JAVA容器
容器位于java.util包内
Java容器类库的用途是保存对象,根据数据结构不同将其划分为两个不同的概念
(1) Collection,一个独立元素的序列,其中List按照元素的插入顺序保存元素,而set不能有重复元素,Queue(队列)按照先进先出(FIFO)的方式来管理数据,Stack(栈)按照后进先出(LIFO)的顺序管理数据。
(2) Map,一组键值对(key-value)对象的序列,可以使用key来查找value,其中key是不可以重复的,value可以重复。我们可以称其为字典或者关联数组。其中HashMap是无序的,TreeMap是有序的,WeakHashMap是弱类型的,Hashtable是线程安全的。
容器API的类图结构如图:

Collection接口
--定义了存取一组对象的方法,其子接口Set和List分别定义了存储方式。
示例:
- import java.util.*;
- public class TestCollection{
- public static void main(String[] args){
- Collection c=new ArrayList();
- //可以放入不同类型的对象
- c.add("hello");
- c.add(new Name("f1","l1"));
- c.add(new Integer(100));
- System.out.println(c.size());
- System.out.println(c);
- }
- }
- class Name{
- private String firstName,lastName;
- public Name(String firstName,String lastName){
- this.firstName=firstName;
- this.lastName=lastName;
- }
- public String getFirstName(){
- return firstName;
- }
- public String getLastName(){
- return lastName;
- }
- public String toString(){
- return firstName+" "+lastName;
- }
- }

Set接口:
Set接口是Collection的子接口,Set接口没有提供额外的方法,但实现Set接口的容器类中的元素是没有顺序的,而且不可以重复。
- import java.util.*;
- public class TestSet{
- public static void main(String[] args){
- Set s1=new HashSet();
- Set s2=new HashSet();
- s1.add("a");
- s1.add("b");
- s1.add("c");
- s2.add("d");
- s2.add("a");
- s2.add("b");
- Set sn=new HashSet(s1);
- //sn中与s2相同的
- sn.retainAll(s2);
- Set su=new HashSet(s1);
- //所有的
- su.addAll(s2);
- System.out.println(sn);
- System.out.println(su);
- }
- }

List接口:
List接口是Collection的子接口,实现List接口的容器类中的元素是有顺序的,而且可以重复。List容器中的元素都对应一个整数型的序号记载其在容器中的位置,可以根据序号存取容器中的元素。
次序是List最重要的特点;它确保维护元素特定的顺序。List为Collection添加了许多方法,使得能够向List中间插入与移除元素(只推荐 LinkedList使用)。
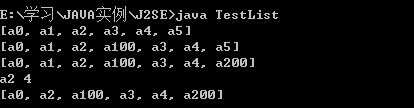
- import java.util.*;
- public class TestList{
- public static void main(String[] args){
- List l1=new LinkedList();
- for(int i=0;i<=5;i++){
- l1.add("a"+i);
- }
- System.out.println(l1);
- l1.add(3,"a100");
- System.out.println(l1);
- l1.set(6,"a200");
- System.out.println(l1);
- System.out.print((String)l1.get(2)+" ");
- System.out.println(l1.indexOf("a3"));
- l1.remove(1);
- System.out.println(l1);
- }
- }
Map接口
定义了存储“键(key)-值(value)映射对”的方法
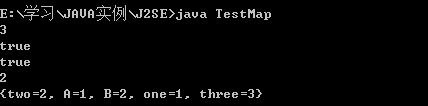
- import java.util.*;
- public class TestMap{
- public static void main(String args[]){
- Map m1=new HashMap();
- Map m2=new TreeMap();
- m1.put("one",new Integer(1));
- m1.put("two",new Integer(2));
- m1.put("three",new Integer(3));
- m2.put("A",new Integer(1));
- m2.put("B",new Integer(2));
- System.out.println(m1.size());
- System.out.println(m1.containsKey("one"));
- System.out.println(m2.containsValue(new Integer(1)));
- if(m1.containsKey("two")){
- int i=((Integer)m1.get("two")).intValue();
- System.out.println(i);
- }
- Map m3=new HashMap(m1);
- m3.putAll(m2);
- System.out.println(m3);
- }
- }
Iterator接口:
所有实现了Collection接口的容器类都有一个iterator方法用以返回一个实现了Iterator接口的对象。
Iterator对象称作迭代器,用以方便的实现对容器内元素的遍历操作。
- import java.util.*;
- public class TestIterator{
- public static void main(String[] args){
- Collection c=new HashSet();
- c.add(new Name("f1","l1"));
- c.add(new Name("f2","l2"));
- c.add(new Name("f3","l3"));
- Iterator i=c.iterator();
- while (i.hasNext()){
- //next()的返回值为Object类型,需要转换为相应类型
- Name n=(Name)i.next();
- System.out.println(n.getFirstName()+" ");
- }
- }
- }
- class Name{
- private String firstName,lastName;
- public Name(String firstName,String lastName){
- this.firstName=firstName;
- this.lastName=lastName;
- }
- public String getFirstName(){
- return firstName;
- }
- public String getLastName(){
- return lastName;
- }
- public String toString(){
- return firstName+" "+lastName;
- }
- }

数组和容器类的区别:
效率、类型限定和对于基本类型的处理。
1,效率肯定是内建的数组效率更高一些。数组是一种高效的存储和随机访问对象引用序列的方式,使用数组可以快速的访问数组中的元素。但是当创建一个数组对象 ( 注意和对象数组的区别 ) 后,数组的大小也就固定了,当数组空间不足的时候就再创建一个新的数组,把旧的数组中所有的引用复制到新的数组中。,
2,在泛型出来之前,容器类都是存取Object,而数组规定了确定类型。
3,在自动封包解包前,容器类不支持基本类型,而数组支持。
泛型:
起因:类型不明确
装入集合的类型都被当做Object对待,从而失去自己的实际类型
从集合中取出时往往需要转型,效率底,容易产生错误
解决办法:
在定义集合的时候同时定义集合中对象的类型
1,可以在定义Collection的时候指定
2,也可以在循环时用Iterator指定
好处:增强程序的可读性和稳定性
- import java.util.*;
- public class BasicGeneric {
- public static void main(String[] args) {
- List<String> c = new ArrayList<String>();
- c.add("aaa");
- c.add("bbb");
- c.add("ccc");
- for(int i=0; i<c.size(); i++) {
- String s = c.get(i);
- System.out.println(s);
- }
- Collection<String> c2 = new HashSet<String>();
- c2.add("aaa"); c2.add("bbb"); c2.add("ccc");
- for(Iterator<String> it = c2.iterator(); it.hasNext(); ) {
- String s = it.next();
- System.out.println(s);
- }
- }
- }

总结:
以上只是简单介绍了容器的概念,以及各个容器类的特点和使用范例,对于容器类和数组来说,一般情况下,考虑到效率与类型检查,应该尽可能考虑使用数组。如果要解决一般化的问题,数组可能会受到一些限制,这时可以使用Java提供的容器类。
Comparable接口:针对排序list
问题:上面的算法根据什么确定容器中对象的“大小”顺序?
所有可以“排序”的类都实现了java.lang.Comparable接口,Comparable接口中只有一个方法
Publicint compareTo(Object obj)
返回0:表示this==obj
返回正数:表示this>obj
返回负数:表示this<obj
实现了Comparable接口的类通过实现comparaTo方法从而确定该对象的排序方式
equals()与hashCode():保证不重复
由来:
要想保证元素不重复,可两个元素是否重复应该依据什么来判断呢?这就是Object.equals方法了。但是,如果每增加一个元素就检查一次,那么当元素很多时,后添加到集合中的元素比较的次数就非常多了。也就是说,如果集合中现在已经有1000个元素,那么第1001个元素加入集合时,它就要调用1000次equals方法。这显然会大大降低效率。
于是,Java采用了哈希表的原理。哈希算法也称为散列算法,是将数据依特定算法直接指定到一个地址上。
这样一来,当集合要添加新的元素时,先调用这个元素的hashCode方法,就一下子能定位到它应该放置的物理位置上。如果这个位置上没有元素,它就可以直接存储在这个位置上,不用再进行任何比较了;如果这个位置上已经有元素了,就调用它的equals方法与新元素进行比较,相同的话就不存了,不相同就散列其它的地址。所以这里存在一个冲突解决的问题。这样一来实际调用equals方法的次数就大大降低了,几乎只需要一两次。
规则:
所以,Java对于eqauls方法和hashCode方法是这样规定的:
1.如果两个对象相同,那么它们的hashCode值一定要相同;
2.如果两个对象的hashCode相同,它们并不一定相同(这里说的对象相同指的是用eqauls方法比较)。如不按要求去做了,会发现相同的对象可以出现在Set集合中,同时,增加新元素的效率会大大下降。
3.equals()相等的两个对象,hashcode()一定相等;equals()不相等的两个对象,却并不能证明他们的hashcode()不相等。
在object类中,hashcode()方法是本地方法,返回的是对象的地址值,而object类中的equals()方法比较的也是两个对象的地址值,如果equals()相等,说明两个对象地址值也相等,当然hashcode()也就相等了;
在String类中,equals()返回的是两个对象内容的比较,当两个对象内容相等时Hashcode()方法根据String类的重写代码的分析,也可知道hashcode()返回结果也会相等。
以此类推,可以知道Integer、Double等封装类中经过重写的equals()和hashcode()方法也同样适合于这个原则。当然没有经过重写的类,在继承了object类的equals()和hashcode()方法后,也会遵守这个原则。
总结:
hashCode()方法被用来获取给定对象的唯一整数。这个整数被用来确定对象被存储在HashTable类似的结构中的位置。默认的,Object类的hashCode()方法返回这个对象存储的内存地址的编号。 hashCode()和equals()定义在Object类中,这个类是所有java类的基类,所以所有的java类都继承这两个方法。
如果我们不重写这两个方法,将几乎不遇到任何问题,但是有的时候程序要求我们必须改变一些对象的默认实现。
举例说明:
- public class TestString{
- public static void main(String[] args){
- String s1="Hello";
- String s2="World";
- String s3="Hello";
- System.out.println(s1 == s3);
- s1=new String("hello");
- s2=new String("hello");
- System.out.println(s1 == s2);
- System.out.println(s1.equals(s2));
- }
- }

以上的正确执行是因为我们已经默认重写了String类的equals()方法和hashCode()方法。但是如果是Object类呢?
- import java.util.HashSet;
- import java.util.Set;
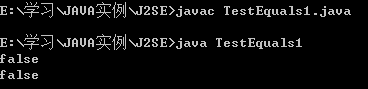
- public class TestEquals1{
- public static void main(String[] args){
- Cat cl=new Cat(1,2,3);
- Cat c2=new Cat(1,2,3);
- System.out.println(cl==c2);
- System.out.println(cl.equals(c2));
- }
- }
- class Cat{
- int color,height,weight;
- public Cat(int color,int height,int weight){
- this.color=color;
- this.height=height;
- this.weight=weight;
- }
- }
- public class TestEquals{
- public static void main(String[] args){
- Cat cl=new Cat(1,2,3);
- Cat c2=new Cat(1,2,3);
- System.out.println(cl==c2);
- System.out.println(cl.equals(c2));
- }
- }
- class Cat{
- int color,height,weight;
- public Cat(int color,int height,int weight){
- this.color=color;
- this.height=height;
- this.weight=weight;
- }
- public boolean equals(Object obj){
- if(obj==null)return false;
- else{
- if(obj instanceof Cat){
- Cat c=(Cat)obj;
- if(c.color==this.color && c.height==this.height && c.weight==this.weight){
- return true;
- }
- }
- }
- return false;
- }
- }

So are we done?没有,让我们换一种测试方法来看看。
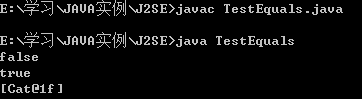
上面的程序输出的结果是两个。如果两个cat对象equals返回true,Set中应该只存储一个对象才对,而且System.out.println(cat.contains(newCat(1,2,3)));判断是否存在时,结果输出为false,如图:
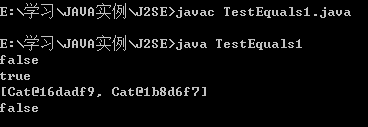
那么问题在哪里呢?
我们忘掉了第二个重要的方法hashCode()。就像JDK的Javadoc中所说的一样,如果重写equals()方法必须要重写hashCode()方法。我们加上下面这个方法,程序将执行正确。
- public int hashCode()
- {
- final int PRIME =31;
- int result = 1;
- result = PRIME * result ;
- return result;
- }
再总结:
以上这些都是针对容器来说的(如何判断set中不重复,如何判断list中的顺序),当然最主要的是解释为什么重写equals()方法必须要重写hashCode()方法的问题。
根据一个类的equals方法(改写后),两个截然不同的实例有可能在逻辑上是相等的,但是,根据Object.hashCode方法,它们仅仅是两个对象。因此,违反了“相等的对象必须具有相等的散列码”。
所以只要重写了equals(),一定要重写hashCode,否则Hash表都会失效,工作不正常。即便你用equals方法比较得到两个对象是相等的结论那你也得不到相同的哈希码
即如果cat类只重写了equals(),hashcode没有被重写,加入元素时使用的hashcode()是继承于set<-collection<-object的,所以计算的hashcode值不同,存储位置不同,则认为元素不相同,也就能明白为什么上面的判断是否存在(System.out.println(cat.contains(newCat(1,2,3))))时输入的结果为false了。