Java中的序列化
主要谈一谈Java中的序列化问题,包括Serializable与Externalizable介绍以及一些项目中的用法。
1、序列化是什么意思?用来干嘛的
序列化:将对象的状态信息转换为可以存储或传输的形式的过程。不过存储倒是很少见,工作中大多都是传输。比如远程
方法调用就是用到的特别多。差不多就相当于科幻片中的那种将固体液化,顺着水管流到某个地方然后在固化。那么液化的过
程就是类似于序列化,固化的过程就是反序列化。
通常开发人员只需要了解被序列化的类需要实现 Serializable 接口,使用 ObjectInputStream 和 ObjectOutputStream 进行
对象的读写。然而在有些情况下,光知道这些还远远不够。
因为,你的眼界决定了项目的高度!
2、Java中提供的默认序列化Serializable
我们先写一个User类,然后主要通过代码说明下。User类的主要结构如下,主要就三个字段,id,name,passwd
package com.ztesoft.ser;
public class User {
private int id;
private String name;
private String passwd;
public int getId() {
return id;
}
public void setId(int id) {
this.id = id;
}
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public String getPasswd() {
return passwd;
}
public void setPasswd(String passwd) {
this.passwd = passwd;
}
}
接着我们写个测试类,将这个对象序列化到磁盘中
@Test
public void serializWrite(){
User user = new User(1, "dgh", "123456");
File file = new File("D:/user.info");
ObjectOutputStream oos = null;
try {
oos = new ObjectOutputStream(new FileOutputStream(file));
oos.writeObject(user);
} catch (Exception e) {
e.printStackTrace();
} finally {
IOUtils.closeQuietly(oos);
}
}接着就报了一个异常:
java.io.NotSerializableException: com.ztesoft.ser.User
所以我们得到第一个结论:如果使用默认的序列化,则需要序列化的对象就需要直接或者间接的实现Serializable接口。
现在我们给User类添加接口实现,然后在调用方法,则正常运行。User这个对象被序列化到硬盘上了。但是有个警告:
下面就主要说说这个序列化ID。
2.1、序列化ID的问题 serialVersionUID
有一个异常叫做:java.io.InvalidClassException: stream classdesc serialVersionUID = 5835067920559730690,
local class serialVersionUID = 583506792055970690这个异常发生在反序列化的时候,
为什么有这个异常呢?
因为:虚拟机是否允许反序列化,不仅取决于类路径和功能代码是否一致,一个非常重要的一点是两个类的序列化 ID 是
否一致(就是 private static final long serialVersionUID = 1L)。由于序列化 ID 不同,他们无法相互序列化和反序列化。也
就导致了上面类似的异常抛出。
序列化 ID 在 Eclipse 下提供了两种生成策略,一个是固定的 1L,一个是随机生成一个不重复的 long 类型数据(实际上
是使用 JDK 工具生成),在这里有一个建议,如果没有特殊需求,就是用默认的 1L 就可以,这样可以确保代码一致时反序
列化成功。那么随机生成的序列化 ID 有什么作用呢,
有些时候,通过改变序列化 ID 可以用来限制某些用户的使用。比如:
修改了服务端类的序列化id之后,只有与服务端保持一致序列化id的那些客户端才能调用。不过一般没有人这么做。
2.2、静态变量的序列化
第一步:我们修改User,添加一个成员变量。就叫做state吧,static修饰的哦。
第二步:写一个测试类,先序列化到硬盘,在反序列化到回来但是发现了一个严重问题:

这是为什么呢?对于无法理解的读者认为,state 是从读取的对象里获得的,应该是保存时的状态才对啊,我保存的时
候是error那么序列化回来应该也是error,为什么就成了ok了呢?之所以变成ok的原因在于序列化时,并不保存静态变量,
这其实比较容易理解,序列化保存的是对象的状态,静态变量属于类的状态,因此 序列化并不保存静态变量。
2.3、父类序列化与transient关键字
我们先说一下transient关键字,我们在passwd字段前面加上这个关键字修饰,然后在反序列化回来
很神奇吧,passwd应该是123456的,但是这里却没有了。
其实transient这个关键字的作用就是使字段不被序列化。
我们熟悉使用 Transient 关键字可以使得字段不被序列化,那么还有别的方法吗?根据父类对象序列化的规则,我们可以
将不需要被序列化的字段抽取出来放到父类中,子类实现 Serializable 接口,父类不实现,根据父类序列化规则,父类的
字段数据将不被序列化。所以父类序列化的代码就不演示了。
2.4、对敏感字段的加密
我们可不可以有什么办法自定义序列化的方式呢?比如序列化时给字段加密,这样别人也不容易破解了。其实是有的:
在序列化过程中,虚拟机会试图调用对象类里的 writeObject 和 readObject 方法,进行用户自定义的序列化和反序列化。
如果没有这样的方法,则默认调用是 ObjectOutputStream 的 defaultWriteObject 方法以及 ObjectInputStream 的
defaultReadObject 方法。用户自定义的 writeObject 和 readObject 方法可以允许用户控制序列化的过程,比如可以在
序列化的过程中动态改变序列化的数值。基于这个原理,可以在实际应用中得到使用,用于敏感字段的加密工作。
修改User代码,添加两个方法:
writeObject 和readObject
private void writeObject(ObjectOutputStream out) {
try {
// 这里可以加密
out.writeObject(passwd);
} catch (IOException e) {
e.printStackTrace();
}
}
private void readObject(ObjectInputStream in) {
try {
// 这里就可以解密了
passwd = (String) in.readObject();
} catch (Exception e) {
e.printStackTrace();
}
}之后我们调用测试方法,发现结果是:
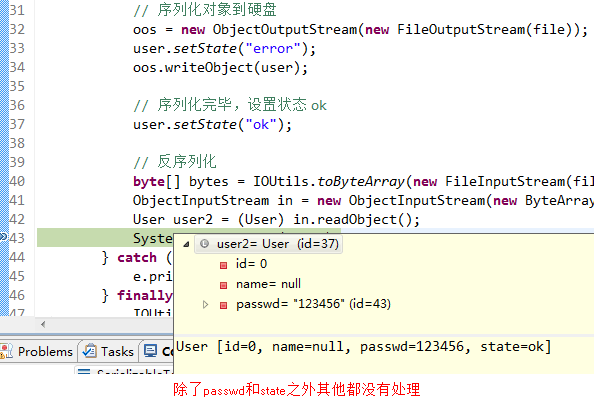
state因为是静态的,有值是正常的,id与name因为我们自定义的方法中么有处理,因此就没有值。也就是说如果我们写了
writeObject与readObject,那么序列化与反序列话就会使用我们自定义的方法。
RMI 技术是完全基于 Java 序列化技术的,服务器端接口调用所需要的参数对象来至于客户端,它们通过网络相互传输。这就
涉及 RMI 的安全传输的问题。一些敏感的字段,如用户名密码(用户登录时需要对密码进行传输),我们希望对其进行加密,
这时,就可以采用本节介绍的方法在客户端对密码进行加密,服务器端进行解密,确保数据传输的安全性。
2.6、单例模式与序列化
第一步:首先写一个单例类
package com.ztesoft.ser;
public class Singleton implements java.io.Serializable {
/** */
private static final long serialVersionUID = 780762366800963430L;
public static Singleton INSTANCE = new Singleton();
// 私有构造器
private Singleton() { }
}第二步:写个测试方法,测试一下看看结果
public void singletonTest(){
Singleton s1 = Singleton.INSTANCE;
File file = new File("D:/singleton.info");
ObjectOutputStream oos = null;
ObjectInputStream ois = null;
try {
// 序列化对象到硬盘
oos = new ObjectOutputStream(new FileOutputStream(file));
oos.writeObject(s1);
// 反序列化
byte[] bytes = IOUtils.toByteArray(new FileInputStream(file));
ObjectInputStream in = new ObjectInputStream(new ByteArrayInputStream(bytes));
Singleton s2 = (Singleton) in.readObject();
System.out.println(s1 == s2);
} catch (Exception e) {
e.printStackTrace();
} finally {
IOUtils.closeQuietly(oos);
IOUtils.closeQuietly(ois);
}
}
第三步:发现控制台输出的是false,也就是说单例类被破坏了。
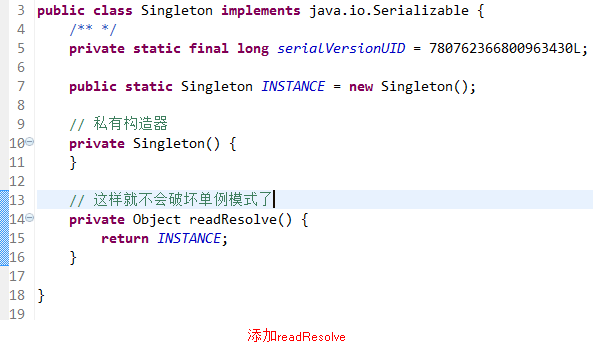
为了避免这中情况,我们需要在需要序列化的类中添加一个方法
readResolve:
这个时候在跑一下测试代码,看看是否有问题
3、Externalizable接口的使用
jdk还给我们提供了另外一种自定义序列化的借口。那就是Externalizable啦,首先我们看看源码:
public interface Externalizable extends java.io.Serializable {
void writeExternal(ObjectOutput out) throws IOException;
void readExternal(ObjectInput in) throws IOException, ClassNotFoundException;
}
这个接口继承了Serializable接口,并有两个方法,一个write一个read。其实和我们的readObject与writeObject一样的啦。
个人觉得只是更方便了而已,有兴趣可以研究下他们之间的差别。我是没研究。
4、题外话
java虽然提供了很好的序列化,但是序列化之后的文件还是比较大的。目前很多开源的项目为了提高效率都使用更好的
替代方法,比如protobuf等。以后有机会在介绍这个东西吧。