webcrawler-----自制爬虫搜索种子和电影(jsoup)
文章来源:开源中国社区http://www.oschina.net/code/snippet_778875_48198
自制的爬虫可以抓取网上的电影和种子,设置爬虫的深度足够可以爬取所有的资源。这里以163开始并无大碍,以任何一个好点的网站开始都是可以的。
需要的jar包:
IKAnalyzer2012FF_u1.jar
jsoup-1.8.2.jar
lucene-core-4.10.2.jar
lucene-highlighter-5.1.0.jar
目录中生成的文件,如下图所示:
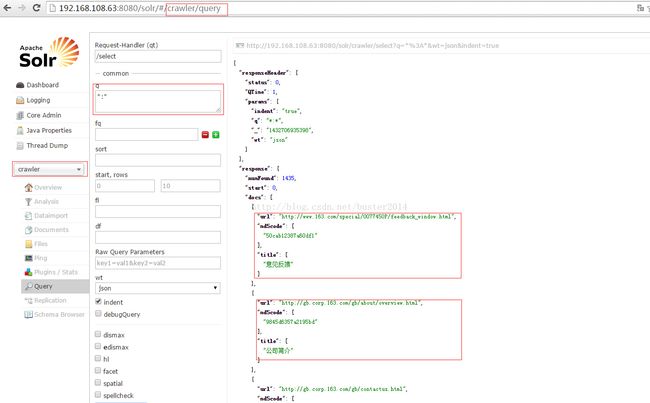
把目录中生成的文件全部导入到sor4.7.2中利用solr的web管理界面可以进行检索,检索结果如下图所示:
java代码如下所示:
package tzj;
import java.io.File;
import java.io.IOException;
import java.io.StringReader;
import java.security.MessageDigest;
import java.security.NoSuchAlgorithmException;
import java.util.ArrayList;
import java.util.Iterator;
import java.util.List;
import java.util.Stack;
import java.util.regex.Matcher;
import java.util.regex.Pattern;
import org.apache.lucene.analysis.Analyzer;
import org.apache.lucene.analysis.TokenStream;
import org.apache.lucene.document.Document;
import org.apache.lucene.document.Field.Store;
import org.apache.lucene.document.TextField;
import org.apache.lucene.index.DirectoryReader;
import org.apache.lucene.index.IndexReader;
import org.apache.lucene.index.IndexWriter;
import org.apache.lucene.index.IndexWriterConfig;
import org.apache.lucene.index.Term;
import org.apache.lucene.search.IndexSearcher;
import org.apache.lucene.search.Query;
import org.apache.lucene.search.ScoreDoc;
import org.apache.lucene.search.TermQuery;
import org.apache.lucene.search.TopDocs;
import org.apache.lucene.search.highlight.Highlighter;
import org.apache.lucene.search.highlight.InvalidTokenOffsetsException;
import org.apache.lucene.search.highlight.QueryScorer;
import org.apache.lucene.search.highlight.SimpleHTMLFormatter;
import org.apache.lucene.store.FSDirectory;
import org.apache.lucene.util.QueryBuilder;
import org.apache.lucene.util.Version;
import org.jsoup.Connection;
import org.jsoup.Connection.Response;
import org.jsoup.helper.HttpConnection;
import org.jsoup.nodes.Element;
import org.jsoup.select.Elements;
import org.wltea.analyzer.lucene.IKAnalyzer;
public class PTest {
File dirc=new File("dirc2");
//当前层的URL
Stack<String[]> stackcurt=new Stack<String[]>();
//下一层的URL和名称
Stack<String[]> stacknext=new Stack<String[]>();
//控制递归层数
final int deep=6;
Analyzer analyzer=new IKAnalyzer();
FSDirectory directory;
IndexWriterConfig config;
IndexWriter indexWriter;
final String userAgent="Mozilla/5.0 (Windows NT 6.1; WOW64) "
+ "AppleWebKit/537.36 (KHTML, like Gecko) Chrome/38.0.2125.101 Safari/537.36";
public PTest(){
try {
directory=FSDirectory.open(dirc);
config=new IndexWriterConfig(Version.LATEST, analyzer);
indexWriter=new IndexWriter(directory, config);
config.setMaxBufferedDocs(10);
} catch (IOException e) {
e.printStackTrace();
}
}
public static void main(String[] args) throws IOException{
PTest pTest=new PTest();
String starturl="http://www.163.com";
pTest.startWork(starturl);
System.out.println(pTest.search("妻子"));
// System.out.println(
// pTest.isIndexed("http://www.9amhg.com/?intr=806"));
}
/** 使用方式并不是递归得到URL,而是逐层解析。
* 得到页面内容
* @param url
* @param deep
*/
public void getPageContent(String[] urlname){
Connection connection=HttpConnection.connect(urlname[0]);
connection.ignoreContentType(true);
connection.ignoreHttpErrors(true);
connection.userAgent(userAgent);
connection.referrer(urlname[2]);
org.jsoup.nodes.Document document=null;
Response response=null;
boolean store=false;
//如果本身就是资源就直接索引
if(isResource(urlname[0])){
store=true;
}else
{
try {
response=connection.execute();
//如果这个链接返回的是视频就直接索引
if(isMP4(response.contentType()))
store=true;
else
{
document = response.parse();
}
} catch (IOException e) {
e.printStackTrace();
}
}
try {
indexPageContent(urlname[0],urlname[1],store);
} catch (IOException e) {
e.printStackTrace();
}
if(document!=null){
Elements elements=document.getElementsByTag("a");
Iterator<Element> iterator=elements.iterator();
while(iterator.hasNext()){
Element element=iterator.next();
String attrurl=element.attr("href");
attrurl=processUrl(attrurl, urlname[0]);
try {
if(!isIndexed(attrurl))
stacknext.push(new String[]{attrurl,element.text(),urlname[0]});
} catch (IOException e) {
e.printStackTrace();
}
}
}
}
/**
* 还原url链接
* @param url
* @param parenturl
* @return
*/
public String processUrl(String url,String parenturl){
Pattern pattern_host=Pattern.compile("http://\\w+\\.\\w+\\.\\w+");
Matcher matcher_host=pattern_host.matcher(parenturl);
String host=null;
if(matcher_host.find())
host=matcher_host.group();
if(host==null)
return url;
if(url.startsWith("/"))
return host+url;
else if(url.startsWith("../")){
while(url.startsWith("../")){
url=url.substring(3);
parenturl=parenturl.substring(0, parenturl.lastIndexOf("/")-1);
parenturl=parenturl.substring(0, parenturl.lastIndexOf("/"));
}
return parenturl+"/"+url;
}
return url;
}
/**
* 判断返回类型是不是视频
* @param contenttype
* @return
*/
public boolean isMP4(String contenttype){
if(contenttype.startsWith("video")){
return true;
}
return false;
}
/**
* 判断这个链接是不是资源
* @param url
* @return
*/
public boolean isResource(String url){
//添加资源识别的种类
if(url.endsWith(".mp4")
||url.endsWith(".torrent")){
return true;
}
return false;
}
/**
* 开始工作
* @param urls
*/
public void startWork(String...urls){
int deep=1;
for (int i = 0; i < urls.length; i++) {
stackcurt.push(new String[]{urls[i],"",""});
}
while(this.deep>deep)
{
if(stackcurt.isEmpty())
{
stackcurt=stacknext;
stacknext=new Stack<String[]>();
deep++;
}
if(stackcurt.isEmpty())
break;
try {
getPageContent(stackcurt.pop());
} catch (RuntimeException e) {
//e.printStackTrace();
}
}
}
/**
* 索引链接
* @param url
* @throws IOException
*/
public void indexPageContent(String url,String title,boolean store) throws IOException{
System.out.println("索引"+url+"\t"+title);
Document document=new Document();
document.add(new TextField("url",url,Store.YES));
document.add(new TextField("md5code",md5(url),Store.YES));
document.add(new TextField("title", title,Store.YES));
indexWriter.addDocument(document);
indexWriter.commit();
}
/**
* 关键字分组
* @param content
* @return
*/
public boolean setGroup(String content){
return false;
}
/**
* 判断URL是不是已经被索引过了
* @param url
* @return
* @throws IOException
*/
public boolean isIndexed(String url) throws IOException{
if(!directory.fileExists("segments.gen"))
return false;
IndexReader indexReader= DirectoryReader.open(directory);
IndexSearcher indexSearcher=new IndexSearcher(indexReader);
TermQuery query=new TermQuery(new Term("md5code", md5(url)));
TopDocs docs= indexSearcher.search(query, 1);
return docs.scoreDocs.length>0?true:false;
}
/**
* 查询
* @param keyword
* @return
* @throws IOException
*/
public List<String> search(String keyword) throws IOException{
IndexSearcher indexSearcher=new IndexSearcher(DirectoryReader.open(directory));
Query booleanQuery=
new QueryBuilder(analyzer).createBooleanQuery("title", keyword);
TopDocs docs=indexSearcher.search(booleanQuery, 10);
List<String> urls=new ArrayList<String>();
Highlighter highlighter=new Highlighter(new SimpleHTMLFormatter(),new QueryScorer(booleanQuery));
ScoreDoc[] docss=docs.scoreDocs;
if(docs!=null&&docss.length>0){
for (int i = 0; i < docss.length; i++) {
Document document=indexSearcher.doc(docss[i].doc);
urls.add(document.get("url"));
TokenStream tokenStream = analyzer.tokenStream("title", new StringReader(document.get("title")));
try {
String str = highlighter.getBestFragment(tokenStream, document.get("title"));
System.out.println(str);
} catch (InvalidTokenOffsetsException e) {
e.printStackTrace();
}
System.out.println("\t"+document.get("url")+"\t"+document.get("title")+"\t");
System.out.println("\n");
}
}
return urls;
}
/**
* MD5 加密
* @param plainText
* @return
*/
public static String md5(String plainText) {
try {
MessageDigest md = MessageDigest.getInstance("MD5");
md.update(plainText.getBytes());
byte b[] = md.digest();
int i;
StringBuffer buf = new StringBuffer();
for (int offset = 0; offset < b.length; offset++) {
i = b[offset];
if (i < 0)
i += 256;
if (i < 16)
buf.append("0");
buf.append(Integer.toHexString(i));
}
return buf.toString().substring(8, 24);
} catch (NoSuchAlgorithmException e) {
e.printStackTrace();
}
return null;
}
}