机器学习中的数学系列-概率与统计
1,基本概念
(1)期望
\( E(X)=\sum_i{x_ip_i} \)
------------------- important ----------------
E(kX) = kE(X)
E(X+Y) = E(X)+E(Y)
当X和Y相互独立:E(XY)=E(X)E(Y) (这个不能反向推哦)
-----------------------------------------------
(2)方差
\( D(X)=\sum_i{(x_i-E(X))^2p_i} \)
从这个式子可以看出方差是变量与随机变量差值平法的期望,它表征的是随机变量的波动情况。
还有另外一个:\( D(X)=E(X^2)-E^2X \) 这个很简洁,也很常用
------------------- important ----------------
D(c) = 0
D(X+c) = D(X)
D(kX) = k2D(X)
如果X与Y相互独立:D(X+Y) = D(X)+D(Y)
-----------------------------------------------
(3)协方差
\( COV(X,Y)=E[(X-E(X))(Y-E(Y))] \)
协方差是两个随机变量X和Y具有相同方向变化趋势的度量。当Cov(X,Y)=0的时候,X和Y不相关,大于0正相关,小于0负相关。
Pearson相关系数:
\( \rho_{XY}=\frac{COV(X,Y)}{\sqrt{D(X)}\sqrt{D(Y)}} \)
这是-1到+1之间的值,-1表示线性负相关,0不相关,+1表示线性正相关。
协方差矩阵:
随机变量X1,X2....Xn,协方差矩阵\( c_{ij}=Cov(X_i,X_j) \)
------------------- important ----------------
Cov(X,Y) = Cov(Y,X)
Cov(aX+b,cY+d)=acCov(X,Y)
Cov(X1+X2,Y) = Cov(X1,Y)+Cov(X2,Y)
Cov(X,Y) = E(XY) - E(X)E(Y),可见,当X和Y独立时,Cov(X,Y)=0
------------------------------------------------
这里有关于相关性的东东:《这里是链接》
(4)矩
随机变量的k阶原点矩为:\( E(X^k) \)
随机变量的k阶中心矩为:\( E{[X-E(X)]^k} \)
期望是一阶原点矩,方差是二阶中心矩
2,重要分布
(1)两点分布
随机变量X的分布律为
X 1 0
p 1-p
E(X) = p
D(X) = p(1-p)
(2)二项分布
二项分布由 n 个独立且相同的伯努利试验产生,其中 p 为每一次试验成功的概率。二项分布的概率函数为:
\( f(x;n,p) = \binom{n}{x}p^x(1-p)^{n-x} \)
E(X) = np
D(X) = np(1-p)
简单的推导:
\( X = \sum{X_i}\)
\( E(X) = \sum{E(X_i)} = np \)
\( D(X) = \sum{D(X_i)} = np(1-p) \) 因为x1,x2..xn相互独立,所以方差满足线性关系
(3)泊松分布
泊松分布是探讨某一事件在某段时间或空间发生的次数的概率分布。泊松分布的概率函数为:
\(f(x;\lambda) = \frac{\lambda^x}{x!}{e^{-\lambda}} (x=0,1,2...., \lambda>0) \)
\( E(X)=\lambda \)
\( D(X)=\lambda \)
它是二项分布的极限形式(当n趋近于无穷,p趋近于0,np趋近于\(\lambda\))。
当一个随机事件,以固定的平均瞬时速率\( \lambda \)随机且独立的出现时,那么这个事件在单位事件内出现的次数或个数就近似的服从泊松分布,可以总结为:
1. 事件随机地发生于某段时间或空间内
2. 某一刻中,事件最多只会发生一次
3. 事件以一常数率 λ 发生于某段时间或空间内
4. 事件之间独立地发生
生活总符合泊松分布的案例:
1,汽车站台的候车人数
2,电话交换机接到呼叫的次数
3,机器发生故障的次数
4,自然灾害的次数
5,一油站在一分钟内汽车抵达的数目
6,一本书内某一页的错字数目
....
(4)均匀分布
随机变量X~U(a,b),其概率密度为
f(x) =
1/(b-a), a<x<b
0,others
E(X) = (a+b)/2
D(X) = (b-a)2/12
(5)指数分布
概率密度函数为:
\( E(X)=\theta \)
\( D(X)=\theta^2\)
(6)正态分布
\( X\~N(\nu,\sigma^2) \),其概率密度函数为:
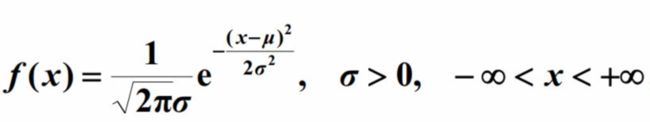
\(E(X)=\nu\)
\(D(X)=\sigma^2\)
3,重要定理
(1)Jesen不等式

需要注意条件,pi大于0,p1+p2+...+pn=1,以及f是凸函数。
如果把pi看作概率,那么得到f(E(X))<=Ef(X)
(2)切比雪夫不等式

切比雪夫不等式说明任意一个数据集中,位于其平均数m个标准差范围内的比例(或部分)总是至少为1-1/㎡,其中m为大于1的任意正数。
(3)大数定理
随机变量X1,X2...Xn相互独立,并且具有相同的期望和方差,Yn为这N个随机变量的均值,那么对于任意整数epsilon有:
![]()
大数定理说明在n无限大的时候,随机变量的均值无限接近于期望。
还有一个伯努利定理,它说明事件A的发生频率na/n以概率收敛于事件A的概率p。