CUDA的BLAS数学库
刚刚从C++博客迁徙过来,原来的那么多东西要拷贝要粘贴图片要重新上传真是累。看过的朋友可不要骂小弟灌水![]()
注:本文的代码图片资料选自NVIDIA CUDAProgramming Guide,原作者保留所有著作权。
NVIDIA近日终于发布了CUDA,有可能作为下一代SDK10的一部分奉送给乐于发掘GPU计算能力的专业人员。感兴趣的朋友可以去这里一探究竟,下载尝鲜,提供了大量的范例。
我们都知道,GPU的并行运算性能是极为强悍的,如此丰富的计算资源如果浪费着不用,就用来跑跑游戏是远远不行的。而传统的图形API又单单的只提供了图形操作的功能,没有提供类似于CPU那样通用计算的接口,所以说以往的方法都是很麻烦而且需要相当的经验的 —— 比如用HDR图片作Cube Map的时候,如果使用的是Paul提供的那种类似于经纬图的纹理,就需要大量的反三角函数的计算,而用Vertex Shader作反三角又太浪费时间,于是人们用1D纹理作线性插值查找表进行快速计算(访问数据纹理)。这个例子也可以看作是最基本的GPU计算。
CUDA的诞生
使用传统API进行计算是个不可挽回的错误,CUDA的出现将改变这一状况。CUDA主要在驱动程序方面和函数库方面进行了扩充。在CUDA库中提供了标准的FFT与BLAS库,一个为NVDIA GPU设计的C编译器。CUDA的特色如下,引自NVIDIA的官方说明:
1、为并行计算设计的统一硬件软件架构。有可能在G80系列上得到发挥。
2、在GPU内部实现数据缓存和多线程管理。这个强,思路有些类似于XB360 PS3上的CPU编程。
3、在GPU上可以使用标准C语言进行编写。
4、标准离散FFT库和BLAS基本线性代数计算库。
5、一套CUDA计算驱动。
6、提供从CPU到GPU的加速数据上传性能。瓶颈就在于此。
7、CUDA驱动可以和OpenGL DirectX驱动交互操作。这强,估计也可以直接操作渲染管线。
8、与SLI配合实现多硬件核心并行计算。
9、同时支持Linux和Windows。这个就是噱头了。
看过了宣传,您可以看一下CUDA提供的Programming Guide和其他的文档。NVIDIA我觉得有些类似图形界的Microsoft,提供精良的装备诸如SDK和开发文档等等,比ATi好多了。
CUDA本质
CUDA的本质是,NVIDIA为自家的GPU编写了一套编译器NVCC极其相关的库文件。CUDA的应用程序扩展名可以选择是.cu,而不是.cpp等。NVCC是一个预处理器和编译器的混合体。当遇到CUDA代码的时候,自动编译为GPU执行的代码,也就是生成调用CUDA Driver的代码。如果碰到Host C++代码,则调用平台自己的C++编译器进行编译,比如Visual Studio C++自己的Microsoft C++ Compiler。然后调用Linker把编译好的模块组合在一起,和CUDA库与标准C\C++库链接成为最终的CUDA Application。由此可见,NVCC模仿了类似于GCC一样的通用编译器的工作原理(GCC编译C\C++代码本质上就是调用cc和g++)。NVCC有着复杂的选项,详情参阅CUDA SDK中的NVCC相关文档。
CUDA编程概念
Device
CUDA API提供接口枚举出系统中可以作为计算设备使用的硬件为计算进行初始化等操作。类似于DX编程中的初始化COM接口。
Texture
线性内存中的数据和数组中的数据都可以作为纹理使用。不过数组在缓存层面上更适合优化。纹理的概念类似于传统的图像纹理,可以以8 16 32位的整数储存,也可以用fp16格式进行储存。而且当把数组转换为纹理的时候,还有一些有点,比如整数与fp16数字可以选择统一的转换到32bit浮点数,还可以使用数组边界这个特性,还可以进行过滤操作。
OpenGL/DirectX Interoperability
OpenGL的帧缓冲与DirectX9的顶点缓冲可以被映射到CUDA可操作的地址空间中,让CUDA读写帧缓冲里面的数据。不过CUDA Context一次只能操作一个Direct3D设备。当前CUDA还不支持对DX10进行类似的操作,除了DX9顶点缓冲也不允许进行映射,而且一次只能映射一次。(这个地方NVIDIA没有说清楚,我估计是指只有一个Mapping Slot)
Thread Block
A thread block is a batch of threads that can cooperate together by efficiently sharing data through some fast shared memory and synchronizing their execution to coordinate memory accesses.
ThreadBlock由一系列线程组成,这些线程可以快速共享内存,同步内存访问。每个线程都有个ID,这个ID好像平面坐标一般。线程组成Grid。示意图如下:
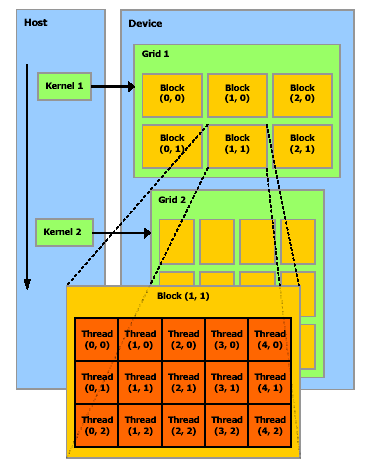
Memory Model
A thread that executes on the device has only access to the device’s DRAM and on-chip memory through the following memory spaces:
Read-write per-thread registers,
Read-write per-thread local memory,
Read-write per-block shared memory,
Read-write per-grid global memory,
Read-only per-grid constant memory,
Read-only per-grid texture memory.
The global, constant, and texture memory spaces can be read from or written to by the host and are persistent across kernel calls by the same application.
在CUDA中我们要接触到的内存主要有:寄存器,Local内存,Shared内存,Global内存,Constant内存,Texture内存。 有些类似于C内存的分配类型了。而且内存可以分配为数组或者是普通线性内存,CUDA提供API可以正确的进行内存拷贝等操作。
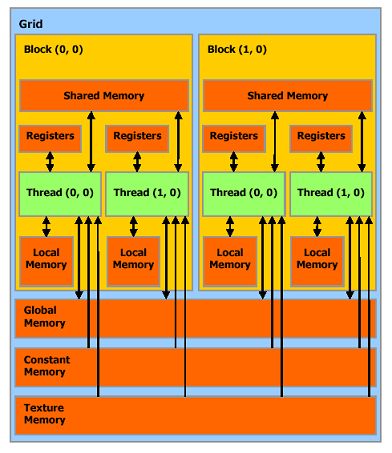
后面我们将谈到如何优化GPU内存。从上面的资料我们可以看出,这里的Grid概念类似于Process,也就是为线程执行分配资源的单元,而只有线程是真正计算的部分。Local Memory类似线程的栈。Texture Memory类似于堆内存区。
具体操作
我以CUDA附带的simpleCUBLAS作为例子。
#include <stdlib.h>
#include <string.h>
/* Includes, cuda */
#include "cublas.h"
/* Matrix size */
#define N (275)
/* Host implementation of a simple version of sgemm *///使用CPU进行Matrix乘法计算的算式
static void simple_sgemm(int n, float alpha, const float *A, const float *B,
float beta, float *C)
{
int i;
int j;
int k;
for (i = 0; i < n; ++i) {
for (j = 0; j < n; ++j) {
float prod = 0;
for (k = 0; k < n; ++k) {
prod += A[k * n + i] * B[j * n + k];
}
C[j * n + i] = alpha * prod + beta * C[j * n + i];
}
}
}
/* Main */
int main(int argc, char** argv)
{
cublasStatus status;
float* h_A;
float* h_B;
float* h_C;
float* h_C_ref;
float* d_A = 0;
float* d_B = 0;
float* d_C = 0;
float alpha = 1.0f;
float beta = 0.0f;
int n2 = N * N;
int i;
float error_norm;
float ref_norm;
float diff;
/* Initialize CUBLAS *///初始化CUBLAS库
status = cublasInit();
if (status != CUBLAS_STATUS_SUCCESS) {
fprintf (stderr, "!!!! CUBLAS initialization error\n");
return EXIT_FAILURE;
}
/* Allocate host memory for the matrices *///分配内存,这3个是257*257的大矩阵
h_A = (float*)malloc(n2 * sizeof(h_A[0]));
if (h_A == 0) {
fprintf (stderr, "!!!! host memory allocation error (A)\n");
return EXIT_FAILURE;
}
h_B = (float*)malloc(n2 * sizeof(h_B[0]));
if (h_B == 0) {
fprintf (stderr, "!!!! host memory allocation error (B)\n");
return EXIT_FAILURE;
}
h_C = (float*)malloc(n2 * sizeof(h_C[0]));
if (h_C == 0) {
fprintf (stderr, "!!!! host memory allocation error (C)\n");
return EXIT_FAILURE;
}
/* Fill the matrices with test data */
for (i = 0; i < n2; i++) {
h_A[i] = rand() / (float)RAND_MAX;
h_B[i] = rand() / (float)RAND_MAX;
h_C[i] = rand() / (float)RAND_MAX;
}
/* Allocate device memory for the matrices */ //在GPU设备上分配内存
status = cublasAlloc(n2, sizeof(d_A[0]), (void**)&d_A);
if (status != CUBLAS_STATUS_SUCCESS) {
fprintf (stderr, "!!!! device memory allocation error (A)\n");
return EXIT_FAILURE;
}
status = cublasAlloc(n2, sizeof(d_B[0]), (void**)&d_B);
if (status != CUBLAS_STATUS_SUCCESS) {
fprintf (stderr, "!!!! device memory allocation error (B)\n");
return EXIT_FAILURE;
}
status = cublasAlloc(n2, sizeof(d_C[0]), (void**)&d_C);
if (status != CUBLAS_STATUS_SUCCESS) {
fprintf (stderr, "!!!! device memory allocation error (C)\n");
return EXIT_FAILURE;
}
/* Initialize the device matrices with the host matrices */ //把HOST内的矩阵上传到GPU去
status = cublasSetVector(n2, sizeof(h_A[0]), h_A, 1, d_A, 1);
if (status != CUBLAS_STATUS_SUCCESS) {
fprintf (stderr, "!!!! device access error (write A)\n");
return EXIT_FAILURE;
}
status = cublasSetVector(n2, sizeof(h_B[0]), h_B, 1, d_B, 1);
if (status != CUBLAS_STATUS_SUCCESS) {
fprintf (stderr, "!!!! device access error (write B)\n");
return EXIT_FAILURE;
}
status = cublasSetVector(n2, sizeof(h_C[0]), h_C, 1, d_C, 1);
if (status != CUBLAS_STATUS_SUCCESS) {
fprintf (stderr, "!!!! device access error (write C)\n");
return EXIT_FAILURE;
}
/* Performs operation using plain C code */ //使用CPU进行矩阵乘法计算
simple_sgemm(N, alpha, h_A, h_B, beta, h_C);
h_C_ref = h_C;
/* Clear last error */
cublasGetError();
/* Performs operation using cublas */ //Wow !使用GPU计算
cublasSgemm('n', 'n', N, N, N, alpha, d_A, N, d_B, N, beta, d_C, N);
status = cublasGetError();
if (status != CUBLAS_STATUS_SUCCESS) {
fprintf (stderr, "!!!! kernel execution error.\n");
return EXIT_FAILURE;
}
/* Allocate host memory for reading back the result from device memory */ //分配HOST内存准备存放结果
h_C = (float*)malloc(n2 * sizeof(h_C[0]));
if (h_C == 0) {
fprintf (stderr, "!!!! host memory allocation error (C)\n");
return EXIT_FAILURE;
}
/* Read the result back */ //回读
status = cublasGetVector(n2, sizeof(h_C[0]), d_C, 1, h_C, 1);
if (status != CUBLAS_STATUS_SUCCESS) {
fprintf (stderr, "!!!! device access error (read C)\n");
return EXIT_FAILURE;
}
/* Check result against reference */
error_norm = 0;
ref_norm = 0;
for (i = 0; i < n2; ++i) {
diff = h_C_ref[i] - h_C[i];
error_norm += diff * diff;
ref_norm += h_C_ref[i] * h_C_ref[i];
}
error_norm = (float)sqrt((double)error_norm);
ref_norm = (float)sqrt((double)ref_norm);
if (fabs(ref_norm) < 1e-7) {
fprintf (stderr, "!!!! reference norm is 0\n");
return EXIT_FAILURE;
}
printf( "Test %s\n", (error_norm / ref_norm < 1e-6f) ? "PASSED" : "FAILED");
/* Memory clean up */
free(h_A);
free(h_B);
free(h_C);
free(h_C_ref);
status = cublasFree(d_A);
if (status != CUBLAS_STATUS_SUCCESS) {
fprintf (stderr, "!!!! memory free error (A)\n");
return EXIT_FAILURE;
}
status = cublasFree(d_B);
if (status != CUBLAS_STATUS_SUCCESS) {
fprintf (stderr, "!!!! memory free error (B)\n");
return EXIT_FAILURE;
}
status = cublasFree(d_C);
if (status != CUBLAS_STATUS_SUCCESS) {
fprintf (stderr, "!!!! memory free error (C)\n");
return EXIT_FAILURE;
}
/* Shutdown *///关闭CUBLAS卸载资源
status = cublasShutdown();
if (status != CUBLAS_STATUS_SUCCESS) {
fprintf (stderr, "!!!! shutdown error (A)\n");
return EXIT_FAILURE;
}
if (argc <= 1 || strcmp(argv[1], "-noprompt")) {
printf("\nPress ENTER to exit
getchar();
}
return EXIT_SUCCESS;
}
除了那些个容错的代码,我们可以看出使用CUBLAS库进行计算还是非常简洁直观的。详细的资料请看CUDA SDK自带的范例。
我的展望
ATi(AMD)坐不住的,应该会积极开发CPU与GPU融合的相关组建。
瓶颈在CPU - GPU带宽上,NV很有可能推出优化过的nForce芯片组提供高带宽。
用ICE配上CUDA组成分布式的GPU计算平台怎么样?!大伙不妨畅想畅想。
下一代BOINC计算平台内的项目能够提供基于GPU的计算客户端。
http://www.cnblogs.com/Jedimaster/archive/2007/02/28/660202.html