购物网站的推荐算法-个性化推荐算法中如何处理买了还推
1. 引言
目前在工业界推荐中广泛使用的协同过滤算法(Collaborative Filtering)主要分为user-based和item-based两种类型,user-based多用于挖掘那些有共同兴趣的小团体;而item-based侧重于挖掘item之间的关系,然后根据用户的历史行为来为用户生成推荐列表。相比item-based,user-based方法推荐的新颖性好一些,但是准确性差,而item-based 的方法应用更为广泛。item-based的CF在使用过程中经常被诟病会经常推荐最近购买过商品的类似商品。这是因为用户对最近购买的商品以及相似商品有较多的历史行为(点击,加购,购买),CF在推荐的时候对这部分商品相关联的商品会给予较高的权重。常用的处理方法是对推荐列表中与用户近期购买过的商品的叶子类目相同的商品进行过滤,根据具体需求可以选择对应的购买时间区间以及过滤白名单。这种处理方法有着明显的弊端:
- 用户购买过的商品并不是所有都需要过滤,即使需要过滤相对应的过滤购买周期也是不尽相同的。比如用户购买一件T恤后很有可能会第二天继续购买一件T恤,在购买一箱牛奶后可能要过一个月后再买一箱牛奶,而在购买一个冰箱后可能要过好几年才会再置换冰箱。相对应的我们在推荐时候不需要对T恤进行过滤,对牛奶则应该选择在三个星期内进行过滤,而对冰箱则很可能需要一直过滤。统一的购买时间区间以及过滤白名单都不能很好解决上述问题。
- 单纯对用户近期购买的商品的叶子类目进行过滤在很多情况没法很好的解决用户体验问题,比如用户购买了一件连体泳衣,相应的推荐结果会出现较多分体泳衣的召回。仅仅对连体泳衣的叶子类目进行过滤并不能过滤掉分体泳衣的召回,仍然会对用户特别是高端用户的体验造成较大的困扰。
用户的购买决策往往会受到很多主观因素和客观因素的影响。近几年也有不少的研究工作将用户的购买时序考虑进推荐过程中并验证可以有效提高推荐效果。用户购买商品后对其他的商品购买影响可能是正向的影响,也可能是负向的影响,比如用户在购买完一个手机以后,对购买相似推荐的其他手机的意图会明显下降,而对搭配推荐的手机壳的购买则会明显提升。本文主要针对相似推荐中买了还推的情况进行分析,提出算法来解决常用处理方法会出现的弊端。
2. 算法介绍
相似推荐中买了还推的问题的本质是要研究用户购买商品A后对与商品A相似的商品 A+ A+的购买意图变化。我认为其中有两个关键的问题是我们首先需要解决的:
- 如何准确的衡量用户购买商品A后对相似商品 A+ A+的购买意图变化?
- 如何获取用户购买商品A后的购买意图发生变化的相似商品 A+ A+的集合S?
下面的内容主要是围绕这两个问题展开来讨论。
2.1 购买意图变化衡量
假设用户购买商品A的时间点为0,则我们需要衡量的是用户在购买商品A后在时间点y对 A+ A+的第一次进行购买的概率,这里第一次进行购买表明用户在时间点y前未购买 A+ A+。survival analysis经常被用来对一个事件发生的时间区间进行建模,这里我们也使用survival analysis来对上述条件概率进行估计。
2.1.1 survival analysis
survival analysis是一个在统计学中研究比较多的topic,在经济以及可靠性分析领域有着不少的应用。它其中很重要的一部分就是用来预测一个事件发生的时间,比如说一台机器什么时候会出错或者一位病人什么时候无法延续生命。这里我们可以用它来预测用户在什么时间会购买商品。在基本的survival analysis中有一个假设是当时间趋于无穷,时间总会发生,比如说一台机器总是会出错,一个病人总有一天会总结他的生命。对应到我们的问题,它其实假定当时间趋于无穷,用户在购买商品A后肯定会购买 A+ A+。survival analysis有一个很重要的hazards function。假设 p(y) p(y)是一件事件发生的时间分布概率密度函数,T是一个代表事件发生时间的随机变量, P(y)=Pr(T≤y) P(y)=Pr(T≤y)是相对应的累积分布函数,则survival function SU(y)=Pr(T>y)=1−P(y) SU(y)=Pr(T>y)=1−P(y),相对应的hazards函数则为
它的物理意义是表示事件在时间点y之前未发生而在时间点y瞬时发生的概率。对应到买了还推的问题上它表示用户在购买商品A后在时间点y之前未购买相似商品 A+ A+而在时间点y购买 A+ A+的概率,也正是我们需要估计的。
2.1.2 hazards 函数
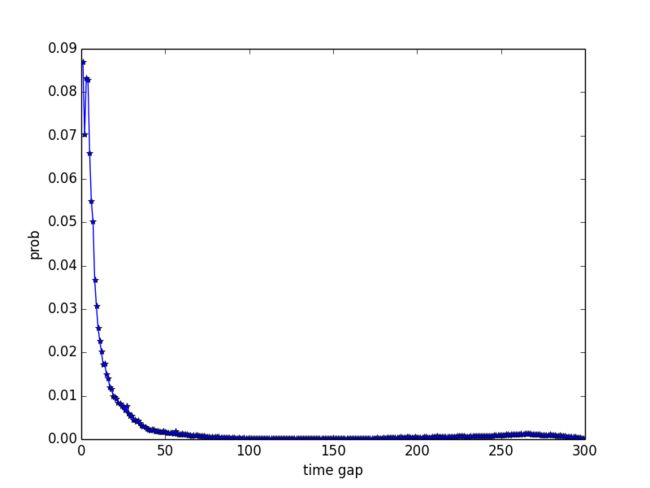
我们首先需要估计用户在购买A后购买 A+ A+的时间分布概率密度函数 p(y) p(y)。一个很直接的想法是用所有购买过A且后续购买了 A+ A+的用户在不同时间点上的人数分布来估计。为了避免两个商品之间的数据的稀疏性,我们考虑用户购买集合S中商品后续再购买集合S中商品在不同时间点的人数分布。这里我们采用同一叶子类目商品集合作为S。这样我们可以得到相应的概率分布曲线 p(y,S) p(y,S),进而得到相应的 h(y,S) h(y,S)。以保暖上装这一叶子类目为例,对应的 p(y,S) p(y,S)如下:
对应的 h(y,S) h(y,S)曲线如下
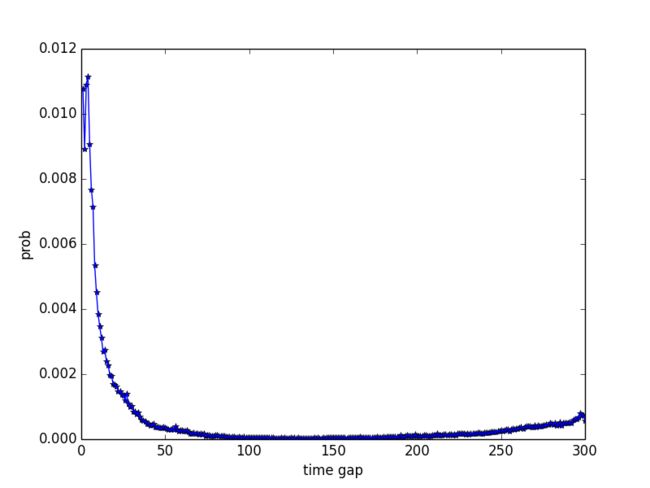
可以看到它的时间分布概率曲线是一个很明显的类power law曲线。大部分重复购买了保暖上装的用户都是在上次购买保暖上装后较短时间内进行了购买,而在购买250到300天后再购买的用户很少。保暖上装具有很明显的季节性,用户一般都会选择在来年的秋冬季节再进行购买,因而购买250到300天后再购买的用户从常识上来说不应该这么少。那是什么原因导致结果与预期的结果有比较大的出入呢?
这是因为我们在进行统计估计时只拿到用户在淘宝和天猫上的购买记录,而用户很多时候并不一定会选择在淘宝和天猫上进行购买。以保暖上装为例,很多用户会选择直接去商场或者去其他购物网站进行购买。而用户在短期内会在淘宝或天猫上再购买很大程度是受上次在淘宝或天猫购买的记忆留存影响。当时间逐渐推移,这种记忆留存的影响也会逐渐衰减,对用户的购买的影响也会逐渐衰弱。这种情况在survival analysis中被称为censoring,表示未观测到的数据。我们对hazards函数进行估计时需要将这部分数据的影响考虑进去。
2.1.3 用户购买记忆函数
为了进行修正,我们引入用户u在时间点y对集合S(叶子类目)的购买记忆函数 m(u,y,S) m(u,y,S),主要由两部分组成:
其中 md(S) md(S)用来表示只与集合S相关的用户默认的购买记忆, 描述一个普遍意义上的用户在购买集合S的商品时会想起到淘宝或者天猫上进行购买的潜在可能性。 mu(u,y,S) mu(u,y,S)则是用来表示用户u在y时间点对在淘宝或者天猫上购买集合S的商品的购买记忆。
我们使用下面的公式来估计 md(S) md(S) ,即
其中 N(A) N(A)表示购买了A商品的用户数, NT(A+) NT(A+)表示这些购买了A商品的用户在很长的时间段T(一年)内也购买了 A+ A+的用户数。针对不同商品或者类目而言,用户默认的购买记忆并不一样,比如食品类的类目估计值比家电类的类目估计值要大。
针对 mu(u,y,S) mu(u,y,S),考虑到用户记忆留存会随时间衰减的性质,我们使用指数分布来进行估计。假设用户u在时间点y0,y1,y2分别购买了集合S内的商品,对于用户的每次购买的购买记忆曲线可以使用一个指数分布曲线来近似,如下图
则用户u在时间点y的购买记忆可以估计为
其中 Yy Yy表示用户u在时间点y之前购买的时间点集合, λ λ是指数分布的rate参数
2.1.4 模型修正
我们可以使用用户u在时间点y对集合S的购买记忆函数 m(u,y,S) m(u,y,S)来对原始的hazards函数进行修正,有
其中L(u,y,S)是表示用户u在时间点y是否购买集合S中商品的指示函数,当发生购买时值为1,否则为0. t代表在时间点y之前的时间点。 ∑um(u,y,S)−∑t∑uL(u,y,S) ∑um(u,y,S)−∑t∑uL(u,y,S)的含义表示在y时刻对网站尚有记忆且在y时刻前未购买集合S中商品的用户数,与原始模型相比剔除了在y时刻之前已经遗忘的用户。
仍然以保暖上装为例,修正后的保暖上衣叶子类目的hazards函数曲线如下:

可以看到修正后的曲线在200天后有明显的上扬的趋势,与我们预期相符合。
再看比如糖果叶子类目,它对应的hazards函数曲线如下:
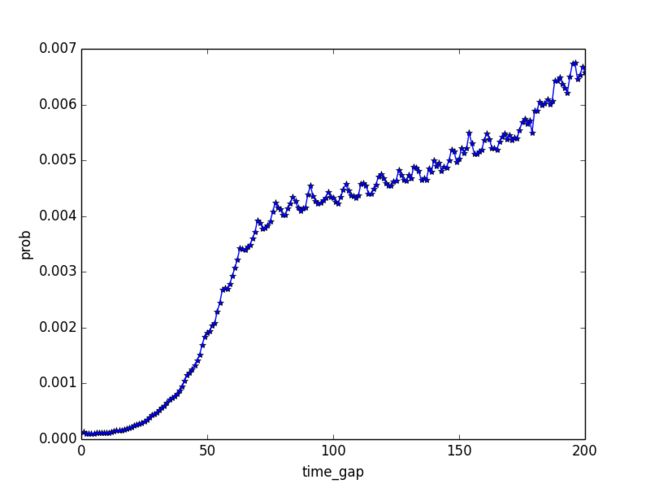
可以看到用户在购买糖果后再购买糖果的概率在差不多一个多月内逐渐上升,上升较快,在之后趋于稳定,这也是与我们预期相符的。糖果叶子类目曲线后端的略微上扬是因为我们只统计了有限时间内的时间点的分布,会导致曲线在最后可能出现波动。
因此给定一个类目和一个时间点,我们就可以得到一个用户在这个时间点会重复购买这个类目的商品的概率。
2.2 相似商品集合S获取
在上面的讨论中,我们一直将相似商品集合S设定为同一叶子类目的商品。但这个设定如引言中所提到的在特定情况下无法满足我们的需求,例如购买了连体泳衣也需要将分体泳衣过滤掉。为了解决这个问题,我们需要获取与购买叶子类目相似,购买会受到影响的叶子类目集合LS。这里提供两个思路来获取LS。
-
我们已经有了i2i的数据(例如牛逼的swing i2i),可以将item对应到它的叶子类目得到c2c的数据。假设 catea catea2c的记录集合为A, cateb cateb2c的记录集合为B,则 catea catea和 cateb cateb的jaccard相似度可以定义为
sim(catea,cateb)=|catea2cateb||A∪B| sim(catea,cateb)=|catea2cateb||A∪B|
这种方法的缺点是会出现较多的搭配类目,需要设置较高的相似度阈值以及一些规则对这些搭配类目进行过滤。(可以参考wl_ind.lsh_cate2cate_sim_list) -
受到搭配类目可以通过买了还买的行为来进行获取的启发,我们也可以寄希望于通过挖掘用户的行为来获取购买相似类目。但不同于搭配类目,用户对购买相似类目采取的是买了不买的行为,而这种不买的行为并没有被显示的记录下来,所以我们需要从用户的其他相关行为来间接的猜出用户的这种倾向。一般用户在购买商品前会在购物车中加购相似的商品,并且在购买完该商品后会将购物车中与该商品相似的商品删除。这种删除购物车商品的行为的机会成本还是很高的,可以近似的用来表示用户不买的行为倾向。我们可以用下面的公式来计算 catea catea和 cateb cateb的相似度
sim(catea,cateb)=N(ca,cb)N(ca)∗N(cb)−−−−−−−−−−−√ sim(catea,cateb)=N(ca,cb)N(ca)∗N(cb)其中 N(ca,cb) N(ca,cb)表示用户在购买 cateb cateb的商品后删除购物车 catea catea商品的次数, N(ca) N(ca)表示用户删除购物车 catea catea商品的总次数。在计算 N(ca,cb) N(ca,cb)时可以考虑时间因素的影响,对相邻时间较远的事件赋予较低的权重,比如可以加上一个时间衰减的因子。
这种方法相较于第一种方法的优点是搭配类目出现的较少,缺点是如果不限制两个叶子类目为相同一级类目情况下会出现较多的噪音。(可以参考wl_ind.lsh_cart_buy_cat_sim)
实际使用的时候可以将上面两种方法综合起来进行使用。
3. 实验论证
3.1 有好货瀑布流实验
在有好货的瀑布流的实验中对推荐的u2i原始的购买过滤逻辑进行了优化,根据用户在购买后特定时间再购买的概率来判定是否对购买的叶子类目进行过滤,同时引入购买相似类目信息解决可能出现的过滤不彻底的现象。从人工review case的情况来看推荐结果的用户体验得到较大提升,线上实验也验证对成交有约3%的提升。
3.2 母婴行业瀑布流实验
在热门市场的母婴行业瀑布流的实验中基准桶未采取任何购买过滤,对照实验桶对实时i2i进行再购买概率的rerank后截断。对应于基准桶,实验桶推荐结果的主观体验得到了较大改善,对应的千次展现alipay平均有约2%的提升。