算法学习#08--深入详解并查集union-find算法
深入详解并查集union-find算法
动态连通性
1. 问题描述
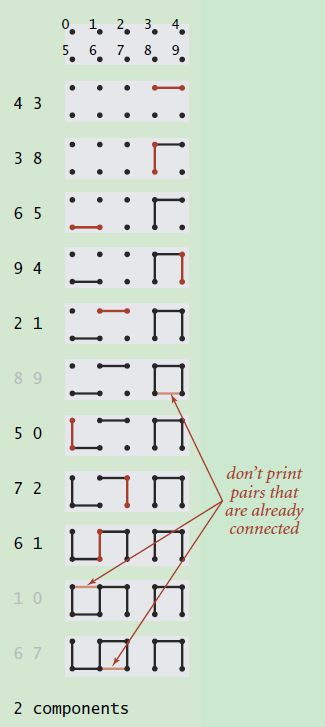
输入一系列整数对,其中每个整数都表示一个某种类型的对象,一对整数pq可以理解为“p和q是相连的”。
相连是一种对等关系,它需要具有以下性质:
自反性:p和p是相连的。
对称性:如果p和q是相连的,那么q和p也是相连的。
传递性:如果p和q是相连的且q和r也是相连的,那么p和r也是相连的。
假设我们输入了一组整数对,即下图中的(4, 3) (3, 8)等等,每对整数代表这两个points/sites是连通的。那么随着数据的不断输入,整个图的连通性也会发生变化,从上图中可以很清晰的发现这一点。同时,对于已经处于连通状态的points/sites,直接忽略,比如上图中的(8, 9)。
2. 应用场景
网络:整数表示的可能是一个大型计算机网络中的计算机,而整数对表示网络中的无数个连接。这个程序能够判断我们是否需要在p和q之间架一条新的连接才能进行通信。
变量名等同性(类似于指针的概念):
在程序中,可以声明多个引用来指向同一对象,这个时候就可以通过为程序中声明的引用和实际对象建立动态连通图来判断哪些引用实际上是指向同一对象。数学集合:在更高的抽象层次上,可以将输入的所有整数看做属于不同的数学集合。在处理一个整数对pq时,我们是在判断它们是否属于同一个集合。如果不是,我们会归并,最终所有整数属于同一集合。
3. 数学建模
在对问题进行建模的时候,我们应该尽量想清楚需要解决的问题是什么。因为模型中选择的数据结构和算法显然会根据问题的不同而不同,就动态连通性这个场景而言,我们需要解决的问题可能是:
给出两个节点,判断它们是否连通,如果连通,不需要给出具体的路径
给出两个节点,判断它们是否连通,如果连通,需要给出具体的路径
就上面两种问题而言,虽然只有是否能够给出具体路径的区别,但是这个区别导致了选择算法的不同,本文主要介绍的是第一种情况,即不需要给出具体路径的Union-Find算法,而第二种情况可以使用基于DFS的算法。
quick-find算法
1. API
注意:其中使用整数来表示节点,如果需要使用其他的数据类型表示节点,比如使用字符串,那么可以用哈希表来进行映射,即将String映射成这里需要的Integer类型。
2. 原理
举个例子,比如输入的整数对是(5, 9),那么首先通过find方法发现它们的组号并不相同,然后在union的时候通过一次遍历,将组号1都改成8。当然,由8改成1也是可以的,保证操作时都使用一种规则就行。
3. 代码
import java.util.Scanner;
public class UF {
private int[] id; // 分量id(以触点作为索引)
private int count; // 分量数量
public UF(int N)
{
// 初始化分量id数组.
count = N;
id = new int[N];
for (int i = 0; i < N; i++)
id[i] = i;
}
public int count() {
return count;
}
public boolean connected(int p, int q) {
return find(p) == find(q);
}
public int find(int p) {
return id[p];
}
public void union(int p, int q) {
// 获得p和q的组号
int pID = find(p);
int qID = find(q);
// 如果两个组号相等,直接返回
if (pID == qID) return;
// 遍历一次,改变组号使他们属于一个组
for (int i = 0; i < id.length; i++)
if (id[i] == pID) id[i] = qID;
count--;
}
public static void main(String[] args) {
String data = "4 3 3 8 6 5 9 4 2 1 5 0 7 2 6 1";
Scanner sc = new Scanner(data);
UF uf = new UF(10);
while (sc.hasNext()) {
int p = sc.nextInt();
int q = sc.nextInt();
if(uf.connected(p, q) ) {
continue;
}
uf.union(p, q);
System.out.println(p+ " " + q);
}
sc.close();
System.out.println(uf.count() + " 分量");
}
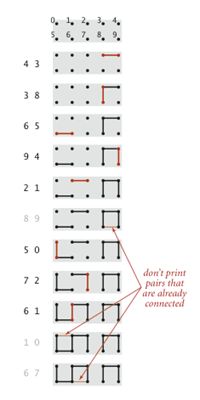
}输出:
4 3
3 8
6 5
9 4
2 1
5 0
7 2
6 1
2 分量轨迹如下图:
4. 算法分析
- union(p,q)会访问数组次数N+3~2N+1
分析:
(1)两次find()操作,访问2次数组
(2)扫描整个数组id[],判断p和q是否在同一个连通f分量if(find(i)==pID),访问N次数组
(3)①只有p,其余触点均不和p在同一连通分量 id[p] =qID,访问1次数组
②除了q本身,其余均和p在同一连通分量 id[i] = qID(i≠q),访问 N-1次数组,故总的访问次数
①2+N+1 = N+3②2+N+N-1 = 2N+1- 在最好的情况下,union(p,q)访问数组N+3次,N个整数要进行N-1次合并union(p,q)操作,访问数组(N+3)(N-1)~N^2。
- quick-union算法是平方级别的。
quick-union算法
1. 原理
考虑一下,为什么以上的解法会造成“牵一发而动全身”?
因为每个节点所属的组号都是单独记录,各自为政的,没有将它们以更好的方式组织起来,当涉及到修改的时候,除了逐一通知、修改,别无他法。所以现在的问题就变成了,如何将节点以更好的方式组织起来,组织的方式有很多种,但是最直观的还是将组号相同的节点组织在一起,想想所学的数据结构,什么样子的数据结构能够将一些节点给组织起来?常见的就是链表,图,树,什么的了。但是哪种结构对于查找和修改的效率最高?毫无疑问是树,因此考虑如何将节点和组的关系以树的形式表现出来。
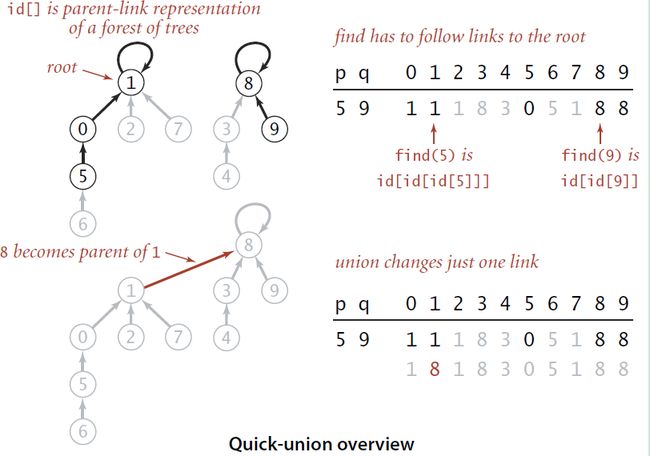
如果不改变底层数据结构,即不改变使用数组的表示方法的话。可以采用parent-link的方式将节点组织起来。
举例而言,id[p]的值就是p节点的父节点的序号,如果p是树根的话,id[p]的值就是p,因此最后经过若干次查找,一个节点总是能够找到它的根节点,即满足id[root] = root的节点也就是组的根节点了,然后就可以使用根节点的序号来表示组号。所以在处理一个整数对的时候,将首先找到整数对中每一个节点的组号(即它们所在树的根节点的序号),如果属于不同的组的话,就将其中一个根节点的父节点设置为另外一个根节点,相当于将一颗独立的树编程另一颗独立的树的子树。
2. 代码
在实现上,和之前的Quick-Find只有find和union两个方法有所不同:
public int find(int p) {
// 寻找p节点所在组的根节点,根节点具有性质id[root] = root
while (p != id[p]) p = id[p];
return p;
}
public void union(int p, int q) {
// 将p和q的根节点同一
int pRoot = find(p);
int qRoot = find(q);
if (pRoot == qRoot)
return;
id[pRoot] = qRoot; // 将一颗树(即一个组)变成另外一课树(即一个组)的子树
count--;
} 3. 算法分析
quick-union算法看似比quick-find算法块,因为它不需要为每对输入遍历整个数组。
① 最好的情况下find(p),仅访问一次数组,此时触点p为根触点
② 最坏的情况下find(p),访问数组2N-1次
while(p != id[p]) p = id[p];
最坏的情况是触点p所在的连通分量对应的树退化成线性表而且仅有一个连通分量,而p在线性表的表尾。while()循环的判断条件要访问N次数组,while()循环的执行体要访问N-1 次数组(当最后一次到达根节点时,不执行循环体)。共2N-1次。

由此可见,find(p)访问数组的次数,是由触点p对应的节点在树的高度所决定的。设p在树的中的高度为h,则访问数组的次数为2h+1次。
关于一些定义:

假设输入的是有序整数对0-1、0-2、0-3…0-N,N-1对之后的N个触点将全 部处于同一个连通分量内(详见main()),且由quick-union算法得到的树的高度为N-1,其中0→1,1→2…N-1→N。
对于整数对0-i,执行union(0,i),将访问2i+1次数组。
①其中0的根触点是i-1,高度是i-1,根据3,find(0)访问数组2i-1次
②其中i的根触点是i,高度是0,根据3,find(i)访问数组1次
③将i-1的根触点(原指向本身,现指向触点i)的数组内容变成i,访问数组1次
书上是2i+2次,我分析是0-i是连通的,这样0的根触点是i,i的根触点是i,find(0)访问2i+1次,find(i)访问1次共2i+2次。可根据main()方法,此时0和i应该不连通才对。
处理N对整数所需的所有find()操作访问是;Σ(1→N)(2i) = 2(1+2+…N) ~N^2
可以看出quick-union和quick-find都是平方级别的**。
加权quick-union算法
1. 原理
上面quick-union算法的效率之所以低(平方级别),最主要的原因是union(p,q)方法,随意将一棵树连接到另一棵树上(一棵树对应一个连通分量)。
如果是小树(高度低)连接到大树的根节点(高度高),则小树的高度加1,而整个树的高度不变。
如果是大树(高度高)连接到小树的根节点(高度低),则大树的高度加1,而整个树的高度由原来的小树高度变成大树高度加1。
根据quick-union算法分析,find(p)访问的数组的次数与节点p所在的高度有关。高度越高,访问数组的次数越多。
由此可见,为了减少访问数组的次数,提高算法效率,在执行union(p,q)操作时,确保是情况1,即小树连接到大树上。为此,需要一个数组sz[]来记录触点p所在的连通分量含有的触点(触点越多,对应的树的节点越多,即为大树)。
当然还有一种特殊情况,即p和q所在的连通分量对应的树高度相等,此时无论是p连接到q还是q连接到p,树的高度都会增加。在加权quick-union算法中,这是最坏的情况。
因此,由加权quick-union构成的树的高度将远小于未加权所构造的树的高度。
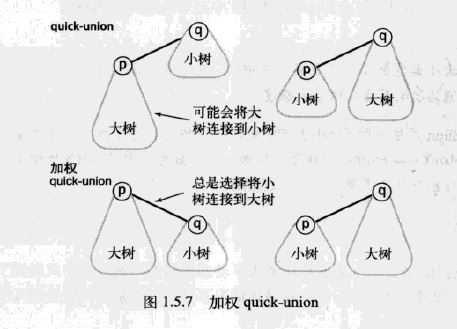
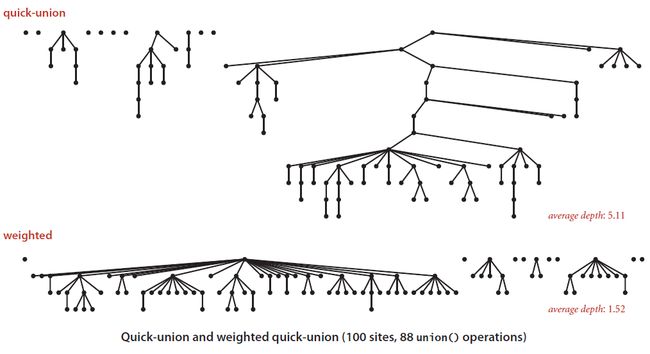
Quick-Union 和 加权 Quick-Union 的比较:
2. 代码
import java.util.Scanner;
public class WeightedQuickUnionUF {
private int[] id; // 分量id(以触点作为索引)
private int[] sz; // (由触点索引的)各个根节点所对应的分量的大小
private int count; // 分量数量
public WeightedQuickUnionUF(int N)
{
// 初始化分量id数组.
count = N;
id = new int[N];
sz = new int[N];
for (int i = 0; i < N; i++) {
id[i] = i;
sz[i] = 1;
}
}
public int count() {
return count;
}
public boolean connected(int p, int q) {
return find(p) == find(q);
}
public int find(int p) {
// 寻找p节点所在组的根节点,根节点具有性质id[root] = root
while (p != id[p]) p = id[p];
return p;
}
public void union(int p, int q) {
int i = find(p);
int j = find(q);
if (i == j) return;
// 将小树作为大树的子树
if (sz[i] < sz[j]) {
id[i] = j;
sz[j] += sz[i];
}
else {
id[j] = i;
sz[i] += sz[j];
}
count--;
}
public static void main(String[] args) {
String data = "4 3 3 8 6 5 9 4 2 1 5 0 7 2 6 1";
Scanner sc = new Scanner(data);
WeightedQuickUnionUF uf = new WeightedQuickUnionUF(10);
while (sc.hasNext()) {
int p = sc.nextInt();
int q = sc.nextInt();
if(uf.connected(p, q) ) {
continue;
}
uf.union(p, q);
System.out.println(p+ " " + q);
}
sc.close();
System.out.println(uf.count() + " 分量");
}
}输出一样。
3. 算法分析
①最坏的情况:
将要被归并的树的大小总是相等的(且总是2^n)。每个树均是含有2^n节点的满二叉树,因此高度正好是n。当归并两个含有2^n节点的树时,得到含有2^(n+1)个节点的书,由此树的高度增加到n+1。由此可知,加权quick-union算法是对数级别的。即对于N个触点所构成的树最高的高度为lgN。
即如下推论:

②最坏的情况是怎么得来的?
简单的分析可知,加权quick-union算法不可能会得到线性表(未加权的quick-union会产生退化成线性表的树)。因此,每层的节点越多,树的高度就越小。最坏的情况就是满二叉树。
③加权quick-union算法处理N个触点,M条连接时最多访问数组cMlgN次。
c为常数。每处理一条连接,调用一次union(p,q)方法。而union(p,q)是lgN级别的。lg[height(p)] + lg[height(q)] + 5 = clgN,5是union方法里if else语句访问数组的次数。M次即为cMlgN )。而quick-find算法以及某些情况下未加权的quick-union算法至少访问数组MN次。