HDFS 联盟(HDFS Federation)
背景
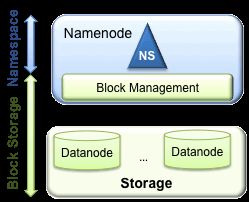
多NameNode/NameSpace
为了水平扩展,联盟使用多个独立的Namenodes/namespaces。这些NameNode之间是相连的,即Namenodes是独立的,不需要互相协调。DataNode被所有的NameNode使用用来作为通用的数据块存储设备。每一个DataNode注册集群中所有的NameNode。Datanodes发送心跳和block报告并且处理NameNode发送的命令。

ClusterID
一个新的标示ClusterID用来标示集群当中所有的节点。当一个Namenode被格式化,这个标识符或自动生成的。这个ID会被用来格式化集群中的其他Namenode。
关键的好处
Namespace扩展性-HDFS集群可以通过水平扩展但是namespace不行。大型部署或者是小文件较多的系统可以通过向集群添加更多的NameNode获益。
性能-之前的架构中文件系统的吞吐量收单一NameNode限制。添加更多的NameNode会提高读写的吞吐量
隔离 - 一个NameNode无法隔离多用户环境,实验的程序可能造成Namenode变慢,影响生产环境,多个Namenodes使得不同类别的应用程序和用户可以分离不同的名称空间。
配置
联合配置是向后兼容,允许现有的单一Namenode配置工作,不会有任何改变。新的配置被设计成集群当中的所有节点拥有着相同的配置并且并不需要为不同的机器设置不同的配置文件。
联盟中添加了一个新的抽象NameServiceID。Namenode以及对应的Secondary/backup/checkpointer节点都属于这个。支持单个配置文件,Namenode以及对应的econdary/backup/checkpointer配置参数通过NameServiceID后缀标示,并可以添加到同样的配置文件当中。
配置
第一步:添加下面的配置到你的配置文件当中:
dfs.nameservices: 配置与逗号分隔NameServiceIDs列表
这是为了Datanodes用来确定集群中的所有Namenodes。
第二步:为每一个Namenode以及Secondary/backup/checkpointer节点添加后缀为对应的NameServiceID的配置到通用配置文件:
| Daemon | Configuration Parameter |
|---|---|
| Namenode | dfs.namenode.rpc-address dfs.namenode.servicerpc-address dfs.namenode.http-address dfs.namenode.https-address dfs.namenode.keytab.file dfs.namenode.name.dirdfs.namenode.edits.dir dfs.namenode.checkpoint.dir dfs.namenode.checkpoint.edits.dir |
| Secondary Namenode | dfs.namenode.secondary.http-address dfs.secondary.namenode.keytab.file |
| BackupNode | dfs.namenode.backup.address dfs.secondary.namenode.keytab.file |
下面是一个两个namenode的简单配置例子:
<configuration>
<property>
<name>dfs.nameservices</name>
<value>ns1,ns2</value>
</property>
<property>
<name>dfs.namenode.rpc-address.ns1</name>
<value>nn-host1:rpc-port</value>
</property>
<property>
<name>dfs.namenode.http-address.ns1</name>
<value>nn-host1:http-port</value>
</property>
<property>
<name>dfs.namenode.secondaryhttp-address.ns1</name>
<value>snn-host1:http-port</value>
</property>
<property>
<name>dfs.namenode.rpc-address.ns2</name>
<value>nn-host2:rpc-port</value>
</property>
<property>
<name>dfs.namenode.http-address.ns2</name>
<value>nn-host2:http-port</value>
</property>
<property>
<name>dfs.namenode.secondaryhttp-address.ns2</name>
<value>snn-host2:http-port</value>
</property>
.... Other common configuration ...
</configuration>
格式化NameNode
> $HADOOP_PREFIX_HOME/bin/hdfs namenode -format [-clusterId <cluster_id>]
选择一个不同的cluster_id,保证不会和其他的集群冲突,如果不提供的话,他会自动生成一个不同的ClusterID
第二步: 格式化添加的namenode,可以用下面的命令:
> $HADOOP_PREFIX_HOME/bin/hdfs namenode -format -clusterId <cluster_id>
注意:第二步使用的cluster_id不行要和第一步相同,如果不相同的话,添加的Namenode将不会在联邦集群中起作用
升级到0.23版本之后并且配置联邦
早期的版本只能支持单一的Namenode,下面的步骤可以是联邦可用:
第一步:升级集群。在升级过程中你一个提供一个ClusterID:
> $HADOOP_PREFIX_HOME/bin/hdfs start namenode --config $HADOOP_CONF_DIR -upgrade -clusterId <cluster_ID>
如果不提供那么会自动生成。
添加一个新的NameNode到一个既存的HDFS集群
按照以下步骤:
添加配置参数dfs.nameservices到配置文件
使用NameServiceID 作为后缀更新配置文件。配置的key名字已经和0.20不一致了,必须使用新的配置参数名
添加新的NameNode相关配置到配置文件当中
将配置文件同步到集群当中的所有节点
启动新的Namenode, Secondary/Backup节点
刷新datanode获取新添加的namenode,使用下列命令:
> $HADOOP_PREFIX_HOME/bin/hdfs dfadmin -refreshNameNode <datanode_host_name>:<datanode_rpc_port>在集群中所有的datanodes运行上面的命令
管理集群
启动停止集群
> $HADOOP_PREFIX_HOME/bin/start-dfs.sh停止:
> $HADOOP_PREFIX_HOME/bin/stop-dfs.sh这些命令可以在在HDFS运行的任何节点运行。命令将确定namenode并且启动这些namenode。datanode是通过slaves文件指定的。脚本可以作为参考来构建自己启动和停止集群的脚本。
平衡器
"$HADOOP_PREFIX"/bin/hadoop-daemon.sh --config $HADOOP_CONF_DIR --script "$bin"/hdfs start balancer [-policy <policy>]Policy:
"$HADOOP_PREFIX"/bin/distributed-exclude.sh <exclude_file>第二步:刷新所有NameNode使用新的 exclude文件
"$HADOOP_PREFIX"/bin/refresh-namenodes.sh上面的命令将使用HDFS配置文件确定集群的 Namenode,使用新的exclude文件刷新所有的Namenode。