论文读书笔记-Using neural network to combine measures of word semantic similarity for image annotation
标题:Using neural network to combine measures of word semantic similarity for image annotation.
这篇论文是人工智能老师刘峡壁学生作品,正好和上课讲的内容相关,其中用到了神经网络,体现出了神经网络在解决问题时的优越性。
下面是摘抄的一些要点:
1、refine image annotation method
这里提到了对图像注释的改进,图像注释就是用一些词对一幅图进行描述,做到这一点就能对图像进行分类并且为搜索提供很大的方便。然而如何选择最接近图像的词是很难的,一般是通过比较关键词直接的语义实现。最主流的手段主要有以下三种: wordNet based, training data based, web search based.从单词意思就能推断出这些注释用词分别来自词库,训练集和网页搜索。当然,如果单单用一种方法效果很可能不是很好,往往是把这三种方法结合起来使用,而本文就是提出了一种结合的方法。
2、combining semantic similarity measures with FNN
首先解释FNN: feed-forward neural network.按照神经网络的表现形式,也分为输入层,隐含层,输出层。Each input neuron of the FNN receives a single measure of word-to-word similarity, and its output is the combined measure which is used to refine the image annotation within the Random Walker with Restarts (RWR) framework.其中提到的RWR就是带重启的随机游走框架,在这里对节点间的相似度进行衡量。文中用到的FNN一共三层,如下图:

3、Refining Image Annotation by RWR
这里包括两个阶段:
In the first stage, the probability of being each keyword for an image is computed by using some image content analysis technique.其中关键词按照可能性进行降序排列,选出最前面的N个作为输入。
In the second stage, the Random Walk with Restarts (RWR) algorithm is applied to refine the probability of each candidate annotation, where the semantic similarities between two keywords are measured by our FNN method.
做完这两步之后,再次按照可能性进行降序排列,排在最前面的N个关键词就是最终的待选注释,显然越靠前对图像的准确性描述越高。
RWR的算法如下:
In the RWR algorithm, the initial probabilities of all the keywords are considered as the restart vector Pi . Pi is normalized to ensure the sum of all elements in PI is one.
Starting from Pi , the algorithm is performed to reach the steady state probability vector Ps . Letα be the probability of restarting the random walk, Sw be the matrix of word-toword semantic similarities. Sw is column-normalized to ensure that the sum of each column in Sw is one. Then the steady state probability vector Ps satisfies the following equation:
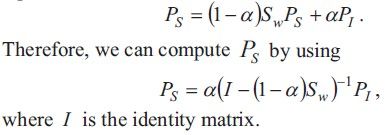
4、traning FNN with PSO
现在知道了处理步骤,但是有一点没有考虑,那就是FNN凭什么就能判断两个关键词的相似度,显然FNN是需要通过训练才能做到这一点,这一点和神经网络通过训练得到权重是一样的,FNN也是通过权重来判断相似度。这里使用的训练算法是PSO(particle swarm optimization)粒子群优化算法。训练过程如下:
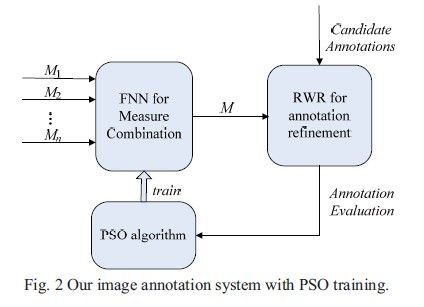
The position of each particle represents a possible FNN configuration, i.e., its weights. The fitness value of a particle is the accuracy evaluation of image annotation by using the corresponding FNN to measure word-to-word semantic similarities within the RWR framework.
明确了这一点,下面的内容和一般的粒子群优化算法一样,对positon和velocity进行修正,确保最终达到全局最优。直接截图:

算法步骤如下:
Step1. Generate a swarm of particles with random positions and velocities.
Step2. For each particle, perform the following steps:
Step2.1. Set the weights of the FNN according to the position of the particle.
Step2.2. Use the FNN to compute the matrix of semantic similarities between keywords.
Step2.3. Perform RWR to get the annotations for training images.
Step2.4. Evaluate the annotation accuracy and take the evaluation value as the fitness of the particle.
Step3. Record the best position of each particle and the globally best position of the swarm.
Step4. Update the position and velocity of each particle by using (3)-(4).
Step5. If a sufficiently good fitness or a maximum number of iterations is reached, then the algorithm stops, or else go to Step2.
5、image content analysis
既然提出了方法,最重要的自然是用实验验证该方法。首先,我们需要通过图像内容找出关键词,得到我们的候选集,然后再执行我们的方法。基于图像内容找到关键词是采用Max-Min Posterior Pseudo-probabilities (MMP) method.具体如下:
Firstly, an image is represented as an 80-D feature vector which consists of 9-D color moments and 71-D Gabor based texture features. We then assume that the feature vectors extracted from all images with the same keyword are of the distribution of Gaussian mixture model (GMM). Finally, the confidence of annotating the image with the keyword wi is computed as the posterior pseudoprobability which takes values in [0,1] and is defined as

然后可以进行比较:
Given a keyword C, let Ih be the set of images with ground-truth annotation C , Ia be the set of images annotated as C by our annotation algorithm, then the precision rate and the recall rate for keyword C are computed![]()
respectively. The average precision rate Ap and average recall rate AR over all the keywords are calculated. The consequent F1 for evaluating the image annotation accuracy is
通过实际数据比较,得出这种方法要比MNP加上某种单纯的方法好。
小结:这篇论文又是对某类方法的改进,其中加入了神经网络和群智能的一些知识,效果不错。显然,有些知识还是要学会使用,也许就是在某类难解的问题中加了一些别人都知道东西就能产出一篇优秀的论文,悟才是关键。