cs231n学习笔记
1. 机器学习流程简介
1)一次性设置(One time setup)
- 激活函数(Activation functions)
- 数据预处理(Data Preprocessing)
- 权重初始化(Weight Initialization)
- 正则化(Regularization:避免过拟合的一种技术)
- 梯度检查(Gradient checking)
2)动态训练(Training dynamics)
- 跟踪学习过程 (Babysitting the learning process)
- 参数更新 (Parameter updates)
- 超级参数优化(Hyperparameter optimization)
3)评估(Evaluation)
- 模型组合(Model ensembles)
(训练多个独立的模型,测试时,取这些模型结果的平均值)
2. 激活函数(Activation Functions)
详细内容参见:激活函数
总结:
1)使用ReLU时,使Learning Rates尽量小
2)尝试使用Leaky ReLU/Maxout/ELU
3)可以使用tanh,但期望不要太高
4)不要使用sigmoid
3. 数据预算处理(Data Preprocessing)
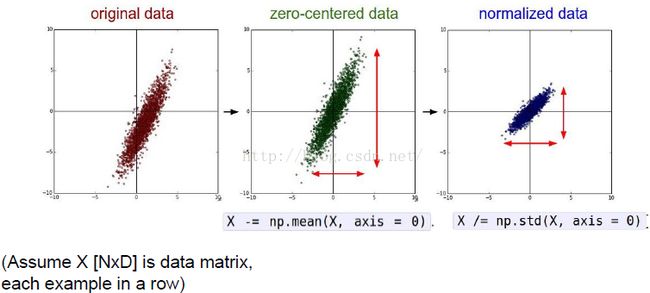
4. 权重初始化(Weight Initialization)
1)小的随机数
w= 0.01 * np.random.randn(fan_in,fan_out)
2)神经元将饱和,梯度为0
w = 1.0 * np.random.randn(fan_in,fan_out)
3)合理的初始化(Xavier init)
w = np.random.randn((fan_in,fan_out)/np.sqrt(fan_in)
权重初始化是一个重要的研究领域。
5. 批量归一化(BN: Batch Normalization)
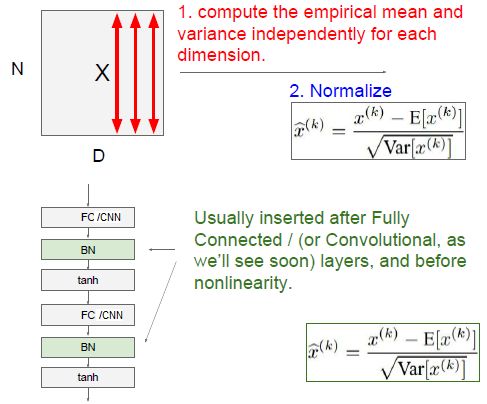
BN的作用:
1)改善流经网络的梯度
2)允许更大的学习率
3)减少对初始化的强烈依赖
4)作为正则化的一种形式,轻微减少了对dropout的需求
注:以上为学习过程,在测试时,均值和方差(mean/std)不基于小批量进行计算, 可取训练过程中的激活值的均值。
6. 跟踪训练过程
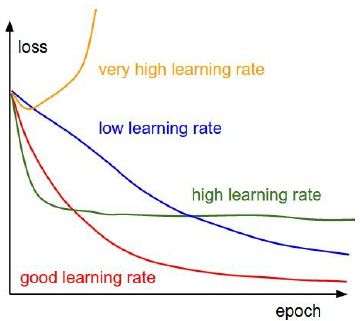
1)Learning Rate
- Learning Rate太小(如1e-6),cost下降很慢
- Learning Rate太大(如1e-6),cost增长爆炸 (cur cost > 3* original cost)
- 在[1e-3,1e-5]范围内比较合适
2)Mini-batch SGD
Loop:
1. Sample a batch of data
2. Forward prop it through the graph, get loss
3. Backprop to calculate the gradients
4. Update the parameters using gradient
7. 参数优化
参数优化直观显示图
参数优化的目的是:减少损失(loss), 直至损失收敛(convergence)
Caffe Solver,基于梯度下降的优化方法
7.1 Gradient Descent Variants
7.1.1 Batch gradient descent
for i in range(nb_epochs):
params_grad = evaluate_gradient(loss_function, data, params)
params = params - learning_rate * params_grad
7.1.2 SGD(Stochastic Gradient Descent: 随机梯度下降)
![]()
每次基于一个数据样本计算梯度。
for i in range(nb_epochs):
np.random.shuffle(data)
for example in data:
params_grad = evaluate_gradient(loss_function, example, params)
params = params - learning_rate * params_grad
7.1.3 Mini-batch Gradient Descent
每次基于n个数据样本计算梯度。
for i in range(nb_epochs):
np.random.shuffle(data)
for batch in get_batches(data, batch_size=50):
params_grad = evaluate_gradient(loss_function, batch, params)
params = params - learning_rate * params_grad 优点:
1)减少参数更新的变化, 从而得到更加稳定的收敛
2)使用先进的Deep Learning库,可以高效地计算mini-batch的梯度
注:n一般取[50,256]范围内的数,视具体应用而定。
7.1.4 梯度下降算法面临的挑战
1)选择合适的Learning Rate是困难的,太小导致收敛慢,太大阻碍收敛或且导致损失函数在最小值附近波动或发散;
2)预先定义的Learning Rate变动规则不能适应数据集的特性;
3)同样的Learning Rate运用到所有的参数更新(后面的AdaGrad, AdaDelta, RMSProp, Adam为解决此问题而生);
4)最小化高度非凸损失函数的羝问题是:避免陷入众多的局部最优值。
7.2 Momentum(动量)
关键优点: 利用物体运动时的惯性,加快到达全局最优点的速度,且减少振荡。
关键缺点:球盲目地沿着斜坡向山下滚。
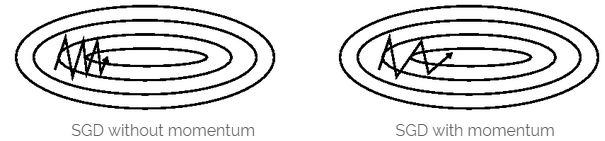
当Loss function的表面曲线的一维比其它维有更多的沟壑时,SGD要跨越此沟壑是困难的,如上图左边所示,SGD沿着沟壑的斜坡振荡,然后犹犹豫豫地向局部最优点前进。
Momentum即动量,它模拟的是物体运动时的惯性,即更新的时候在一定程度上保留之前更新的方向,同时利用当前batch的梯度微调最终的更新方向。这样一来,可以在一定程度上增加稳定性,从而学习地更快,并且还有一定摆脱局部最优的能力:
# Momentum update
V = gama * V + learning_rate * dw # integrate velocity
w -= V # integrate position
就是Momentum,经常取0.5,0.9,或0.99,有时随着时间而变化,从0.5到0.99;表示要在多大程度上保留原来的更新方向,这个值在0-1之间,在训练开始时,由于梯度可能会很大,所以初始值一般选为0.5;当梯度不那么大时,改为0.9。![]() 是学习率,即当前batch的梯度多大程度上影响最终更新方向,跟普通的SGD含义相同。与
是学习率,即当前batch的梯度多大程度上影响最终更新方向,跟普通的SGD含义相同。与![]() 之和不一定为1。
之和不一定为1。
Momentum的物理解释是:当我们把球推下山时,球不断地累积其动量,速度越来越快(直到其最大速度,如果有空气阻力,如<1),同样的事情发生在参数更新中:梯度保持相同方向的维度的动量不停地增加,梯度方向不停变化的维度的动量不停地减少,因此可以得到更快的收敛速度并减少振荡。
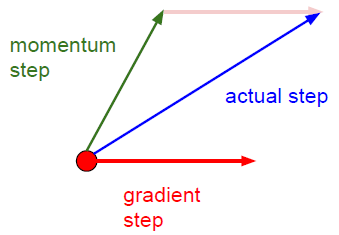
7.3 Nesterov Accelerated Gradient (NAG)
关键优点:一个聪明的球,知道它将到哪儿去,且知道在斜坡向上之前减速。
沿着当前方向,先走一步,然后再看向哪个方向走最快,这样对前方的情况就有了更多地了解,可以做出明智的决策。
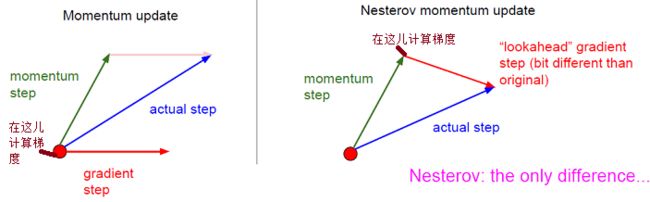
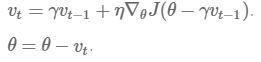
w_ahead = w - gama * v # evaluate dw_ahead (the gradient at w_ahead instead of at w) v = gama * v + learning_rate * dw_ahead w -= v
Momentum:
1)计算当前的梯度(上图中:比较小的蓝色向量)
2)沿着更新的累积的梯度方向进行一大跳(上图中:比较大的蓝色向量)
NAG:
1)沿着以前累积的梯度方向进行一大跳 (上图中:棕色向量)
2)在新的位置测量梯度,然后进行校正(上图中:绿色向量)
3)这个有预料的更新可以防止走的太快并导致增加的响应
关键区别:
1)计算梯度的位置不一样
7.4 每个参数有自适应的学习率(Per-parameter Adaptive Learning Rate)
本章描述的方法(AdaGrad、AdaDelta、RMSprop、Adam)专为解决Learning Rate自适应的问题。
前面讨论的基于梯度的优化方法(SGD、Momentum、NAG)的Learning Rate是全局的,且对所有参数是相同的。
参数的有些维度变化快,有些维度变化慢;有些维度是负的斜坡,有些维度是正的斜坡(如鞍点);采用相同的Learning Rate是不科学的,比如有的参数可能已经到了仅需要微调的阶段,但又有些参数由于对应样本少等原因,还需要较大幅度的调动。理想的方案是根据参数每个维度的变化率,采用对应的Learning Rate。
下面讨论如何自适应Learing Rate的方案:AdaGrad、AdaDelta、RMSProp、Adam。
7.4.1 AdaGrad(Adaptive Gradient )
AdaGrad方法给参数的每个维度给出适应的Learning Rate。给不经常更新的参数以较大的Learning Rate, 给经常更新的参数以较小的Learning Rate。Google使用此优化方法“识别Youtube视频中的猫” 。
在AdaGrad中,每个参数![]() 在每一次更新时都使用不同的Learming Rate。
在每一次更新时都使用不同的Learming Rate。
其公式如下:
θi
其示意代码如下:
# Assume the gradient dx and parameter vector x cache += dx**2 x -= learning_rate * dx / (np.sqrt(cache + 1e-8))
learning_rate 是初始学习率,由于之后会自动调整学习率,所以初始值就不像之前的算法那样重要了。而1e-8指一个比较小的数,用来保证分母非0。
其含义是,对于每个参数,随着其更新的总距离增多,其学习速率也随之变慢。
7.4.2 AdaDelta (Adaptive Delta)
关键优点:1) 解决了AdaGrad Learning Rate单调递减的问题。 (是AdaGrad的扩展)
2) 不需要设置默认的Learning Rate
RMS(Root Mean Squared) : 均方根
Adagrad算法存在三个问题:
1)其学习率是单调递减的,训练后期学习率非常小2)其需要手工设置一个全局的初始学习率
3)更新W时,左右两边的单位不同
Adadelta针对上述三个问题提出了比较漂亮的解决方案。
7.4.3 RMSprop
RMSprop是由Geoff Hinton设计的。RMSprop与AdaDelta的目的一样:解决AdaGrad的Learning Rate逐步消失的问题。
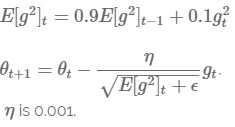
7.4.4 Adam (Adaptive Moment Estimation)
Adam的目的是:为每个参数计算自适应的Learning Rate。

其实际效果与AdaDelta、RMSProp相比,毫不逊色!
7.5 优化算法效果可视化
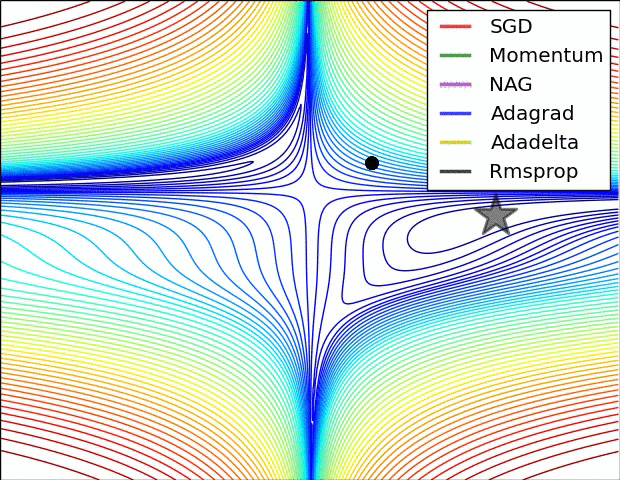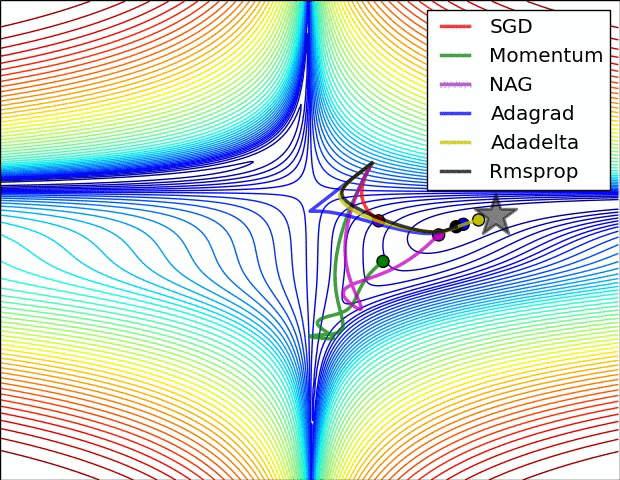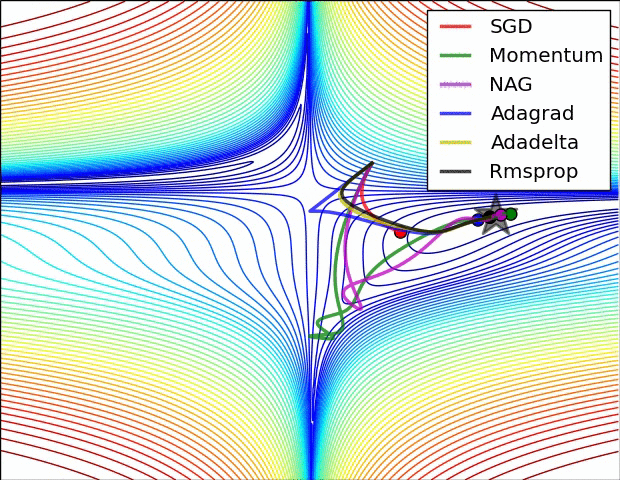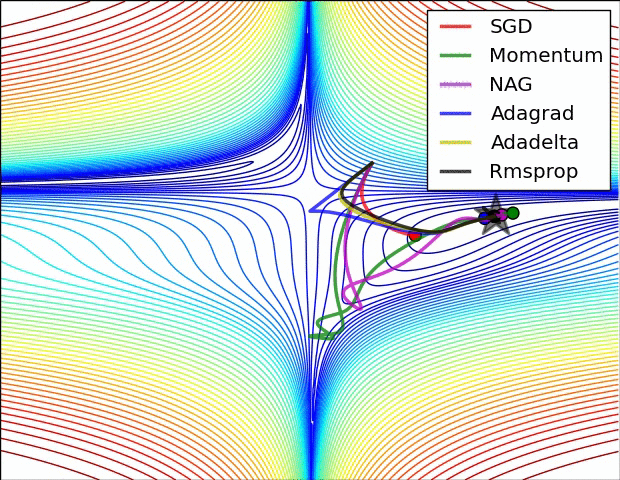
SGD optimization on Beale's function
SGD optimization on Long Valley
SGD optimization on Saddle Point
7.6 如何选择优化算法
1)总结:
- RMSprop是AdaGrad的扩展,以解决learning rate逐步消失的问题
- RMSprop与AdaDelta相比,AdaDelta在分子更新规则中使用了参数RMS更新,其它相同
- Adam与RMSprop相比,增加了偏差校正和动量
- RMSprop、AdaDelta和Adam是非常类似的算法,在类似的环境下,效果相当
- 从整体上看,Adam目前是最好的选择
2)如果输入数据是稀疏的(sparse),使用adaptive learning-rate(AdaGrad、AdaDelta、RMSprop、Adam)可以获得最好的结果,且不需要调整learning rate;
3)如果你关心快速收敛,你应当选择adaptive learning-rate方法
7.7 优化SGD的其它策略
7.7.1 Shuffling and Curriculum Learning
1)Shuffling:每次迭代前,随机打乱训练样本的顺序
2)Curriculum Learning:把训练样本按某种有意义的方式进行排序,对逐步解决困难问题有效。
7.7.2 批量归一化Batch Normalization (BN)
为了便于训练,我们经常归一化参数的初始值,通过mean=0, variance=1的高斯分布来初始化参数。在训练过程中,我们不同程度地更新参数,使用参数失去了归一化,这将降低训练速度且放大变化,网络越深问题越严重。
BN为每一个mini-batch重建归一化参数。使模型结构的部分进行归一化,我们可以使用更高的learning rate,且参数初始化要求没哪么高。
此外,BN还作为一个正则化(Regularizer),可以减少或避免使用Dropout。
正则化(Regularizer):是一个用于解决过拟合(Overfitting)问题的一种技术。具体实现方法是在损失函数中增加惩罚因子(参数向量的范数,1范数(L1)或2范数(L2))lambda*N(w)。
7.7.3 早期停止(Early Stopping)
在训练时,总是监视验证集的错误率,如果验证集的错误率不能得到改善,应当停止训练。
8. Regularization: Dropout
在前向计算时,随机设置一些神经元的值为0,如下图所示:
示意代码如下:
p = 0.5 # probability of keeping a unit active, higher = less dropout
def train_step(X)
""" X contains the data """
# forward pass for example 3-layer neural network
H1 = np.maximum(0, np.dot(W1, X) + b1)
M1 = np.random.rand(*H1.shape) < p # first dropout mask
H1 *= M1 # drop
H2 = np.maximum(0, np.dot(W2, H1) + b2)
M2 = np.random.rand(*H2.shape) < p # send dropout mask
H2 *= M2 # drop
out = np.dot(W3,H2) + b3 相当于训练多个模型,一个dropout mask对应一个模型,且这些模型共享参数。
在测试时,不需要dropout, 直接计算每层的激活值,然后进行scale作为本层最终输出的激活值,其代码如下:
def predict(X):
# ensembled forward pass
H1 = np.maxmium(0, np.dot(W1,X)+b1) * p # Note: scale the activations
H2 = np.maxmium(0, np.dot(W2,H1)+b2) * p # Note: scale the activations
out = np.dot(W3,H2) + b3