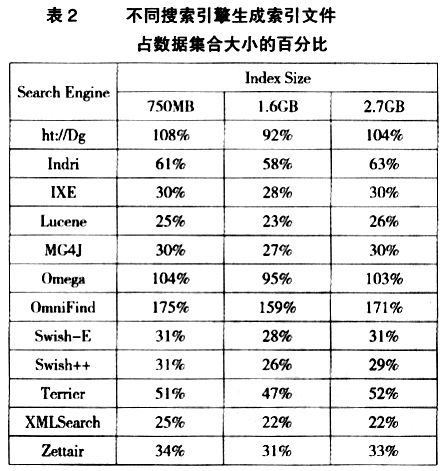
- Lucene, MG4J, Swish-E, Swish++, XMLSearch 和Zettair的索引大小为数据集大小的25%~35%。Terrier建立索引文件大小为原来的50%。其他还增大了。
3. 在数据集合非常的时候,只有Indri, IXE, MTerrier和Zettair的索引性能不会大幅度下降,而Swish-E, Swish++ 在给定系统参数下,根本不能够对大数据集合进行索引。
总结:
1. Lucene, MG4J, Swish-E, Swish++, XMLSearch 和Zettair的索引大小为数据集大小的25%~35%。Terrier建立索引文件大小为原来的50%。其他还增大了。
ht://Dig, Lucene和XMLSearch会有固定大小的内存开销,并且前两者的内存开销与数据集的大小没有关系(30MB~120MB);IXE,MG4J,Swish-E, Swish++ 和Terrier内存开销大,呈现线性增长;针对大的数据集合要1G以上的内存开销。
在数据集合非常的时候,只有Indri, IXE, MTerrier和Zettair的索引性能不会大幅度下降,而Swish-E, Swish++ 在给定系统参数下,根本不能够对大数据集合进行索引。
WT10g 数据说明
数据概述
============
Contents of WT10g
WT10g consists of data distributed on 5 CDs, numbered CD1 to CD5. The
data is split into individual directories, WTX001, WTX002 and so
on. Within each directory, documents are bundled together into files
of roughly 2MB in size, numbered B01, B02 .. B50. The bundle files are
all compressed using gzip, so exist as B01.gz etc.
CD1 contains data for the following: WTX001 .. WTX024, each directory contains 50 bundle files B01.gz .. B50.gz
CD2 contains data for the following: WTX024 .. WTX048, each directory contains 50 bundle files B01.gz .. B50.gz
CD3 contains data for the following: WTX049 .. WTX072, each directory contains 50 bundle files B01.gz .. B50.gz
CD4 contains data for the following: WTX073 .. WTX096, each directory contains 50 bundle files B01.gz .. B50.gz
CD5 contains data for the following: WTX097 .. WTX104, each directory contains 50 bundle files B01.gz .. B50.gz
except WTX104, containing 7 bundle files B01.gz .. B07.gz
CD5 also contains: info, which has additional information generated for WT10g data, described below.
Note well: The contents of this directory ( WT10g::CD5::info ) do not
constitute part of WT10g’s data.
Data Set info directory information
None of the files in this info directory should be indexed.
文件列表
It contains the following files:
README - this file
docid_to_url - mappings: WT10g docid -> URL (*)
homepages - mappings: server name -> WT10g docid
in_links - mappings: WT10g docid -> set of WT10g docids, whose pages
contain (incoming) links to this page (*)
out_links - mappings: WT10g docid -> set of WT10g docids, whose pages
are named by (outgoing) links from this page (*)
servers - server names
url_to_docid - mappings: URL -> WT10g docid
wt10g_to_vlc2 - mappings: WT10g docid -> VLC2 docid (*)
URLs are of the form: http://server_name/path
Server names are of the form: www.foo.com:port_number
Port numbers are of the form: 1234 (but are usually just 80)
WT10g docids are of the form: WTX123-B45-6789, where the final doc
number in the bundle is numbered from 1
VLC2 docids are of the form: IA012-003456-B078-901, where the final
doc number in the bundle is numbered from 1
(*) Note well:
All info files are sorted using the Linux sort routine, using the first entry of each line as the sort key. Since the last component of a WT10g docid is numbered sequentially from 1 upwards, and the sort order is alphabetical, these files have a slightly confusing ordering, which is not identical to the numeric ordering of the documents within each bundle.
For example, the first entries of docid_to_url are:
WTX001-B01-1 http://www.ram.org:80/ramblings/movies/jimmy_hollywood.html
WTX001-B01-10 http://sd48.mountain-inter.net:80/hss/teachers/Prothero.html
WTX001-B01-100 http://www.ccs.org:80/hc/9607/win95.html
WTX001-B01-101 http://www.cdc.net:80/~dejavu/scuba-spec.html
WTX001-B01-102 http://www.cdm.com:80/humanres/jobs/enevga.html
after which there are a number of other entires followed by:
WTX001-B01-198 http://www.cdc.net:80/~dupre/pharmacy/CD581.html
WTX001-B01-199 http://www.cdnemb-washdc.org:80/baltimor.html
WTX001-B01-2 http://www.radio.cbc.ca:80/radio/programs/current/quirks/archives/feb1796.htm
WTX001-B01-20 http://moe.med.yale.edu:80/mirror/vat/la.html
WTX001-B01-200 http://www.cdc.net:80/~dupre/pharmacy/pbsound.html
WTX001-B01-201 http://www.cdnemb-washdc.org:80/sanfran.html
and so on.
Document format
The following is an example document contained within the collection.
All documents are delimited by tags. The unique WT10g
document identifier is enclosed within tags, and the
old VLC2 document identifier is contained on the next line between
tags. Next comes a section
which provides various bits of information about the document reported
by the http server which served the document to the original Internet
Archive crawler. Lastly the actual HTML source is given.
<DOC>
<DOCNO>WTX104-B01-1</DOCNO>
<DOCOLDNO>IA097-001048-B043-338</DOCOLDNO>
<DOCHDR>
http://msfcinfo.msfc.nasa.gov:80/nmo/nmonasa.html 192.112.225.4 19970215104446 text/html 1014
HTTP/1.0 200 Document follows
Date: Sat, 15 Feb 1997 10:37:04 GMT
Server: NCSA/1.5
Content-type: text/html
</DOCHDR>
<HTML>
<HEAD>
<TITLE>Instructions to NASA Sponsors </TITLE> </HEAD>
<BODY><H1><STRONG>Instructions to NASA Sponsors </STRONG></H1><P><H3>JPL is under the institutional management of
the Office of Space Science at NASA Headquarters. NASA Centers or activities contemplating the placement of resea
rch and development work at the Jet Propulsion Laboratory may contact the NASA Contracting Officer(<A href="mailto : [email protected]"> [email protected])</a> at the NMO for more details or the Research and A
dministration Division of the Office of Space Science, Code SP at NASA Headquarters.
</H3><HR>[<A HREF="nmohome.html">NMO Procurement Home Page</A>]<P>Please send comments and questions to <A href="m ailto:[email protected]"> [email protected]</a><BR>Curator and Owner: Katherine M. Wolf<BR>Last update t
o this page: September 15, 1995 @ 3:23 p.m. PDT
</BODY>
</HTML>
</DOC>Disclaimer
While all reasonable attempts have been made to accurately identify
URLs and link references occurring in documents in this collection, we
make no guarantee as to the correctness or completeness of the
information contained in the files in this directory. In particular,
URL canonicalisation is a fiendishly problematic task, especially with
relative URLs and HTML tags such as base hrefs. Similarly, servers are
identified sometimes by IP addresses and sometimes by hostname. It may
be the case that some hostnames are aliases for others, and/or for IP
addresses represented within the collection. In all cases, do not rely
on the info files to be completely accurate.
If you encounter any major discrepancies within the info files, we
would be very grateful to hear about them.
Web and Associated Research project
ACSys Cooperative Research Centre
http://pastime.anu.edu.au/WAR2000/03/15
The Zettair Search Engine – Performing TREC experiments
First, obtain the latest Zettair distribution and decompress it.
Obtain the latest zlib source distribution (do NOT download the precompiled DLL)
from http://www.zlib.net/ and decompress it into a seperate directory.
Follow the zlib directions to create a statically-linked zlib.lib using
Visual C++.
Locate zlib.lib within your zlib directory tree, and copy it to the
root zettair-X.X/ directory.
In addition, copy zlib.h and zconf.h into zettair-X.X/src/include.
Load zettair-X.X/win32/visualc6/zettair.dsw into Visual C++.
Using the Build/Set Active Configuration menu option, select the
executable that you wish to build.
Build the executable by selecting Build/Rebuild All. (Repeat for any
further executables that you wish to build). You may then copy the
created executables whereever you like, and use them.
* install the zlib by the apt-get
$sudo apt-get install zlib1g-dev- compiler from source code
$wget http://www.zlib.net/zlib-1.2.3.tar.gz
$tar -xvzf zlib-1.2.3.tar.gz
$cd zlib-1.2.3.tar.gz
$./configure
$make
$sudo make installFollow these steps:
- Download Zettair as a zip file.
- Change into the directory where you’ve saved Zettair and unzip it:
$ cd ~
$ unzip zettair-0.9.3.zip- Make and install the Zettair software:
$ cd zettair-0.9.3
$ ./configure --prefix=$HOME/local/zettair-0.9.3
$ make
$ make install- Build an index on the TREC collection (example shown uses the WT10G collection):
$ cd ~
$ ls wt10g/
wt10g-1.html wt10g-3.html wt10g-5.html
wt10g-2.html wt10g-4.html wt10g-6.html
$ ~/local/zettair-0.9.3/bin/zet -i -t TREC -f wt10g wt10g/wt10g-*.htmlversion 0.9.3
sources (type trec): wt10g/wt10g-1.html wt10g/wt10g-2.html
wt10g/wt10g-3.html wt10g/wt10g-4.html wt10g/wt10g-5.html
wt10g/wt10g-6.html
parsing wt10g/wt10g-1.html…
parsing wt10g/wt10g-1.html…
parsing wt10g/wt10g-2.html…
parsing wt10g/wt10g-3.html…
parsing wt10g/wt10g-4.html…
parsing wt10g/wt10g-5.html…
parsing wt10g/wt10g-6.html…
merging…
summary: 1697027 documents, 9147236 distinct words
- Run the zet_trec executable with the TREC topic file to query the index for each of the topics:
$ ls topics.*topics.451-500
$ ~/local/zettair-0.9.3/bin/zet_trec -f topics.451-500 -r zettair -n 1000 wt10g > topics.451-500.out$ head topics.451-500.out
451 0.000000 WTX064-B48-194 0 25.974307 zettair
451 0.000000 WTX008-B37-10 0 25.728757 zettair
451 0.000000 WTX064-B48-193 0 25.691912 zettair
451 0.000000 WTX095-B05-124 0 25.075859 zettair
451 0.000000 WTX031-B22-288 0 24.558171 zettair
451 0.000000 WTX064-B48-198 0 22.862540 zettair
451 0.000000 WTX092-B49-42 0 22.187891 zettair
451 0.000000 WTX064-B48-188 0 22.069917 zettair
451 0.000000 WTX003-B26-249 0 21.889636 zettair
451 0.000000 WTX011-B16-71 0 21.377611 zettair
- Use the trec_eval program to evaluate the run:
$ trec_eval qrels.trec9.main_web topics.451-500.outQueryid (Num): 48
Total number of documents over all queries
Retrieved: | 45107
Relevant: | 2590
Rel_ret: | 1280
Interpolated Recall - Precision Averages:
at 0.00 0.6097
at 0.10 0.3957
at 0.20 0.3101
at 0.30 0.2587
at 0.40 0.2244
at 0.50 0.1798
at 0.60 0.1224
at 0.70 0.0868
at 0.80 0.0559
at 0.90 0.0419
at 1.00 0.0355
Average precision (non-interpolated) for all rel docs(averaged over queries)
0.1901
Precision
At 5 docs: 0.3333
At 10 docs: 0.2812
At 15 docs: 0.2417
At 20 docs: 0.2146
At 30 docs: 0.1826
At 100 docs: 0.1094
At 200 docs: 0.0763
At 500 docs: 0.0428
At 1000 docs: 0.0267
R-Precision (precision after R (= num_rel for a query) docs retrieved):
Exact: 0.2177